You went to the doctor there are 8 patiens the doctor says you have to wait 2 hours for your turn how many minutes will the doctor use on the patients
Answers
The doctor will use 960 minutes on the patients before it is your turn.
If there are 8 patients before you and the doctor says you have to wait 2 hours for your turn, we need to calculate the total time the doctor will spend with all the patients before you.
Since there are 60 minutes in an hour, 2 hours would be equal to 2 * 60 = 120 minutes.
To find the total time the doctor will use on the patients, we need to multiply the number of patients by the time per patient. In this case, there are 8 patients before you, so:
Total time = Number of patients * Time per patient
= 8 * 120
= 960 minutes
It's important to note that this calculation assumes equal time spent with each patient. In reality, the time spent with each patient may vary depending on their medical needs and the complexity of their cases.
for more such questions on minutes
https://brainly.com/question/17909043
#SPJ8
Related Questions
x/16-g=a what would x =???
Answers
Answer: x - 777 = 0
Step-by-step explanation
x = 777
Move the contrast to the left
x - 777 = 777 -777
Eliminate the opposites
Please help and NO LINKS!

Answers
Answer:
2/100 is the answer to the question
Answer:
B
Step-by-step explanation:
look at the image for the question and answers

Answers
Answer:
C
Step-by-step explanation:
Answer:
2 units
Step-by-step explanation:
Using the given formula
P = 2(l + w)
= 2(\(\frac{2}{3}\) + \(\frac{1}{3}\) )
= 2(1)
= 2 units
(c) prove that for any positive integer n, 4 evenly divides 11n - 7n.
Answers
By mathematical induction, we have proved that for any positive integer n, 4 evenly divides 11n - 7n.
WHat is Divisibility?
Divisibility is a mathematical property that describes whether one number can be divided evenly by another number without leaving a remainder. If a number is divisible by another number, it means that the division process results in a whole number without any remainder. For example, 15 is divisible by 3
To prove that 4 evenly divides 11n - 7n for any positive integer n, we can use mathematical induction.
Base Case:
When n = 1, 11n - 7n = 11(1) - 7(1) = 4, which is divisible by 4.
Inductive Step:
Assume that 4 evenly divides 11n - 7n for some positive integer k, i.e., 11k - 7k is divisible by 4.
We need to prove that 4 evenly divides 11(k+1) - 7(k+1), which is (11k + 11) - (7k + 7) = (11k - 7k) + (11 - 7) = 4k + 4.
Since 4 evenly divides 4k, and 4 evenly divides 4, it follows that 4 evenly divides 4k + 4.
By mathematical induction, we have proved that for any positive integer n, 4 evenly divides 11n - 7n.
To know more about Divisibility visit:
https://brainly.com/question/9462805
#SPJ4
Please help and show work, will give lots of points!
Lourdes is reading a biography for her history class. She reads 30 pages each day. After 9 days, Lourdes has read 3/5 of the biography. Write a linear equation to represent the number of pages Lourdes still has to read after x days.
y = []x + []
(Use above format to write the equation.)
What does the y-intercept of this linear equation represent?
A. Pages already read
B. Pages in book
C. Pages read each day
D. Days to finish
Answers
Answer:
The linear equation is y = 450 - 30 x, where y is the number of pages
Lourdes has left to read after x days
Step-by-step explanation:
Each day, Lourdes reads 30 pages of a 450-page book
- We need to write a linear equation to represent the number of pages
Lourdes has left to read after x days
∵ Lourdes reads 30 pages each day
∵ Lourdes will read for x days
∴ The number of pages Lourdes will read in x day = 30 x
- The left pages will be the difference between the total pages of the
book and the pages Lourdes read
∵ The book has 450 pages
∵ Loured will read 30 x in x days
∴ The number of pages left = 450 - 30 x
- Assume that y represents the number of pages Lourdes has left
to read after x days
∴ y = 450 - 30 x
The linear equation is y = 450 - 30 x, where y is the number of
pages Lourdes has left to read after x days
show that cov(x,y)=0 if x,y are independent. hint: find a computational formula for covariance, similar to the computational formula for variance, var(x)=e(x2)[e(x)]2.
