Use long division to find the decimal from of the building’s height in miles write the answer to four decimals places
Answers
The decimal from of the building’s height in miles to four decimals places is 0.1667 miles.
What is polynomial?In mathematics, a polynomial is an expression consisting of variables and coefficients, combined using the operations of addition, subtraction, and multiplication, but not division by a variable. Polynomials are used to describe a wide range of mathematical phenomena, such as curves and functions.
Here,
To convert the building's height of 880 feet to miles, we need to divide 880 by the number of feet in one mile, which is 5,280. We can use long division as follows:
0.1666 (repeating)
_________________
5280 | 880.0000
7920
-----
8800
8448
----
3520
3168
----
3520
3168
----
3520
3168
----
3520
To know more about polynomial,
https://brainly.com/question/11536910
#SPJ1
Complete question:
Use long division to find the decimal form of the building’s height in miles. The buildings height is 880 feet. Write the answer to four decimal places.
Related Questions
y:1998=9
tyt4hrhttrf1tgr
gt
gr
t
g
g
g
t
tbvdfghn
h
gbfv
dgb fh
bfv
bc nhg1n
gbfvcvfb
f
bv
f4
nbtgyh
h
gf
ffr
g
rg
g
srs
g
rf
g
s
e
gd
f
f
f
f
r
eg
r
ẻgd
df
f
rr
ưty
r
rt
t14
y
y74
h
gt
hy
ht
h
y
h
5t
ggb
thh
Answers
Answer:
ether that gibberish or I'm an idiot
help me pls
a s a p!

Answers
Answer:
45:30:100
Step-by-step explanation:
the answer would be 9:6:20
1) Quotient of eight and two.
Answers
Answer:
4
Step-by-step explanation:
The quotient of eight and two is the same as the equation 8/2 which equals to 4.
Quotient means divide.
8 / 2 = 4
Best of Luck!
In the U.S., shoe sizes are defined differently for men and women, but in Europe, both sexes use the same shoe size scale. The accompanying histogram shows the European shoe sizes of 269 male and female college students, converted from their reported U.S. shoe sizes. What might be the problem with either the mean or the median as a measure of center?
Answers
To accurately represent the shoe sizes for men and women separately, it would be better to compute the mean or median shoe size for each group separately and compare them.
The problem with either the mean or the median as a measure of center in this case is that the data is not separated by gender, and the shoe size distributions for men and women are likely to be different. Therefore, computing the mean or median shoe size across all students may not accurately represent the typical shoe size for men or women separately.
For example, if the men in the sample have, on average, larger shoe sizes than the women, then the mean shoe size across all students may be biased towards the larger sizes, even though the majority of the students are women. On the other hand, if there are a few male students with very large shoe sizes, then the median shoe size across all students may be biased towards the larger sizes as well, even if most of the students are women with smaller shoe sizes.
To accurately represent the shoe sizes for men and women separately, it would be better to compute the mean or median shoe size for each group separately and compare them. Alternatively, a better measure of center might be to report the mode, which represents the most common shoe size in the data.
Learn more about median here https://brainly.com/question/28060453
#SPJ4
Discuss the difference between r and p.
Choose the correct answers below.
r represents the
p represents the
sample correlation coefficient.
critical value for the correlation coefficient.
population correlation coefficient.
Click to select your answer(s)
1-35 of 35
Type here to search
o He
Answers
The differences that exists between r and p are:
r represents the sample correlation coefficientp represents the population correlation coefficientWhat is the sample correlation coefficient?When points in a scatter plot are plotted against a linear regression line based on those points, as in the example when solving for cumulative savings over time, the sample correlation coefficient (r) is a measurement of how closely the points are associated.
What is the population correlation coefficient?The correlation coefficient (ρ) is a metric for estimating how closely two variables' movements are related. The Pearson product-moment correlation is used to calculate the most popular correlation coefficient, which is used to assess the linear relationship between two variables.
Read more on sample correlation coefficient here:https://brainly.com/question/29120011
#SPJ1
1) Rafe is purchasing potato chips for his family reunion. He is expecting 67 family members to attend the gathering. The
local grocery store sells individual bags of chips in cartons of 22. Estimate the fewest number of cartons that Rafe should
buy to be sure that everyone gets at least one bag of chips.
