The vertices of a square are located at (0,4), (4,0), (0, -4) and (-4,0).
Select all transformations that will carry this square onto itself.
Answers

Related Questions
AnOtHeR MATH QUESTION (SMH). HELP PLEASE !!!

Answers
Answer:
For the function: \(g(x)=-x^2-3x+5\), the average rate of change of function over the interval \(-7\leq x\leq 2\) is 2
Step-by-step explanation:
We are given function: \(g(x)=-x^2-3x+5\), we need to find average rate of change of function over the interval \(-7\leq x\leq 2\)
The formula used is: \(Average \ rate \ of \ change=\frac{g(b)-g(a)}{b-a}\)
We have b=2 and a= -7
Finding f(b) and f(a)
Finding g(b) by putting x=2
\(g(x)=-x^2-3x+5\\g(2)=-(2)^2-3(2)+5\\g(2)=-4-6+5\\g(2)=-10+5\\g(2)=-5\)
Finding g(a) by putting x=-7
\(g(x)=-x^2-3x+5\\g(-7)=-(-7)^2-3(-7)+5\\g(-7)=-49+21+5\\g(-7)=-23\)
Now, finding average rate of change when g(b)=-5 and g(a)=-23
\(Average \ rate \ of \ change=\frac{g(b)-g(a)}{b-a}\\Average \ rate \ of \ change=\frac{-5-(-23)}{2-(-7)}\\Average \ rate \ of \ change=\frac{-5+23}{2+7}\\Average \ rate \ of \ change=\frac{18}{9}\\Average \ rate \ of \ change=2\)
So, Average rate of change = 2
Therefore for the function: \(g(x)=-x^2-3x+5\), the average rate of change of function over the interval \(-7\leq x\leq 2\) is 2
Based on this data, the difference in the dollar value of Assistantship (Stipend) between these two fields is how many standard errors away from the hypothesized difference?
t-Test : Two-sample assuming unequal variances
Assistantship (stipend) Assistantship arts (stipend) science
Mean 24041.62203 25952.36501
variance 621483.0801 615193.5853
observations 521 479
hypothesized mean different 0
df 992
t stat -38.39036076
P(T<=t) one tail 1.1775E-198
t critical one-tail 1.646391129
P(T<=t) two tail 2.3551E-198
t critical two-tail 1.962358258
Answers
The difference in the dollar value of Assistantship (Stipend) between art and science fields with standard errors is equal to 1.214.
Mean 24041.62203 25952.36501
Sample mean difference between Assistantship (stipend) in arts and science is equal to
= $25952.36501 - $24041.62203
= $1910.74298.
Hypothesized mean difference is 0 (there is no difference in stipend between the two fields).
Variance 621483.0801 615193.5853
Sample size 521 479
Standard error of the difference is,
=√[(variance in arts / sample size in arts) + (variance in science / sample size in science)]
= √[(615193.5853 / 479) + (621483.0801 / 521)]
= $49.77
t-statistic
= (sample mean difference - hypothesized mean difference) / standard error of the difference
Substitute the values into the t-statistic formula,
⇒ t-statistic = ($1910.74298 - 0) / $49.77
⇒ t-statistic = 38.39
t-critical value for a two-tailed test with 992 degrees of freedom at a significance level of 0.05 is 1.9624.
t-statistic (38.39) > t-critical value (1.9624)
⇒Reject the null hypothesis that there is no difference in stipend between the two fields.
standard errors
= t-statistic / √(sample size)
= 38.39 / √(479 + 521)
= 38.39 /31.62
=1.214
Therefore, the difference in the dollar value of Assistantship (Stipend) between these two fields is 1.214 standard errors away from the hypothesized difference.
learn more about standard errors here
brainly.com/question/16964784
#SPJ4
nine more than twice a number is is greater than negative eleven
Answers
The expression for nine more than twice a number is greater than negative eleven is 2M + 9 > -11.
Given,
Nine more than twice a number is greater than negative eleven.
We need to write an expression.
