write each quantity as a fraction with a denominator less than 48 but greater than 24: 3/16
Answers
maybe it is 36 don't know for sure
Related Questions
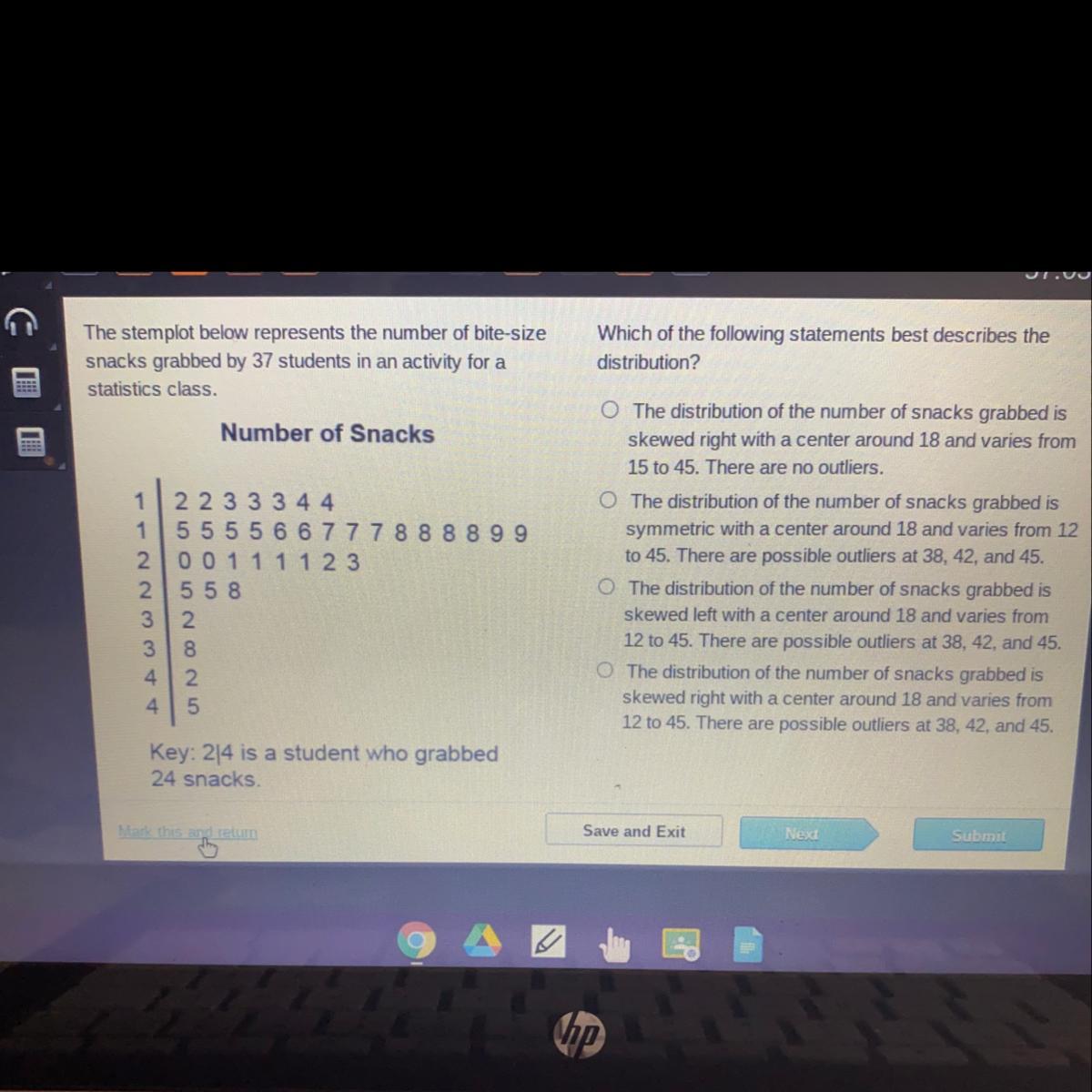
The stemplot below represents the number of bite-size
snacks grabbed by 37 students in an activity for a
statistics class.