A. 2
B. 4
C. 6
D. 8
Answers
Answer:
4
Step-by-step explanation:
Write an equivalent expression for 2(1.7x + 3.3) + 5(2.6x + 1.4) by combining like terms
Answers
Answer:
16.4x + 13.6
Step-by-step explanation:
Equivalent Expressions
Algebraic expressions can be given in different forms when applying properties of the basic operations.
The given expression is:
2(1.7x + 3.3) + 5(2.6x + 1.4)
Multiplying both parentheses by the outer factor:
3.4x + 6.6 + 13x + 7
Combining like terms:
16.4x + 13.6
The original and the final expressions are equivalent because they produce the same results
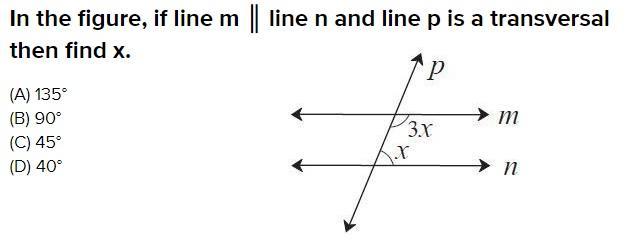
Given m||n, find the value of x.
135
Answers
Answer: Option C.
Step-by-step explanation:
Let as consider the complete question is same as question shown in the below figure.
In the figure m║n.
If a transversal line intersect two parallel lines then same sided interior angles are supplementary angles and their sum is 180 degrees.
\(3x+x=180^{\circ}\)
\(4x=180^{\circ}\)
Divide both sides by 4.
\(x=\dfrac{180^{\circ}}{4}\)
\(x=45^{\circ}\)
The value of x is 45 degrees.
Therefore, the correct option is C.
Your friend has $100 when he goes to the fair. he spends $10 to enter the fair and $20 on food. rides at the fair cost $2 per ride. which function can be used to determine how much money he has left over after x rides? f(x) = −2x 70 f(x) = 2x 70 f(x) = −2x − 70 f(x) = −30x $100
Answers
The function which can be used to determine the amount of money he has left over after x rides is f(x)=-2x+70.
This function is linear. A linear variable function can be written in the form of y=f(x)=a+bx, where a and b are integers and x, is the variable. This function has one independent variable and one dependent variable. In the above given function y=f(x)=a+bx; y is the dependent variable and x is the independent variable.
Here since x number of rides are taken and the cost per ride is x so the total cost of x rides is given as 2x.
Since there is a total of $100 and an amount of ($10+$20=$30) is spent on entry and food respectively.
Therefore, total amount left after all the expenses can be expressed as:
f(x)=100-(30+2x)
f(x)=70-2x
f(x)=-2x+70
Therefore, function which can be used to determine the amount of money he has left over after x rides is f(x)=-2x+70.
Learn more about Function at:
brainly.com/question/10439235
#SPJ4
Evaluate yz + x² x=3.2, y=6.1, z=0.2
Answers
Answer:
Step-by-step explanation:
To evaluate the given expression, we need to substitute the given values for x, y, and z. The expression becomes:
yz + x²
Substituting the given values, we get:
(6.1 * 0.2) + (3.2^2)
This simplifies to:
1.22 + 10.24
Therefore, the value of the expression is approximately 11.46.
11.46
gimme brainlyest gang
i need in depth help in how to solve step functions.Sketch the graph of the given function on the interval t equal to or > 0g(t) = u1(t) + 2u3(t)-6u4(t)
Answers
Step functions are functions that have different values for different intervals of the input variable. They are often used to model situations where a quantity changes abruptly at certain points in time.