What do the mathematical terms mean?We have,
Twice of M = 2x M
Greater than = >
Negative of M = -M
3 more than M = M + 3
3 less than M = M - 3
We have,
Nine more than twice a number is greater than negative eleven.
Let the number be M.
Twice a number = 2M
Nine more than twice a number = 2M + 9
Greater than negative eleven = > -11
Now,
We have,
2M + 9 > -11
Thus the expression for nine more than twice a number is greater than negative eleven is 2M + 9 > -11.
Learn more about how to write an expression here:
https://brainly.com/question/17618748
#SPJ1
what can we conclude about the endogeneity of an explanatory variable if the ols and 2sls estimates are significantly different? assume that the instrument used was exogenous.
Answers
Note that assuming that the instrument used was exogenous, one can conclude about the endogeneity of an explanatory variable if the OLS and 2SLS estimates are significantly different: "The explanatory variable is endogenous and therefore 2SLS should be considered." (Option C)
What is 2SLS?Two-stage least squares (2SLS) regression analysis is a statistical approach used in structural equation analysis. The OLS approach has been extended using this methodology. It is employed when the error terms of the dependent variable are associated with the independent variables.
The ordinary least squares (OLS) approach is a linear regression methodology used to estimate a model's unknown parameters. The strategy is based on reducing the sum of squared residuals between the expected and actual values.
2SLS is utilized as an alternate strategy when we encounter endogeneity Problems in OLS. Endogeneity arises when the explanatory variable correlates with the error word. Then we utilize 2SLS, which employs an instrumental variable. The outcome will be different because if there is endogeneity in the model, OLS will produce biased results.
Learn more about OLS:
https://brainly.com/question/29834077
#SPJ1
Full Question:
What can we conclude about the endogeneity of an explanatory variable if the OLS and 2SLS estimates are significantly different? Assume that the instrument used was exogenous. Select one:
a. The explanatory variable is not endogenous and therefore using 2SLS is ill-advised.
b. The explanatory variable is not endogenous and therefore OLS should not be used.
c. The explanatory variable is endogenous and therefore using 2SLS should be considered.
d. The explanatory variable is endogenous and therefore OLS should be used.
88 is a solution to (1/8) x =11 because if x = 88 then the equation (1/8) x = 11 is true.
Answers
Answer:
True
Step-by-step explanation:
To check to see if the statement given is true we need to substitute x with 88 and solve.
\((1/8)x=11\)
Substitute 'x' for 88.
\((1/8)88=11\\\\\boxed{11=11}\)
88 is a solution to the equation, therefore the statement is true.
Hope this helps.
Solve 4h = 92 for h.h = ___
Answers
Answer:
23
Step-by-step explanation:
4h = 92
Divide both sides by 4 to get h by itself
h = 23
It's been a long time and I'm in an Intro to Probability and Statistics class as a requirement. Even referring to my notes from last class is not helping. Here is the problem.
A particular basketball player hits 70% of her free throws. When she tosses a pair of free throws, the 4 possible simple events and 3 of their associated probabilities are as given below:
Simple Event Outcome of 1st Free Throw Outcome of 2nd Free Throw Probability
1 Hit Hit .49
2 Hit Miss ?
3 Miss Hit .21
4 Miss Miss .09
a. Find the probability that the player will hit on the 1st throw and miss on the 2nd throw. Figuring it out algebraically, I arrived at .29, or 29%. What I am unsure of is how to write it out in probability language.
b. Find the probability that the player will hit on at least one of the two free throws. I'm totally lost on this one.
Answers
a. The probability that the player will hit on the 1st throw and miss on the 2nd throw, expressed in probability language, is P(Hit 1st Throw ∩ Miss 2nd Throw) = 0.29 or 29%. b. The probability that the player will hit on at least one of the two free throws is P(Hit at least one Throw) = 0.91 or 91%, which is obtained by subtracting the probability of missing both throws from 1.
a. To write the probability of the player hitting on the 1st throw and missing on the 2nd throw in probability language, you can express it as the probability of the intersection of the two events.