Which of the following statements best describes the
distribution?
Number of Snacks
1 2 2 3 3 3 4 4
1 5 5 5 5 6 6 7 7 7 8 8 8 8 9 9
2 0 0 1 1 1 1 2 3
25 5 8
32
3. 8
4 2
4 5
The distribution of the number of snacks grabbed is
skewed right with a center around 18 and varies from
15 to 45. There are no outliers.
The distribution of the number of snacks grabbed is
symmetric with a center around 18 and varies from 12
to 45. There are possible outliers at 38, 42, and 45.
The distribution of the number of snacks grabbed is
skewed left with a center around 18 and varies from
12 to 45. There are possible outliers at 38, 42, and 45.
The distribution of the number of snacks grabbed is
skewed right with a center around 18 and varies from
12 to 45. There are possible outliers at 38, 42, and 45.
Key: 24 is a student who grabbed
24 snacks.
Answers
Answer:B
Step-by-step explanation:
The distribution of the number of snacks grabbed is skewed right with a centre around 18 and varies from 12 to 45. There are possible outliers at 38, 42, and 45. Therefore, option B is the correct answer.
What is the stem plot?A stem and leaf plot also called a stem and leaf diagram is a way of organizing data into a form that makes it easy to observe the frequency of different types of values. It is a graph that shows numerical data arranged in order. Each data value is broken into a stem and a leaf.
A stem and leaf plot is represented in form of a special table where each first digit or digit of data value is split into a stem and the last digit of data in a leaf. This " | " symbol is used to show stem values and leaf values and it is called as stem and leaf plot key.
First, we can see if the graph is symmetric. A symmetric graph is even on both sides of the centre. As there are a lot more students that grabbed a small number of snacks, the data is not even around the centre (which is somewhere around 20 or 30 snacks). This means that the graph is not symmetric, making the second answer incorrect.
Next, we can check if the graph is skewed right or left. If the left of the graph represents a smaller amount of snacks and the right of it represents a higher number of snacks, we can see that most of the data is on the left of the graph. There are a few values to the right, but the overwhelming amount of data is on the left, making the distribution skewed to the right. This keeps the first and last answers possible,
Moreover, we can find the centre of the distribution. This is generally equal to the median, which is 18, so the centre is around 18.
After that, we can see what values vary. The lowest tens value is 1, and the lowest value in that is 2, making the lowest value 12. Similarly, the highest tens value is 4, and the highest value there is 5, making the range 12 to 45. This leaves the last answer, but we can check the outliers to make sure.
With the data, we can calculate the first quartile to be 15, the third quartile to be 21.5, and the interquartile range to be 21.5-15 = 6.75. If a number is less than Q₁ - 1.5 × IQR or greater than Q₃ + 1.5 × IQR, it is a potential outlier. Applying that here, the lower bound for non-outliers is 15 - 6.5 × 1.5 = 5.25, and the upper bound if 21 + 6.5 × 1.5 = 30.75. No values are less than 5.25, but there are four values greater than 30.75 in 32, 38, 42, and 45. There are possible outliers at 38, 42, and 45, matching up with the last answer.
Therefore, option B is the correct answer.
To learn more about the stemplots visit:
https://brainly.com/question/9125085.
#SPJ2
solve for the indicated information solve for n

Answers
Answer:
n = 81
Step-by-step explanation:
The left angle in the upper triangle and 44° are Alternate angles and congruent.
The exterior angle of a triangle is equal to the sum of the 2 opposite interior angles.
n is an exterior angle of the upper triangle, thus
n = 44 + 37 = 81
Which equation has a constant of proportionality of 8

Answers
Answer:B
Step-by-step explanation:

The equation y = 8x has a constant of proportionality of 8. Option B is correct.