In this case, the function g(t) is defined using three different step functions: u1(t), u3(t), and u4(t). Let's start by looking at each of these step functions in turn: u1(t) is the unit step function, which is defined as:
\(u1(t) = { 0 if t < 0\)
\({ 1 if t > = 0\)
In other words, u1(t) is equal to 0 for negative values of t, and 1 for non-negative values of t. This means that the graph of u1(t) is a horizontal line at y=0 for t < 0, and a horizontal line at y=1 for t >= 0. Here's what the graph looks like:
u3(t) is another unit step function, but with a shift of 3 units to the right:
\(u3(t) = { 0 if t < 3\)
\({ 1 if t > = 3\)
This means that the graph of u3(t) is a horizontal line at y=0 for t < 3, and a horizontal line at y=1 for \(t > = 3\). Here's what the graph looks like:
u4(t) is another unit step function, but with a shift of 4 units to the right:
\(u4(t) = { 0 if t < 4\)
\({ 1 if t > = 4\). This means that the graph of u4(t) is a horizontal line at y=0 for t < 4, and a horizontal line at y=1 for \(t > = 4.\) Here's what the graph looks like:
Now let's look at the function g(t) \(= u1(t) + 2u3(t) - 6u4(t)\). This function is a linear combination of the three-step functions we just examined, with different coefficients for each one.
For t < 0, all three step functions are equal to 0, so g(t) is also equal to 0. For \(t > = 0\), the values of the three-step functions depend on the value of t relative to the shifts in u3(t) and u4(t).
If t < 3, then \(u3(t) = 0\) and \(u4(t) = 0,\) so \(g(t) = u1(t)\)= \(1.\)
If 3 <= t < 4, then \(u3(t) = 1\) and \(u4(t) = 0\), so \(g(t) = u1(t) + 2u3(t) = 1 + 2 = 3.\)
If t >= 4, then \(u3(t) = 1\) and \(u4(t) = 1\), so \(g(t) = u1(t) + 2u3(t) - 6\)
To learn more about Step functions, visit her
https://brainly.com/question/29908912
#SPJ4

Chase and Simon (1973) studied the memory of chess novices and experts for positions of chess pieces on a chessboard. Although experts generally have a far better memory for chess positions than do novices, they found that the novices performed as well or better than the experts when asked to recall random arrangements of chess pieces on the chessboard. The random arrangements included arrangements that could not possibly occur in a real game of chess. Why did novices do as well as experts when the pieces were arranged at random
Answers
Chase and Simon (1973) conducted a study on the memory of chess novices and experts for positions of chess pieces on a chessboard. They found that although experts generally have a better memory for chess positions than novices, novices performed equally or even better than experts when asked to recall random arrangements of chess pieces on the chessboard, even if the arrangements couldn't occur in a real game of chess.
One possible explanation for this phenomenon is that experts rely heavily on their knowledge of typical chess positions and patterns to remember the positions of the pieces. However, when the pieces are arranged randomly, these patterns are disrupted, and experts may struggle to apply their existing knowledge effectively. On the other hand, novices may not have developed strong patterns or strategies yet, so they approach the task with a more flexible mindset and are less affected by the random arrangement. They may use more general memory strategies, such as chunking or grouping the pieces together, which can be useful for recalling random arrangements.
In summary, novices may perform as well as experts when the pieces are arranged randomly because they rely less on established patterns and can use more general memory strategies to recall the positions.
Learn more about chess: https://brainly.com/question/29897063
#SPJ11
How in statistics the bayesian approach is different from the frequentist approach?.
Answers
The statistics in the Bayesian approach is different from the frequentist approach because in the Bayesian approach the parameters for estimation is been treated as random variables.
What is the differences that can be associated with the bayesian approach and frequentist approach?The differences that can be associated with the bayesian approach and frequentist approach is that the Bayesian approach make use of the parameters that is about to be treated as a random variable.
It should be noted that frequentist approach, do make use of the fixed. Random variables in dealing with the parameters for estimation.
Read more about Bayesian at:
https://brainly.com/question/3797946
#SPJ1
The selling price of a $10,000 5-year bond will be less than $10,000 if the A. Coupon rate is less than the market interest rate B. Coupon rate is greater than the market interest rate C. Coupon rate is equal to the market interest rate D. Maturity date is less than 5 years
Answers
The correct answer is A. The selling price of a bond is affected by the coupon rate and the market interest rate.
If the coupon rate is less than the market interest rate, investors will not be interested in buying the bond because they can get a higher return elsewhere. This results in the selling price of the bond being less than its face value of $10,000.
The selling price of a $10,000 5-year bond will be less than $10,000 if the:
A. Coupon rate is less than the market interest rate
This is because when the coupon rate (the interest paid by the bond) is lower than the market interest rate, investors would prefer to invest in other options that offer a higher return. Therefore, to attract buyers, the bond's selling price would be discounted to compensate for the lower coupon rate.