Answers
If x and y are independent, then the covariance between x and y, cov(x, y), is equal to 0.
Covariance measures the linear relationship between two random variables. If x and y are independent, it means that the occurrence of one variable does not affect the occurrence of the other. In other words, there is no linear relationship between x and y.
The computational formula for covariance is given by:
cov(x, y) = E[(x - E[x])(y - E[y])],
where E[x] and E[y] are the expected values of x and y, respectively.
If x and y are independent, it implies that E[x] and E[y] are also independent, and therefore the term (x - E[x])(y - E[y]) will equal 0 for all possible values of x and y. Consequently, the expected value of this term will also be 0.
Since cov(x, y) is defined as the expected value of (x - E[x])(y - E[y]), and this term is 0, it follows that cov(x, y) must be equal to 0.
Hence, if x and y are independent, their covariance cov(x, y) is always 0, indicating that there is no linear relationship between the variables.
Visit here to learn more about covariance:
brainly.com/question/28135424
#SPJ11
How long will it take to pay off a loan of $49,000 at an annual rate of 9 percent compounded monthly if you make monthly payments of $400? Use five decimal places for the monthly percentage rate in your calculations. The number of years it takes to pay off the loan is years. (Round to one decimal place.)
Answers
To pay off a loan of $49,000 at an annual interest rate of 9% compounded monthly, with monthly payments of $400, it will take approximately 12.9 years.
To determine the time it takes to pay off the loan, we can use the formula for the number of periods (n) in the compound interest formula. In this case, the loan amount is $49,000, the monthly payment is $400, and the monthly interest rate is 9% divided by 12 (0.09/12 = 0.0075). We can use the following formula:
\(n = -log(1 - (r * P) / A) / log(1 + r)\)
where r is the monthly interest rate, P is the monthly payment, and A is the loan amount.
Plugging in the values, we have:
\(n = -log(1 - (0.0075 * 49000) / 400) / log(1 + 0.0075)\)
Calculating this expression, we find that n is approximately 12.9 years. Therefore, it will take approximately 12.9 years to pay off the loan with monthly payments of $400, rounded to one decimal place.
Learn more about loan here:
https://brainly.com/question/20533349
#SPJ11
when cutting carrots into small pieces, you are deciding whether to use a knife and cutting board or a food processor. Each carrot chopped by hand takes 45 seconds. each carrot chopped in a food processor takes 12 seconds. it takes 25 seconds to clean off the knife and board. It takes 6 minutes to clean the food processor. What is the minimum number of carrots to cut up for which it will be faster to use a food processor than the knife and cutting board? (factor in both the cutting time and the cleaning time, Your final answer should be an integer
Answers
The minimum number of carrots to cut up for which it will be faster to use a food processor than the knife and cutting board is 11.
In order to find the minimum number of carrots to cut up for which it will be faster to use a food processor than the knife and cutting board, we need to calculate the time taken by each method and then compare it. Let's say the minimum number of carrots is x.
Here's how we can calculate the time taken to chop x carrots:
Time taken using knife and cutting board = 45x + 25 (25 is added for the time taken to clean the knife and board)
Time taken using food processor = 12x + 360 (360 is added for the time taken to clean the food processor)
Now, we need to find the value of x for which the time taken using the food processor is less than the time taken using the knife and cutting board.
So,12x + 360 < 45x + 2512x - 45x < 25 - 360-33x < -335x > 10.15
Therefore, the minimum number of carrots to cut up for which it will be faster to use a food processor than the knife and cutting board is 11.
Thus, the minimum number of carrots to cut up for which it will be faster to use a food processor than the knife and cutting board is 11.
To know more about time taken visit:
brainly.com/question/24258354
#SPJ11
Question 6 Multiple Choice Worth 1 points)
(01.06 LC)
Solve x - 5y = 6 for x.