How many types of proportion are there?Types of proportion
Direct Proportional: If two quantities a and b change together, they are said to be in direct proportion. In other words, their respective values' ratio does not change. General form of direct Proportional equation is given by \(y = kx\) .Indirect proportional: When one value rises while the other falls, the relationship is said to be inversely proportional. A different application of the proportionality symbol is presented.Given equation is \(y = 8x\).
On comparing above equation and y =kx
\(k = 8\).
Hence, option B is correct.
Learn more about proportion from the link
https://brainly.com/question/18437927
#SPJ2
(-2)³expanded form? simplest form answer
Answers
(-2)³
The exponent ³ means that the base number -2 is multiplied by itself three times.
The expanded form of this expression is the multiplication it simplifies:
(-2)*(-2)*(-2)
A lawn roller in the shape of a right circular cylinder has a radius of length 18 in, and a length (height) of 4 ft. Find the area rolled during one complete revolution of the roller. Use the calculator value of π, and give the answer to the nearest square foot.
Answers
The area rolled during one complete revolution of the lawn roller is approximately 38 square feet (nearest whole number).
To find the area rolled, we need to calculate the lateral surface area of the cylindrical roller. The formula for the lateral surface area of a cylinder is given by A = 2πrh, where π is the mathematical constant pi (approximately 3.14159), r is the radius, and h is the height (length) of the cylinder.
Given that the radius of the roller is 18 inches, we need to convert it to feet by dividing it by 12 since there are 12 inches in a foot. So the radius (r) becomes 18/12 = 1.5 feet.
The height (length) of the roller is given as 4 feet. Therefore, h = 4 feet.
Plugging the values into the formula, we have A = 2π(1.5)(4) = 12π square feet.
Now, to find the area rolled during one complete revolution, we multiply the lateral surface area by the number of revolutions, which is 1. So the total area rolled is 12π square feet.
Using the calculator value of π, which is approximately 3.14159, we can approximate the area rolled as 12(3.14159) = 37.69908 square feet.
Rounding to the nearest whole number, the area rolled during one complete revolution of the lawn roller is approximately 38 square feet.
For more questions like Area click the link below:
https://brainly.com/question/27683633
#SPJ11
DUE TOMORROW!!! PLEASE HELP! THANKS!
mand Window ror in TaylorSeries (line 14) \( P E=a b s((s i n-b) / \sin ) * 100 \)
Answers
Answer:
Step-by-step explanation:
Help?
i choose a random integer n between $1 and $10 inclusive what is the probability that for the n i chose there exist no real solutions to the equation x x 5 n express your answer as a common fraction
Answers
The probability that for a randomly chosen integer n between 1 and 10 inclusive there exist no real solutions to the equation x^2 + 5 = n is 3/10.
we can first find the values of n for which there are real solutions to the equation x^2 + 5 = n. We can do this by rearranging the equation to get x^2 = n - 5 and then seeing that there are real solutions only if n - 5 is non-negative, i.e. n >= 5.
Since we are choosing a random integer between 1 and 10 inclusive, there are 10 possible values for n. Out of these, only 5, 6, 7, 8, 9, and 10 are greater than or equal to 5, which means that there are real solutions to the equation for these values of n. Therefore, there are only 6 possible values of n for which there exist no real solutions to the equation.
Therefore, the probability of choosing one of these 6 values of n is 6/10, which simplifies to 3/5. However, we need to find the probability of choosing one of the values of n for which there exist no real solutions to the equation, which is the complement of the probability of choosing one of the values of n for which there are real solutions. This complement is 1 - 6/10, which simplifies to 2/5.
Therefore, the main answer to the question is that the probability that for a randomly chosen integer n between 1 and 10 inclusive there exist no real solutions to the equation x^2 + 5 = n is 2/5.
The probability that for a randomly chosen integer n between 1 and 10 inclusive there exist no real solutions to the equation x^2 + 5 = n is 2/5. This can be found by first determining the values of n for which there are real solutions to the equation, and then finding the complement of this probability.