Learn more about price:
brainly.com/question/19091385
#SPJ11
11. The data are the number of text messages you send a day.
Find the mean, median, and mode of the data.
10, 12, 20, 8, 6, 10, 18
Answers
Answer:
mean= 12
median= 10
mode= 10
Step-by-step explanation:
mean: add up all values, then divide by how many values you have(84/7=12)
median: when sorted, value in middle(See pic)
mode: value that appears most

PLS HELP ASAP. Which of the following is 55/42 closest to? 1, 0, 1/2
Answers
Answer:
1
Step-by-step explanation:
55/42
42/42 + 13/42
Making approximations
1 + 0
1
¡¡ANSWER ME FIRST¡¡
Can you please answer these questions?
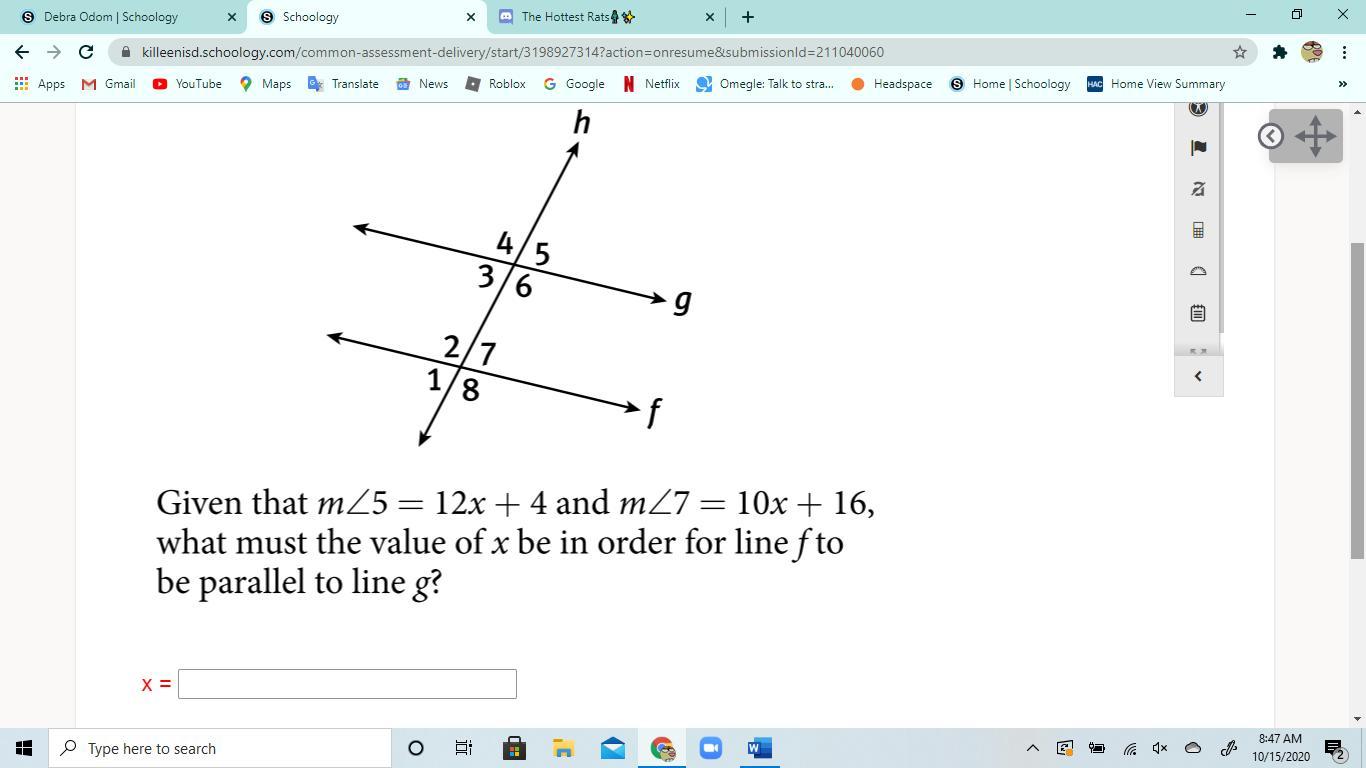

Answers
Answer:
x= 6
Step-by-step explanation:
\(12x +4 = 10x+16 \\\)
You will subtract 10x from 12x and get 2x
\(2x + 4 = 16\)
Subtract 4 from 16 to get 12
\(2x = 12\)
You will then divide both sides by 2
\(\frac{2x}{2}\) = \(\frac{12}{2}\)
x= 6
The second one is hard to read but since ∠3 is 54° you should just start from there
Hope this helps
Answer:
x = 6
Step-by-step explanation:
The Answer for the first figure:
m<5 and m<7 are equal, since they are corresponding angles. So, that means;
m<5 = m<7
12x + 4 = 10x + 16
12x - 10x = 16 - 4
2x = 12
x = 6 (when both divided by 2)
the width of a rectangle is 3 inches less than its length the perimeter of the rectangle is 26 inches what is the width of the rectangle
Answers
Answer:
5
Step-by-step explanation:
W = x
L = x + 3
P = 2W + 2L
26 = 2(x) + 2(x + 3)
26 = 2x + 2x + 6
26 = 4x + 6
26 - 6 = 4x
20 = 4x
x = 5
Cho tập số tự nhiên từ 1 đến 20, lấy ngẫu nhiên ba số. Xác suất để ba số lấy được lập thành cấp số cộng là
Answers
The blue dot is at what value on the number line?