Answers
Answer:
x = 6+5y
Step-by-step explanation:
x - 5y = 6
Add 5y to each side
x - 5y+5y = 6+5y
x = 6+5y
Answer:
x = 6 + 5y
Step-by-step explanation:
x - 5y = 6
Solve for x.
x - 5y = 6
Add 5y to both side
x - 5y + 5y = 6 + 5y
x = 6 + 5y
Describe the meaning of the translation (x + 6, y + 10).
All points are moved 6 units right and 10 units up
All points are moved 6 units left and 10 units up
All points are moved 6 units left and 10 units down
All points are moved 6 units right and 10 units down
Answers
Answer:
Step-by-step explanation:
The meaning of the translation (x + 6, y + 10) is that all points in a coordinate plane are moved 6 units to the right and 10 units up.
In other words, for any point (x, y) in the original position, after the translation, the new coordinates would be (x + 6, y + 10). This means that the x-coordinate of each point is increased by 6 units, resulting in a shift to the right, and the y-coordinate is increased by 10 units, resulting in a shift upwards.
Estimating BMI The body mass index (BMI) of all American young women is believed to follow a Normal distribution with a standard deviation of about 7.5. How large a sample would be needed to estimate the mean BMI m in this population to within ±1 with 99% confidence? Show your work.
Answers
To estimate the mean BMI (m) in the population of American young women with a confidence interval of ±1 and 99% confidence, we can use the formula:
n = (Z * σ / E)^2
Where:
n = required sample size
Z = Z-value corresponding to the desired confidence level (99% confidence level corresponds to Z = 2.576)
σ = standard deviation of the population (given as 7.5)
E = margin of error (±1)
Plugging in the values, we have:
n = (2.576 * 7.5 / 1)^2
n = (19.314 / 1)^2
n = 372.36
Rounding up to the nearest whole number, we need a sample size of approximately 373 to estimate the mean BMI in the population with a 99% confidence level and a margin of error of ±1.
Learn more about estimate here:
https://brainly.com/question/30870295
#SPJ11
arccos 2x + arccos x = TT/2
How to solve find x ?
Answers
arccos(2x) + arccos(x) = π/2
Apply cos to both sides, then expand the right side using the identity I mentioned in a comment:
cos(arccos(2x) + arccos(x)) = cos(π/2)
cos(arccos(2x)) cos(arccos(x)) - sin(arccos(2x)) sin(arccos(x)) = 0
Now think of arccos(2x) and arccos(x) as angles in two right triangles. Let θ = arccos(2x) and φ = arccos(x) (and let's also assume that both have measure between 0 and π/2). These are angles such that
cos(θ) = 2x
cos(φ) = x
In these triangles, you then have
sin(θ) = sin(arccos(2x)) = √(1 - 4x ²)
sin(φ) = sin(arccos(x)) = √(1 - x ²)
while
cos(θ) = cos(arccos(2x)) = 2x
cos(φ) = cos(arccos(x)) = x
So the original equation is transformed to
2x ² - √(1 - 4x ²) √(1 - x ²) = 0
Solve for x :
2x ² = √(1 - 4x ²) √(1 - x ²)
(2x ²)² = (√(1 - 4x ²) √(1 - x ²))²
4x ⁴ = (1 - 4x ²) (1 - x ²)
4x ⁴ = 1 - 5x ² + 4x ⁴
0 = 1 - 5x ²
x ² = 1/5
x = ± 1/√5
Now bearing in mind that we assume 0 < φ < π/2, we should have cos(φ) = x > 0, so we take the positive solution,
x = 1/√5
help pleaseeeeeee ty

Answers
Answer: I think the answer is never but I'm not sure
Step-by-step explanation:
Solve for x given that the polygons are similar. Then find the scale factor of the smaller figure to the larger figure.