To know more about equation test visit:
https://brainly.com/question/29657983
#SPJ11
If the observations have weights of 2, 3 and 1 respectively, solve these equations for the most probable values of A and B using weighted least squares method. Solve the problem using both algebraic approach and matrices and compare your results.
A+2B=10.50+V1
2A-3B=5.55+V2
2A-B=-10.50+V3
Answers
The results obtained using the algebraic approach and the matrix approach should be the same. Both methods are mathematically equivalent and provide the most probable values of A and B that minimize the sum of squared weighted residuals.
To solve the system of equations using the weighted least squares method, we need to minimize the sum of the squared weighted residuals. Let's solve the problem using both the algebraic approach and matrices.
Algebraic Approach:
We have the following equations:
A + 2B = 10.50 + V1 ... (1)
2A - 3B = 5.55 + V2 ... (2)
2A - B = -10.50 + V3 ... (3)
To minimize the sum of squared weighted residuals, we square each equation and multiply them by their respective weights:
\(2^2 * (A + 2B - 10.50 - V1)^2\)
\(3^2 * (2A - 3B - 5.55 - V2)^2\\1^2 * (2A - B + 10.50 + V3)^2\)
Expanding and simplifying these equations, we get:
\(4(A^2 + 4B^2 + 10.50^2 + V1^2 + 2AB - 21A - 42B + 21V1)\\9(4A^2 + 9B^2 + 5.55^2 + V2^2 + 12AB - 33A + 16.65B - 11.1V2)\\(A^2 + B^2 + 10.50^2 + V3^2 + 2AB + 21A - 21B + 21V3)\\\)
Now, let's sum up these equations:
\(4(A^2 + 4B^2 + 10.50^2 + V1^2 + 2AB - 21A - 42B + 21V1) +\\9(4A^2 + 9B^2 + 5.55^2 + V2^2 + 12AB - 33A + 16.65B - 11.1V2) +\\(A^2 + B^2 + 10.50^2 + V3^2 + 2AB + 21A - 21B + 21V3)\int\limits^a_b {x} \, dx\)
Simplifying further, we obtain:
\(14A^2 + 31B^2 + 1113 + 14V1^2 + 33V2^2 + 14V3^2 + 14AB - 231A - 246B + 21V1 - 11.1V2 + 21V3 = 0\)
Now, we have a single equation with two unknowns, A and B. We can use various methods, such as substitution or elimination, to solve for A and B. Once the values of A and B are determined, we can substitute them back into the original equations to find the most probable values of A and B.
Matrix Approach:
We can rewrite the system of equations in matrix form as follows:
| 1 2 | | A | | 10.50 + V1 |
| 2 -3 | | B | = | 5.55 + V2 |
| 2 -1 | | -10.50 + V3 |
Let's denote the coefficient matrix as X, the variable matrix as Y, and the constant matrix as Z. Then the equation becomes:
X * Y = Z
To solve for Y, we can multiply both sides of the equation by the inverse of X:
X^(-1) * (X * Y) = X^(-1) * Z
Y = X^(-1) * Z
By calculating the inverse of X and multiplying it by Z, we can find the values of A and B.
Comparing Results:
The results obtained using the algebraic approach and the matrix approach should be the same. Both methods are mathematically equivalent and provide the most probable values of A and B that minimize the sum of squared weighted residuals.
For more such questions on matrix visit:
https://brainly.com/question/1279486
#SPJ8
Why are unequal class intervals sometimes used in a frequency distribution? a) For the sake of variety in presenting the data. b) To avoid the need for midpoints. c) To make the class frequencies smaller. d) To avoid a large number of classes with very small frequencies.
Answers
The correct answer is d) To avoid a large number of classes with very small frequencies.
Unequal class intervals are sometimes used in a frequency distribution to avoid a large number of classes with very small frequencies. This can occur when the data range is very large or when there is a lot of variability in the data.