In this case, it would be written as P(Hit 1st Throw ∩ Miss 2nd Throw). The calculated probability of 0.29 or 29% can be substituted, resulting in P(Hit 1st Throw ∩ Miss 2nd Throw) = 0.29.
b. To determine the probability that the player will hit on at least one of the two free throws, you can consider the complement of the event where she misses both throws.
The complement of an event A is written as A'. In this case, you need to find P(Hit at least one Throw) or 1 - P(Miss both Throws). Using the given probabilities, P(Miss both Throws) = 0.09. Therefore, P(Hit at least one Throw) = 1 - P(Miss both Throws) = 1 - 0.09 = 0.91 or 91%.
To know more about probability refer here:
https://brainly.com/question/31828911#
#SPJ11
Please help need by tomorrow it would be very very very appreciated

Answers
The solution of the given system of equations is (8, -1). of the given system of equations is (8, -1).
One method to solve the given system of equations is substitution:
- Solve one of the equations for one of the variables (e.g., x = 9 + y from the second equation).
- Substitute the expression for the variable into the other equation.
- Solve the resulting equation for the remaining variable.
- Substitute the value for the remaining variable back into one of the original equations to find the value of the other variable
Using this method with the given equations
- x - y = 9 -> x = 9 + y
- 3x + 2y = 22 -> 3(9 + y) + 2y = 22
- Simplifying and solving for y: 27 + 5y = 22 -> 5y = -5 -> y = -1
- Substituting y = -1 into x = 9 + y: x = 8
To check this solution, we can substitute these values back into both original equations and confirm that they are true statements.
For such more questions on solution
https://brainly.com/question/24644930
#SPJ8
Write an equation of the line in point slope form (y - y) = m(x - X1) given that the slope is 6 and the line passes through (5, 7). Then convert it to slope-
intercept form.
Point-Slope Form:
Slope-Intercept Form:
Answers
Answer:
x1 = -4
y1 = 2
x2 = 0
y2 = 3
m = (y2 - y1) / (x2 - x1)
Plug in the numbers and evaluate m, then either of the 2 equations below represents the line in point slope form:
y - y1 = m(x - x1)
y - y2 = m(x - x2)
Plug in the numbers. The slope intercept form is
y = mx + b
b = 3 (given)
m = result from earlier step
You convert to standard from and finish from here.
Jaymes Corporation produces high-performance rotors. It expects to produce 30,000 rotors in the coming year. It has invested $6,000,000 to produce rotors. The company has a required return on investment of 11%. What is its ROI per unit?
Answers
The ROI per unit for Jaymes Corporation's rotors is $200.
To calculate the ROI per unit, we need to divide the total return on investment by the number of units produced. In this case, the company has invested $6,000,000 to produce 30,000 rotors.
ROI per unit = Total ROI / Number of units produced
Total ROI = $6,000,000
Number of units produced = 30,000
ROI per unit = $6,000,000 / 30,000 = $200
Therefore, the ROI per unit for Jaymes Corporation's rotors is $200. This means that for every rotor produced, the company expects to generate a return of $200.
To know more about ROI, refer here:
https://brainly.com/question/30393107#
#SPJ11
Calculator
Diane and Curtis surveyed 8 of their friends to find the average number of minutes spent on math homework, per day. They recorded
the results of their survey in a list.
80, 75, 30, 70, 40, 55, 90, 20
What is the mean absolute deviation of this data set?
Enter your answer in the box
Answers
The answer is 21
I just took the test
Answer:
21.25
Step-by-step explanation:
took the test
Four lines are drawn on a coordinate plane to form trapezoid wxyz. Which statements are true about the lines? Select three options
Answers
The statements that are true for Trapezoid WXYZ are:
Line WZ has the same slope as line XY.Line XW has a lesser slope than line YZ.Line ZW has the same y-intercept as line WZ.Line XY has a greater y-interceptHow to Interpret Line Coordinates?
We are told that;
Shape is a trapezoid WXYZ.