Answers
The given polygons are similar and the scale factor of dilation is 3 : 2
Given data ,
Let the scale factor of the dilation be represented as k
Now , the value of k is
The measure of the ratio of corresponding sides are given as
21 / 14 = 12 : 8
3 : 2 = 3 : 2
Therefore , the dilation factor is 3 : 2
And , the measure of x is given by
21 / 14 = x / 12
3 / 2 = x / 12
Multiply by 12 on both sides , we get
x = 18
Hence , the dilation of polygon is solved
To learn more about dilation click :
https://brainly.com/question/13176891
#SPJ1
The complete question is attached below :
Solve for x given that the polygons are similar. Then find the scale factor of the smaller figure to the larger figure

Which of the answer choices is a test score displayed in this Stem-and-Leaf Plot?
A. 21
B. 56
C. 45
D. 94

Answers
A test score displayed in this Stem-and-Leaf plot is given by:
B. 56.
What is a stem-and-leaf plot?The stem-and-leaf plot lists all the measures in a data-set, with the first number as the key, for example:
4|5 = 45.
From the given stem-and-leaf plot, the scores are listed as follows:
48, 49, 50, 51, 54, 55, 56, 58, 60, 62, 63 and 63.
Hence a test score displayed in this Stem-and-Leaf plot is given by:
B. 56.
More can be learned about Stem-and-Leaf plots at https://brainly.com/question/27683035
#SPJ1
Answer:b took the test
Step-by-step explanation:
brainly me and ill answer all the questions to the test
According to the lesson, describe in detail how you would use a centimeter ruler to measure a match stick?
Answers
To use a centimeter ruler to measure a matchstick, place the ruler parallel to the matchstick, aligning the zero mark with one end. Identify the nearest centimeter mark and estimate the millimeter measurement by looking at the divisions between centimeters and smaller increments for more precision.
To begin, ensure the centimeter ruler is in good condition and properly calibrated. Lay the matchstick on a flat surface, making sure it is straight. Position the ruler next to the matchstick, aligning the zero mark with one end while keeping it parallel to the matchstick. Observe the other end of the matchstick and identify the nearest centimeter mark on the ruler to the left of the end point. This represents the whole centimeter measurement. Next, look at the lines or ticks between the whole centimeter marks. Each centimeter is divided into 10 millimeter intervals. Estimate the length of the matchstick by identifying the millimeter line that aligns with the end of the matchstick. For more precise measurements, use the smaller divisions on the ruler. Each millimeter is further divided into smaller increments called tenths of a millimeter. Estimate the length by identifying the smallest increment that aligns with the end of the matchstick. Record the measurement by noting the number of centimeters, followed by the number of millimeters (and tenths of millimeters, if necessary). Handle the matchstick carefully to avoid any damage or inaccuracies in the measurement..
Learn more about centimeter ruler here:
https://brainly.com/question/30667952
#SPJ11
from the top of a building, a man observes a car moving toward him. as the car moves 100 ft closer, the angle of depression changes from 15 to 33 o o . find the height of the building.
Answers
When a man on top of a building sees a car approaching him and as the car moves 100 ft closer, the angle of depression changes from 15 to 33 degrees, the height of the building is 159.8 feet.
To solve the problem, we can use the tangent function. Let x be the distance between the man and the building, then we have:
tan(15) = h / x ...........(1) and tan(33) = h / (x - 100) ...........(2)
Dividing (2) by (1), we get:
tan(33) / tan(15) = (x - 100) / x
Simplifying the expression, we have:
(x - 100) / x = 2.22
Solving for x, we get:
x = 100 / 1.22 ≈ 81.97
Using equation (1), we can solve for the height of the building:
h = x * tan(15)
h ≈ 159.8
Therefore, the height of the building is approximately 159.8 feet.
To know more about height, refer here:
https://brainly.com/question/27917190#
#SPJ11
how to find the height of a cone given the volume and radius
Answers
Answer:
h = 3V/(πr²)
Step-by-step explanation:
You want to find the height of a cone given the volume and radius.
Volume formulaYou can find the height by using the volume formula and solving it for height.
V = 1/3πr²h
HeightMultiplying by the inverse of the coefficient of h gives ...