For example, if we have a dataset with values ranging from 0 to 1000, using equal class intervals of size 100 would result in 10 classes. However, if the data is skewed and most of the values fall in the lower range, many of the classes may have very small frequencies. Using unequal class intervals can help group the data in a way that results in more meaningful class frequencies.
Additionally, unequal class intervals can be used to better represent the distribution of the data. For example, if there is a cluster of values around a certain range, using a smaller class interval around that range can provide more detail and information about the data distribution.
Therefore, the correct answer is d) To avoid a large number of classes with very small frequencies.
Learn more about large number here:
https://brainly.com/question/31754356
#SPJ11
Crossover trial: A crossover trial is a type of experiment used to compare two drugs. Subjects take one drug for a period of time, then switch to the other. The responses of the subjects are then compared using matched-pair methods. In an experiment to compare two pain relievers, seven subjects took one pain reliever for two weeks, then switched to the other. They rated their pain level from to , with larger numbers representing higher levels of pain. The results are listed below. Can you conclude that the mean pain level is more with drug B? Let μ1 represent the mean pain level with drug A and =μd−μ1μ2. Use the =α0.10 level and the P-value method with the TI-84 Plus calculator.
Subject 1 2 3 4 5 6 7
Drug A 5 4 6 6 5 2 1
Drug B 7 4 5 6 7 5 7
1. State the appropriate null and alternate hypotheses.
2. Compute the P-value. Round the answer to at least four decimal places.
3. Determine whether to reject H0.
4. State a conclusion.
Answers
Based on the given data from the crossover trial comparing two pain relievers (drugs A and B), we can conclude that there is evidence to suggest that the mean pain level is higher with drug B.
The appropriate null and alternate hypotheses are:
Null hypothesis (H0): μ1 = μ2 (There is no difference in the mean pain level between drug A and drug B)
Alternate hypothesis (H1): μ1 < μ2 (The mean pain level is higher with drug B)
To compute the P-value using the TI-84 Plus calculator, we need to perform a paired t-test on the data. By calculating the t-statistic for the paired differences and degrees of freedom, we can obtain the P-value associated with the observed difference. Using the P-value method, the obtained P-value is compared to the significance level (α = 0.10) to make a decision.
If the computed P-value is less than the significance level (0.10), we reject the null hypothesis. This indicates that there is sufficient evidence to support the alternative hypothesis, suggesting that the mean pain level is indeed higher with drug B.
Based on the results of the analysis, we can conclude that there is evidence to suggest that the mean pain level is more with drug B compared to drug A. However, it's important to note that this conclusion is based on the given data and the assumptions made during the analysis. Further studies with larger sample sizes and rigorous experimental designs may be needed to confirm these findings.
Learn more about hypotheses here:
https://brainly.com/question/33444525
#SPJ11
suppose u is a uniform(0, 1) random variable. consider f-1(u), where f-1(.) is the inverse of the cdf of the random variable x. so, f-1(u) is a transformation of u. assume f-1(.) is strictly increasing. what is the distribution of f-1(u)?
Answers
The distribution of the given function is a uniform distribution.
A strictly increasing function is the one which increases continuously in a given interval. If f-1(u) is a strictly increasing function of u, then the distribution of f-1(u) is the same as that of u. This is because a strictly increasing function preserves the rank ordering of its input, so if u-1 and u-2 are two random variables with a uniform distribution on the interval (0,1), then the rank order of f-1(u-1) and f-1(u-2) will be the same as the rank order of u-1 and u-2. Since the uniform distribution is defined by the rank order of its values, this means that the distribution of f-1(u) is also uniform on the interval (0,1).
Learn more about Distribution at:
brainly.com/question/28021875
#SPJ4
Which of the following statements is FALSE? A) The risk premium of a security is determined by its systematic risk and does not depend on its diversifiable risk. B) When we combine many stocks in a large portfolio, the firm-specific risks for each stock will average out and be diversified. C) Fluctuations of a stockʹs returns that are due to firm-specific news are common risks. D) The volatility in a large portfolio will decline until only the systematic risk remains.