Now, In a trapezoid, one pair of opposite sides are parallel and parallel lines have the same slope.
Lastly, the slope of line parallel to x axis is 0 and so If the line starts at the bottom left and goes towards the top right it has negative slope. Thus, all the statements that are true for Trapezoid WXYZ are:
Line WZ has the same slope as line XY.Line XW has a lesser slope than line YZ.Line ZW has the same y-intercept as line WZ.Line XY has a greater y-interceptComplete question is;
Four lines are drawn on a coordinate plane to form trapezoid WXYZ. Which statements are true about the lines? Select all that apply.
Line WZ has the same slope as line XY.
Line YX has a greater slope than line ZY.
Line XW has a lesser slope than line YZ.
Line ZW has the same y-intercept as line WZ.
Line XY has a greater y-intercept than line XW
Read more about Line Coordinates at; https://brainly.com/question/7243416
#SPJ1
Marissa is ordering Negative one-sixth, negative one-third, 1.4, 0.2, two-thirds from least to greatest. Here are her steps: (1) Write each decimal as a fraction. (2) Write every fraction with a common denominator of 18. (3) Plot the numbers on the number line. (4) List the numbers from left to right as they are plotted on the number line. Identify any and all errors that Marissa made in her steps. Marissa should have only plotted the fractions on the number line. Marissa should have used 30 as the common denominator. Marissa should have listed the numbers from right to left after she plotted them on the number line. Marissa should have used a common denominator of 30 and should have listed the numbers from right to left after she plotted them on the number line.
Answers
Answer:
Marissa should have used 30 as the common denominator.
Step-by-step explanation:
Looking at the numbers to be listed:
–1/6
–1/3
1.4 = 14/10 = 7/5
0.2 = 2/10 = 1/5
2/3
Looking for the LCM of 6, 3, 7/5, 1/5 and 3 we get 30.
Since the numbers are to be listed from least to greatest, then ordering from left to right is the correct form of listing since the numbers on the number line increase going from left to right.
This implies that the only mistake she made was she should've used 30 as the common denominator.
Answer:
BStep-by-step explanation:
HOPE IT HELPS!
please Helps it’s urgent

Answers
Answer:
<1 and <3
Step-by-step explanation:
They are both symmetric
Can someone help me please!!!

Answers
1) undefined
Vertical lines have undefined slope.2) 2
Isolating y, we get y=2x-6, and thus the slope is 2.3) 0
Since the y-coordinate is constant, the slope is 0.4) -3
Using the slope formula, (-2-7)/(4-1) = -3.U.S. Birth Rate, 1950-2000
Year
Birth Rate
(per 1000 population)
1950
24.1
1960
23.7
1970
18.4
1980
15.9
1990
15.7
2000
14.7
Source: World Almanac 2003
Is the relation (year, birth rate) a function? Explain.
a.
No, there is a year with two birth rates paired with it.
b.
Yes, each year is paired with only one value for the birth rate.
c.
No, two years have a birth rate of over 20.
d.
No, there are no negative birth rate values.
Answers
Using it's concept, it is found that the correct option regarding whether the relation is a function is given by:
b. Yes, each year is paired with only one value for the birth rate.
When a relation represents a function?It represents a function if each value of the input is mapped to only one value of the output.
In this problem, the inputs are the decades(1950 to 2000), and each has only one rate, hence it is a function and option b is correct.
More can be learned about functions at https://brainly.com/question/12463448
#SPJ1
What is the upper quartile, Q3, of the following data set? 42, 38, 30, 53, 54, 66, 27, 61, 31, 57, 46, 18, 35, 49, 23
Answers
The upper quartile, Q3, of the given data set, is 54.
The upper quartile, Q3, is a measure of central tendency that represents the 75th percentile of a given dataset. It divides the data into two halves, with the upper half representing the range of values from Q3 to the maximum value. In order to find the upper quartile, we first need to arrange the data set in ascending order: 18, 23, 27, 30, 31, 35, 38, 42, 46, 49, 53, 54, 57, 61, 66.