3V/(πr²) = h
You can use this formula to find the height from the volume and radius:
h = 3V/(πr²)
<95141404393>
What is the image of (−1,−5) after a dilation by a scale factor of 5 centered at the origin?
Answers
Answer:
(-5,-25) that is the image
Step-by-step explanation:
a regression was run to determine if there is a relationship betweenhours of tv watched per day (x) and number of situps a person can do (y).
Answers
The regression analysis examines the relationship between hours of TV watched per day (x) and the number of situps a person can do (y) to determine if a relationship exists.
The regression analysis was conducted to investigate the potential relationship between the number of hours of TV watched per day (x) and the number of situps a person can do (y). Regression analysis is a statistical technique used to examine the association between variables and determine the nature and strength of their relationship.
In this case, the regression analysis would have yielded an equation that represents the linear relationship between the variables. The equation could be in the form of y = mx + b, where "m" represents the slope of the line (indicating the change in y for each unit change in x) and "b" represents the y-intercept (the value of y when x is equal to zero). The coefficients obtained from the regression analysis provide information about the direction and magnitude of the relationship between the variables.
The analysis aims to determine whether there is a statistically significant relationship between the hours of TV watched per day and the number of situps a person can do. The regression results, including the coefficients, significance levels, and measures of goodness-of-fit, would help assess the strength and significance of the relationship between the variables.
learn more about regression analysis here:
https://brainly.com/question/12213669
#SPJ11
) in an experiment on a damped spring oscillator with spring constant n/m, student c obtains the displacement vs time curves as in fig. 2(a), and records the maximum displacement data points as below. 1 2
Answers
In an experiment on a damped spring oscillator with spring constant n/m, student c obtains the displacement vs time curves as in fig. 2(a), and records the maximum displacement data points as below is y = - 3.7148.
Here we have to find the displacement for the graphs of y and t that is maximum and We can find that by y = mc where m, = slope, c= intercept.
Slope = m= - 0.737414.intercept = c= - 3.714855.In experiment on a damped spring oscillator with spring constant n/m, student c obtains the displacement vs time curves. by y = m+c = - 0.737414 + - 3.714855 = - 3.7148.Thus the displacement= - 3.7148Read more about the slope:
https://brainly.com/question/23946616
#SPJ4
in the united states, according to a 2018 review of national center for health statistics information, the average age of a mother when her first child is born in the u.s. is 26 years old. a curious student at cbc has a hypothesis that among mothers at community colleges, their average age when their first child was born is lower than the national average. to test her hypothesis, she plans to collect a random sample of cbc students who are mothers and use their average age at first childbirth to determine if the cbc average is less than the national average. use the dropdown menus to setup this study as a formal hypothesis test. [ select ] 26 [ select ] 26
Answers
To set up this study as a formal hypothesis test, the null hypothesis (H0) would be that the average age of first childbirth among mothers at community colleges (CBC) is equal to the national average of 26 years old.
The alternative hypothesis (Ha) would be that the average age of first childbirth among CBC mothers is lower than the national average.
The next step would be to collect a random sample of CBC students who are mothers and determine their average age at first childbirth. This sample would be used to calculate the sample mean.
Once the sample mean is obtained, it can be compared to the national average of 26 years old. If the sample mean is significantly lower than 26, it would provide evidence to reject the null hypothesis in favor of the alternative hypothesis, supporting the student's hypothesis that the average age of first childbirth among CBC mothers is lower than the national average.
The student plans to conduct a hypothesis test to determine if the average age of first childbirth among mothers at CBC is lower than the national average.
To know more about alternative hypothesis visit :
brainly.com/question/33149605
#SPJ11
kathy needs money for her trip to europe. if she has $300$ us dollars in the bank but wants to withdraw half of it in british pounds and half of it in euros, how many more euros than pounds will she have? assume $1$ pound is equal to $1.64$ usd and $1$ euro is equal to $1.32$ usd, and round to the nearest whole number.