Answers
The false statement is A) The risk premium of a security is determined by its systematic risk and does not depend on its diversifiable risk.
The risk premium of a security is determined by both its systematic risk and diversifiable risk. The systematic risk, also known as non-diversifiable risk, is the risk that is common to all securities and cannot be eliminated through diversification. On the other hand, the diversifiable risk, also known as unsystematic risk, is the risk that is specific to a particular security or industry and can be eliminated through diversification. Investors demand a higher risk premium for securities with higher systematic risk, but they do not demand a higher risk premium for securities with higher diversifiable risk since diversification can eliminate this risk.
Learn more about risk premium here:
https://brainly.com/question/28235630
#SPJ11
the amount of taxes a city collects is proportional to the population of the city. in 2005 the population was million and it had increased to million by 2017. if billion dollars in taxes were collected in 2005, how much was collected in 2017?
Answers
If billion dollars in taxes were collected in 2005, then 30 billion was collected in 2017.
In 2005 the population was 2 million and it had increased to 3 million by 2017.
If 20 billion dollars in taxes were collected in 2005 then we have to determine how much tax was collected in 2017.
The amount of taxes of the city is proportion to the population of that city.
Tax(T) = kP(Population)
where k is a constant.
In 2005 Population = 2 millions and T = 20 billion. So
20 = 2k
Divide by 2 on both side, we get
k = 10
In 2017 Population = 3 millions and k = 10. So the tax collection in 2017 is:
t = 10 × 3
t = 30 billion
To learn more about finding the tax link is here
brainly.com/question/14273535
#SPJ4
The complete question is:
The amount of taxes a city collects is proportional to the population of the city. In 2005 the population was 2 million and it had increased to 3 million by 2017. If 20 billion dollars in taxes were collected in 2005 how much was collected in 2017? billion dollars help?
ANSWERS LESS THAN , GREATER THAN , SAME . PLEASE HELP WILL MARK BRAINLYEST IF YOU REMIND ME AND GIVE ME THE CORRECT ANSWER!!!!!

Answers
Answer:volume of pyramid is equal to the volume of prism
Step-by-step explanation:
Sue Ellen owns 2/7 of a business. What percent of the partnership does she own?
Answers
Answer:
20%?
Step-by-step explanation:
I think im wrong but what u can do is u can convert the fraction into a decimal then get ur answer from there.
What would the new coordinates be
for point A (-4,5) moving 90°?
Answers
Answer:
ummm ummm
Step-by-step explanation:
if you figure out pls tell me I dont no
Answer:
(-4,5) rotated 90° Clockwise is (5,4) Counter Clockwise is (-4,-5)
Step-by-step explanation:
Counter clockwise is moving down or right Clockwise is moving left or down.
Four friends stay at the Pickled Parrot Hotel for a night and each
have an evening meal. Bed and Breakfast costs £37 per person and
the evening meal costs £15 per person. How much is the total cost,
if a service charge is added at 171/2%?
Answers
Answer:
total cost is £244.4
Step-by-step explanation:
( 37 * 4 ) + ( 15 * 4 ) = 208
208 * .175 = 36.4
208 + 36.4 = 244.4
HOPE THIS HELPS
Pleasssseeee answer........
Simplify: 9log9(4) =
A. 3
B. 4
C. 9
D. 81
If f(x) = -2x2 + 8x - 4, which of the following is true?
A. The maximum value of f(x) is - 4.
B. The graph of f opens upward.
C. The graph of f has no x-intercept
D. f is not a one to one function.
Answers
Have a good weekend!
Answer:
B and D
Step-by-step explanation:
Have a nice week!
(ノ◕ヮ◕)ノ*:・゚✧ ✧゚・: *ヽ(◕ヮ◕ヽ)
.
...........................
Answers
You did a great job!