Next, we need to determine the position of Q3 in the dataset. Since there are 15 data points in the set, Q3 will be located at the 75th percentile or 11.25th data point. To find the exact value of Q3, we can use the following formula:
Q3 = (0.75 * (n + 1)th term) + (0.25 * (n)th term)
where n is the number of data points in the set. Substituting the values, we get:
Q3 = (0.75 * 16th term) + (0.25 * 15th term)
Q3 = (0.75 * 12) + (0.25 * 11)
Q3 = 9 + 2.75
Q3 = 11.75
Therefore, the upper quartile, Q3, of the given data set is 54.
To learn more about Data set :
https://brainly.com/question/28168026
#SPJ11
10
00
Determine the approximate ordered pair for f(x) = g(x). (1 point)
O (24,8)
O (16,8)
O (8, 24)
O (8, 16)
Answers
Answer:
Sorry, I can't help without some more context
(a)(i) which of the following is the most appropriate measure for the typical value of the average salary paid to nfl players? --- what is the value of this salary? (use jmp to compute it, the closest integer is sufficient.) $ (ii) which is the most appropriate measure for the spread of these salaries?
Answers
The most appropriate measure for the typical value of the average salary paid to nfl players is mean.
The most appropriate measure for the spread of these salaries is IQR
In statistics, in addition to the mode and median, the mean is one of the measures of central tendency. Simply said, the mean is the average of the values in the given collection. It indicates that values in a certain data collection are distributed equally.
The three most often employed measures of central tendency are the mean, median, and mode. The total values provided in a datasheet must be added, and the sum must be divided by the total number of values in order to get the mean.
The difference between the third and the first quartile is defined by the interquartile range. The partitioned values known as quartiles divide the whole series into four equally sized segments. There are so three quartiles.
The first quartile, also known as the lower quartile, is marked by Q1, the second quartile by Q2, and the third quartile, sometimes known as the upper quartile, is denoted by Q3. The lower quartile less the higher quartile equals the interquartile range.
Learn more about Mean and IQR:
https://brainly.com/question/9821103
#SPJ4
585 divided by 5 is?
Answers
true or
false?
Every semisimple matrix A \in{R}^{n \times n} is invertible.
Answers
The statement "Every semi-simple matrix A ∈ R^(n²) is invertible" is True.
First, let's take a look at what is meant by a semisimple matrix.
A matrix that is diagonalizable over a closed field R and has no repeated eigenvalues is known as a semisimple matrix. The characteristic polynomial has n simple roots in this case. A semisimple matrix can also be defined as a matrix which is the sum of smaller, simple matrices.
The inverse of a matrix is always true for square matrices. Square matrices are matrices that have n number of rows and n number of columns, basically number of rows = number of columns.
Here, if the matrix is A then its inverse A\(A^{-1}\) = I, where I is defined as an identity matrix.
A semisimple matrix is defined to be a square matrix and since it is a square matrix, it is invertible always.
Learn more about eigenvalues: https://brainly.com/question/29861415
#SPJ11
Using the descriptive statistics excel tool, what % of women in the sample has a masters degree?
Answers
To determine the percentage of women in a sample with a master's degree using Excel, you need to follow:
First, make sure your data is organized in columns, with one column for gender and another for education level.
Next, use the filter feature in Excel to display only the rows where the gender is "Female" or "Woman". This will help isolate the data for women in the sample.
Then, focus on the education level column and filter it to show only the rows where the education level is "Master's Degree". This will narrow down the data to women with a master's degree.
Count the number of women with a master's degree by using the COUNTIFS function in Excel. Set the criteria to match "Female" or "Woman" in the gender column and "Master's Degree" in the education level column. This will provide the count of women with a master's degree.
Now, calculate the total number of women in the sample by using the COUNTIF function. Set the criteria to match "Female" or "Woman" in the gender column. This will give you the count of all women in the sample.
Finally, divide the count of women with a master's degree by the count of all women in the sample and multiply by 100 to obtain the percentage. This will represent the percentage of women in the sample with a master's degree.