Answers
Kathy will have 23 more euros than pounds after withdrawing half of her money in each currency using algebra.
First, let's calculate how much money Kathy will withdraw in pounds and euros. She wants to withdraw half of her $300$ US dollars in each currency, so that would be $150$ US dollars for each.
To find the amount in pounds, we can divide $150$ US dollars by the exchange rate of $1.64$ USD per pound:
Amount in pounds = $\frac{150}{1.64} \approx 91.46$ pounds.
To find the amount in euros, we can divide $150$ US dollars by the exchange rate of $1.32$ USD per euro:
Amount in euros = $\frac{150}{1.32} \approx 113.64$ euros.
Rounding both amounts to the nearest whole number, Kathy will have approximately $91$ pounds and $114$ euros.
To determine how many more euros than pounds she will have, we subtract the amount in pounds from the amount in euros:
$114$ euros - $91$ pounds = $23$ more euros than pounds.
Therefore, Kathy will have 23 more euros than pounds after withdrawing half of her money in each currency.
For more details about algebra
https://brainly.com/question/29131718
#SPJ4
Look at this graph:
100
90
80
70
60
50
40
30
20
10
х
0
10 20
30 40
50
60
70
80 90 100
What is the slope?
Simplify your answer and write it as a proper fraction, improper fraction, or integer.

Answers
Answer:
(1/4)
Step-by-step explanation:
See explanation in the attachment.
A slope of (1/4) means that y will increase by 1 for every 4 increase in x.

How do I solve 11=12-q
Answers
Answer:
1
Step-by-step explanation:
11=12-q
11-12=-q
-1=-q
1=q
Answer:
q =1
Step-by-step explanation:
\(11=12-q\\\)
Collect like terms
\(11-12 =-q\)
Subtract ; 11-12 =-1
\(-1= -q\)
Switch sides
\(-q =-1\)
Multiply through by -1 (reverse the inequality)
\(-1(-q)=-1(-1)\\\\q =1\)
Select the correct answer.
Which expression is equivalent to the given expression? Assume the denominator does not equal zero

Answers
Answer:
C.1/cd4
Step-by-step explanation:
cd.d.d.d (d 4times)
-------------------------
c.c.d.d.d.d.d.d.d.d (c 2 times and d 8 times)
simplify
1/cd4
Suppose that some consumer's preference, using a Cobb-Douglas utility function U, where U: U(b, c) =b ^50 c^50 . Assuming that the consumer is able to buy $84 on two goods, b and c, where P b =6, and Pc = 7 1. Find the most - preferred, affordable bundle 2. Define the income expansion point 2. Consumer preferences are characterized axiomatically. These axioms of consumer choice give formal mathematical expression to fundamental aspects of consumer behavior and attitudes towards the objects of choice. Explain the axioms of consumer choice and present them in terms of binary relations.
Answers
The most-preferred, affordable bundle can be found by maximizing the utility function subject to the budget constraint.
How can we find the most-preferred, affordable bundle?To find the most-preferred, affordable bundle, we need to maximize the utility function U(b, c) = b^50 * c^50 subject to the budget constraint. The budget constraint can be expressed as P_b * b + P_c * c = I, where P_b and P_c are the prices of goods b and c respectively, and I is the consumer's income.
In this case, P_b = 6, P_c = 7, and the consumer's income is $84. We can substitute these values into the budget constraint and rearrange it to solve for one variable in terms of the other. For example, we can solve for b in terms of c or vice versa.
Once we have the relationship between b and c, we can substitute it into the utility function and maximize it to find the combination of b and c that gives the highest utility. This will give us the most-preferred bundle that is affordable.