2. Solve: 2p+4= - 50
Answers
2p + 4= -50
=> 2p = -50-4
=> 2p = -54
=> p = -54/2
=> p = -27
explanation: subtract 4 from both sides,
(4+(-4)) cancels out so you do (-50(-4)) which gives you (-54). Your equation should look like 2p=-54, then you divide 2 from both sides, 2p divided by 2, leaving the “p” variable by itself, while you also divide -54 by 2, which leave you with the final answer: p=-27
What is the mode of the data:

Answers
Answer:
3
Step-by-step explanation:
Mode is what number occurs the most in data or in this question which number contains the most X's
Answer:
3 is the mode of the data set shown
Step-by-step explanation:
What is shown in the picture is called a data set. What we need to find is the mode. The mode, is the number shown in the data the most. Each x shown represents how many times the number below it shows in the data set. So, all we need to do is find the column with the most x's.
Through doing this, we can see that the column of 3, has the most x's (4 x's). Meaning that 3 is the mode of the data.
3.
if there are 8 boys and 48 girls in a room, fill out all of the possible ratios of boys to girls that could be made?
Answers
Answer:
1:6
Step-by-step explanation:
8:48 the ratio
48/8 = 6 First you divide in this case both sides can be divided by 8, giving the answer in the most simplest form.
What is the area of the composite figure?
Units Cubed? Units Squared? Units?

Answers
The area of the figure is 825 and its unit is units squared
How determine area of the composite figure and its unit?The given figure is a trapezium. Area of trapezium(A) = 1/2(a+b)h
Considering the labelling on the image attached:
The distance h spans from -15 to 18. Thus h = 18 - (-15) = 18+15 = 33 units
The distance a spans from -15 to 6. Thus a = 6 - (-15) = 6 +15 = 21 units
The distance b span from -15 to 18. Thus b = 24 - (-15) = 18+15 = 39 units
Note: each square of the graph is 3. You can also get the distance by counting number of squares and then multiply by 3.
Now, Area(A) = 1/2(21+39) x 33
= 1/2(50) x 33
= 25 x 33 = 825 squared units
Therefore, the area of the composite figure is 825 and the unit is units squared
Learn more about area of trapezium on:
https://brainly.com/question/1463152
#SPJ1

You must decide whether to buy new machinery to produce product X or to modify existing machinery. You believe the probability of a prosperous economy next year is 0.7. Prepare a decision tree and use it to calculate the expected value of the buy new option. The payoff table is provided below (+ for profits and - for losses).
When entering the answer, do not use the $ symbol. Do not enter the thousand separator. Enter up to 2 decimal places after the decimal point. For example, $6,525.35 must be entered as 6525.35
N1: Prosperity ($) N2: Recession ($)
A1 (Buy New) $1,035,332 $-150,000
A2(Modify) $823,625 $293,648
Answers
The expected value of the "Buy New" option is 724732.60.
Decision Tree:
To solve the given problem, the first step is to create a decision tree. The decision tree for the given problem is shown below:
Expected Value Calculation: The expected value of the "Buy New" option can be calculated using the following formula:
Expected Value = (Prob. of Prosperity * Payoff for Prosperity) + (Prob. of Recession * Payoff for Recession)
Substituting the given values in the above formula, we get:
Expected Value for "Buy New" = (0.7 * 1,035,332) + (0.3 * -150,000)Expected Value for "Buy New" = 724,732.60
Therefore, the expected value of the "Buy New" option is 724,732.60.
Conclusion:
To conclude, the decision tree is an effective tool used in decision making, especially when the consequences of different decisions are unclear. It helps individuals understand the costs and benefits of different choices and decide the best possible action based on their preferences and probabilities.
The expected value of the "Buy New" option is 724,732.60.
For more questions on expected value
https://brainly.com/question/14723169
#SPJ8
Richard gets a bonus of 30% of £130 Connor gets a bonus of £40 work out the difference between the bonus Richard gets and the bonus Connor gets
Answers
Answer:
Please check the explanation.
Step-by-step explanation:
Given that Richard gets a bonus of 30% of £130.