By following these steps and adapting them to your specific dataset in Excel, you can determine the percentage of women in the sample with a master's degree.
To know more about Excel refer here:
https://brainly.com/question/3441128#
#SPJ11
given that on one section of the sat the mean is 500 and the standard deviation is 100, what is the approximate probability of a student scoring 400 or lower or 700 or higher on the test?
Answers
The approximate probability of a student scoring 400 or lower or 700 or higher on the SAT is about 0.1815 or 18.15%.
How to find the approximate probability of a student scoring 400 or lower or 700 or higher on the test?To find the approximate probability of a student scoring 400 or lower or 700 or higher on the SAT, we can use the z-score formula and the standard normal distribution.
First, we need to convert the raw scores of 400 and 700 to z-scores using the formula:
z = (x - μ) / σ
where x is the raw score, μ is the population mean, and σ is the population standard deviation.
For a raw score of 400:
z = (400 - 500) / 100 = -1
For a raw score of 700:
z = (700 - 500) / 100 = 2
Next, we can use a standard normal distribution table (or calculator) to find the probabilities associated with these z-scores.
The probability of a z-score of -1 or lower is approximately 0.1587. This represents the area under the standard normal distribution curve to the left of z = -1.
The probability of a z-score of 2 or higher is approximately 0.0228. This represents the area under the standard normal distribution curve to the right of z = 2.
To find the probability of scoring 400 or lower or 700 or higher on the SAT, we can add these probabilities together:
P(score ≤ 400 or score ≥ 700) ≈ 0.1587 + 0.0228 ≈ 0.1815
Therefore, the approximate probability of a student scoring 400 or lower or 700 or higher on the SAT is about 0.1815 or 18.15%.
Learn more about probability
brainly.com/question/11034287
#SPJ11
Jolene has 30 days to prepare for a
bicycle race. She will bicycle 15 miles
each day. How many miles will
Jolene have bicycled during her
training?

Answers
Answer:
450 miles in total during her training
Step-by-step explanation:
Since it does say she has 30 days to train and she said she will ride her bike 15 miles everyday she trains so she will have ridden her bike for 450 miles in total
30 days to train x 15 miles per day = 450 miles in total
Since 300 - 1 does not equal 1 - 300, we say that subtraction does not have the commutative property property of zero associative property distributive property
Answers
3n yo _2222224455555
Step-by-step explanation
15 men can complete the construction of a wall in 12 days in how many days can 18 men complete the same work
Answers
Answer:
10 days
Step-by-step explanation:
15 men ----- 12 days
18 men ----- x ?
They are inversely proportional
more men less days
15 / 18 * 12 = 10 days
Let a, b, c, m and n be integers. Prove that if a|b and a|c, the a|(bm + cn)
Answers
If a divides b and a divides c, then a divides (bm + cn).
To prove that if a divides b and a divides c, then a divides (bm + cn), we can use the properties of divisibility.
Given:
a|b, which means b is divisible by a.
a|c, which means c is divisible by a.
We want to show that a|(bm + cn), which means (bm + cn) is divisible by a.
By definition, if a divides b, then there exists an integer k₁ such that b = ka. Similarly, if a divides c, there exists an integer k₂ such that c = ka.
Now, let's substitute these expressions into (bm + cn):
(bm + cn) = (ka)m + (ka)n
= kam + kan
= a(km + kn)
We can see that (bm + cn) can be written as a times the integer (km + kn). Since (km + kn) is an integer, this implies that (bm + cn) is divisible by a.
Therefore, if a divides b and a divides c, then a divides (bm + cn).
Learn more about divisibility here
https://brainly.com/question/21416852
#SPJ4
There are sol students in the
school. 4/9 of the total number of
students are boys. The rest are
girls. How many more girls are there
than boys?