Learn more about most-preferred
brainly.com/question/32404465
#SPJ11
lines y = -x+2 and y=x+1. The point of intersection of the linear equations is *
(0,2)
(0.5, 1.5)
(-1,0)
(2,0)
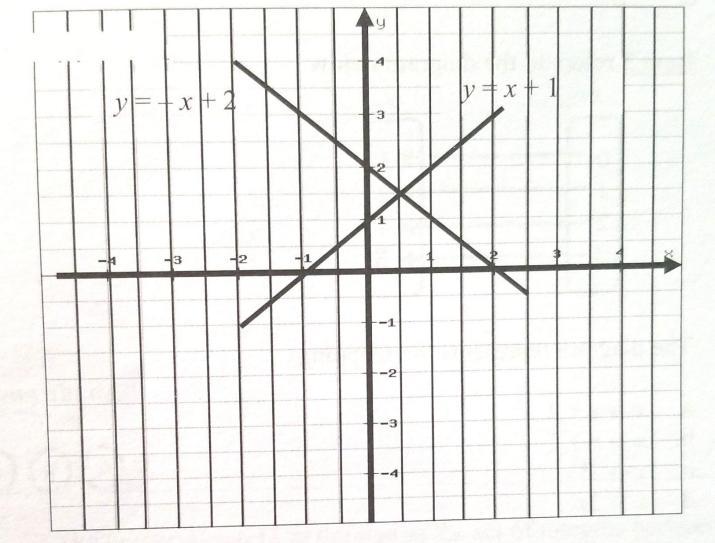
Answers
We can solve it by seeing the graph but let's solve the equations.
\(\\ \sf\Rrightarrow y=-x+2\)
\(\\ \sf\Rrightarrow y=x+1\)
Now
\(\\ \sf\Rrightarrow -x+2=x+1\)
\(\\ \sf\Rrightarrow -2x=-1\)
\(\\ \sf\Rrightarrow x=0.5\)
Put in eq(2)
\(\\ \sf\Rrightarrow y=0.5+1\)
\(\\ \sf\Rrightarrow y=1.5\)
Done
A meteorologist in Seattle says there is a 75% chance of rain. A meteorologist in Tacoma says there is a 1/4 chance of rain. In which city is it more likely to rain?
A. Seattle
B. Tacoma
C. Batesville
D. Both have the same chance
Answers
Steps:
1/4 = 25%
Which is more 25% or 75%?
The answer is 75%
Explanation:
Firstly, we're going to assume that both predictions are correct, because, well, they're just predictions. Let's write them down:
Seattle Rain Chance
=
75
%
Tacoma Rain Chance
=
3
4
Now, we can see that both predictions are in different forms: one in the form of percentage, and the other in the form of a fraction. To compare, we could convert one of them... Let's convert the fraction into a percentage. But, how?
Well, what "percent" means is "per hundred". We could multiply the number by
1
, which shouldn't change anything...
... but then convert it to
100
100
(because they both divide out into
1
)...
... and finally, by definition, to
100
%
:
1
=
100
100
=
100
%
Tacoma Rain Chance
=
Tacoma Rain Chance
⋅
1
Tacoma Rain Chance
⋅
1
=
Tacoma Rain Chance
⋅
100
%
Let's evaluate it:
Tacoma Rain Chance
=
3
4
⋅
100
%
=
300
4
%
=
75
%
Now let's compare it to the Seattle rain chance:
Seattle Rain Chance
=
75
%
Whew, they're equal!
Seattle Rain Chance
=
Tacoma Rain Chance
Therefore, with the assumption that both predictions are correct, it is equally likely to rain in either city.
please help, i don't understand the subject so i need an answer to help me out:) i will give brainliest to a good answer.

Answers
To be honest, I don't think it has anything to do with the exponent part at all. Instead, I think it has to do with the fact that integers are inherently easier to grasp compared to fractions (which is exactly what rational numbers are).
For instance, it's much easier to say 2+3 = 5 than it is to say 1/2 + 1/4 = 3/4
So going back to the exponent example, it's easier to say
x^2*x^3 = x^(2+3) = x^5
than it is to say
x^(1/2)*x^(1/4) = x^(1/2+1/4) = x^(3/4)
So that's my opinion as to why rational exponents are more tricky to grasp compared to integer exponents. Of course, everyone learns math differently so maybe some find fractions easier than others.