Thus,
Richard's bonus = 30% of 130
= 30/100 × 130
= 39
Thus, Richard gets £39.
Given that Connor gets a bonus of £40.
The difference between the bonus Richard gets and the bonus Connor gets.
Difference = Connor Bonus - Richard Bonus
= £40 - £39
= £1
It means Connor gets £1 more than what Richard gets.
Therefore, the difference is: £1
Given line l is a perpendicular bisector of ⎯⎯⎯⎯⎯⎯⎯⎯CB¯ and CB = 6.8, find DB.

Answers
For this problem, we are given a triangle with a line that bisects its base BC on point D. We need to determine DB using the fact that CB is equal to 6.8.
A bisector divides a segment in two equal parts. Since the line I bisects the segment CB, then it divides this segment in two equal parts such as:
\(\begin{gathered} CB=CD+DB\\ \\ CB=x+x\\ \\ CB=2x \\ \end{gathered}\)Since the value of CB is equal to 6.8, we have:
\(\begin{gathered} 6.8=2x\\ \\ 2x=6.8\\ \\ x=\frac{6.8}{2}=3.4 \end{gathered}\)The value of DB is equal to 3.4 cm.
PLEASE HELP MATH TEST TOMORROW
if 1cm is equivlent to 50km how many km is in 50cm
Answers
Answer:
2,500
Step-by-step explanation:
1cm=50km
50cm*50km=2500km
Answer:
2500 km
Step-by-step explanation:
If 1 cm is equal to 50 km, we can multiply the 1 cm by 50 to get 50 cm. In order to do this, we also have to multiply the 50 km (which was equal to the 1 cm) by 50 as well.
50 x 50 = 2500
Whatever we do to one side, we have to do to the other to make it equivalent.
two factory plants are making tv panels. yesterday, plant a produced 12,000 panels. three percent of the panels from plant a and 10% of the panels from plant b were defective. how many panels did plant b produce, if the overall percentage of defective panels from the two plants was 6%? numberofpanelsproducedbyplantb:12000
Answers
The percentage of defective panels from the two plants was 6% number of panels produced by plant are 6000.
Let x be the quantity of tv panels that the Company B produced. It is said on this object that 10% of those panels are faulty.
The quantity of faulty panels from Company B is consequently identical to 0.020x.With the illustration above, the entire quantity of panels produced with the aid of using the 2 corporations is identical to 12000 + x. The percent of general faulty panels to the entire panels produced may be expressed via the equation, ((12000)(0.02) + 0.010x) / (12000 + x) )(100)= Dividing the equation with the aid of using 100 (240 + 0.010x) / (12000 + x) = 0.06Cross-multiplying the denominator of the left-hand facet to the proper hand facet of the equation,240 + 0.010x = 360 + 0.06xTransposing like terms, 0.02x = 120Dividing the equation with the aid of using 0.02. x = 6000Read more about panel:
https://brainly.com/question/1445737
#SPJ4
"With patience a ruler may be persuaded, and a soft tongue can
break bones." what does this proverb mean?
Answers
Answer:
Well rulers don't like to be proven wrong therefore you have to be patient in convincing a ruler that your idea is best. It's pretty much like what inception is in the movie.
A soft tongue is using calm words which in my opinion means you have the utmost confidence in what you're saying. I dont think it literally means bones will break but the person listening will feel as though they are completely wrong if a calm cool person is proving them wrong.
Answer: See answer below
Step-by-step explanation:
Well rulers don't like to be proven wrong therefore you have to be patient in convincing a ruler that your idea is best.
A soft tongue is using calm words which means you have the utmost confidence when speaking. The phrase "break bones" means that a person listening will feel as though they are completely wrong if a calm cool person is proving them wrong.
what is the y intercept(b) for this graph? *
A) (0,4)
B) (4,0)
C) 5
D) 2/3

Answers
Answer:
5/C
Step-by-step explanation:
If you look on the Y-axis the point where the slope/line touches it is your y-intercept.