Answers
I think the answer is 5/9
help me please i dont understand this
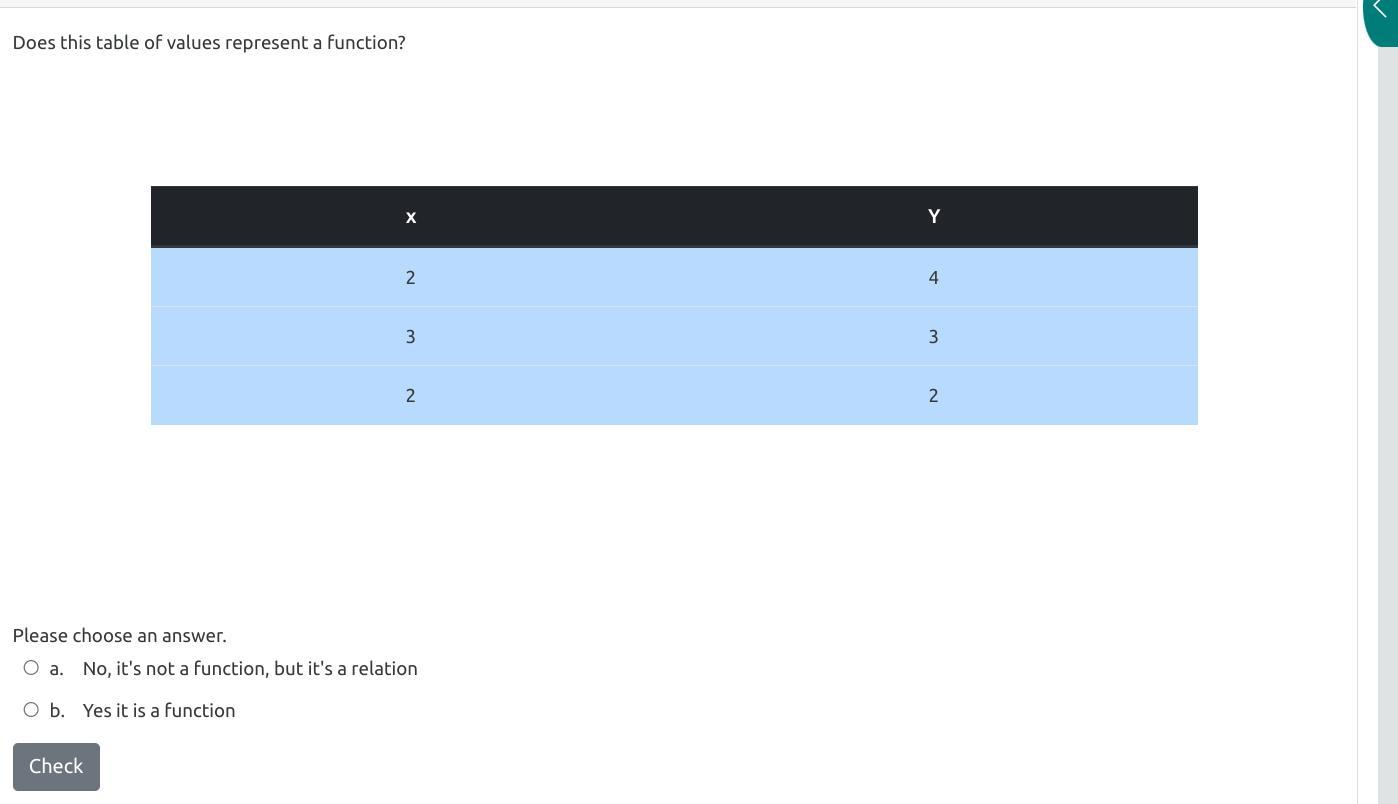
Answers
Answer:
It is not a function
Step-by-step explanation:
A function refers to a set of points/lines with this characteristic:
Each Y value has only one corresponding X value.
Meaning one X value cannot have multiple Y Values.
In this case, the X value of 2 has 2 different Y values, making it not a function.
Ben traveled 53.30 miles by bike , 18.23 miles by car and 52.62 miles by bus. What is the total distance that he traveled ?
Answers
Answer:
124.15 Miles
Step-by-step explanation:
53.30 + 18.23 + 52.62