十一
+ +++ ++++
-16
-10
?

Answers
Answer:
-22
Step-by-step explanation:
Chicken wire function drop down
Answers
is this a real question cause the awnser is fire
need help w the circled ones plsssss

Answers
Answer: #1. yes it's a function #6. the graph is increasing at (-oo , 2) , #7. the graph is decreasing at (2,oo) ,
Step-by-step explanation:
hope it helps
6. It is increasing from (-infinity, 4) or ] i am not sure
7. It is decreasing from ( or [4, infinity)
If the arrow kept on going the f(-12) = x for example, f(4)=2
Important things to know f(x)=y and (x,y)
I am sorry that I can not help with the others!!!
In Myanmar, five laborers, each making the equivalent of $3.00 per day, can produce 38 units per day. In China, nine laborers, each making the equivalent of $1.75 per day, can produca 45 units. In Billings, Montana, three laborans, each making $83.00 per day, can make 105 units.
Shipping cost from Myanmar to Denver, Colorado, the final destination, is $1.50 per unit. Shipping cost from China to Denver is $1.20 per unit, while the shipping cost from Billings, Montana to Denver is $0.30 per unit
Based on total costs (labor and transportation) per unit, the most economical location to produce the item is___ with a total cost (labor and transportation) per unit of $ (Enter your response rounded to two decimal places)
Answers
Answer:
In China, $0.45
Hope it helps!
Find the missing exponent.

Answers
Explanation: when dividing exponents, subtract them so in this case, it’s 25-19 to get 6 as the answer
Click on the graphic to find the correct line of reflection.

Answers
Answer:
that one is already correct
Mark each of the following graphs as (a) a function, but not one-to-one, (b) one-to-one function, or (c) not a function. In each case, explain how you know. (1 point each)
Answers
The graph is forming a function but it is not an one-one function.
If the vertical line test is satisfied, then the graph represents a function and a vertical line will cross it at most once.
If a horizontal line crosses the graph in no more than one spot, the function is one-to-one and passes the horizontal line test.
The graph in this case is made up of several horizontal, non-overlapping lines. It is a function and passes the vertical line test, however a horizontal line can cross the graph at any number of locations (is not one-to-one).
However, the graph is not a one-to-one function.
To know more about function, visit,
https://brainly.com/question/25638609
#SPJ4
1. A machine produces metal rods used in an automobile suspension system. A random sample of 15 rods is selected, and the diameter is measured. The resulting data (in millimeters) are as follows:
8.24, 8.25, 8.20, 8.23, 8.24, 8.21, 8.26, 8.26, 8.20, 8.25, 8.23, 8.23, 8.19, 8.36, 8.24.
You have to find a 95% two-sided confidence interval on mean rod diameter. What is the upper value of the 95% CI of mean rod diameter? Please report your answer to 3 decimal places.
Answers
The upper value of the 95% CI of the mean rod diameter is approximately 8.276 millimeters.
To find the upper value of the 95% confidence interval (CI) of the mean rod diameter, we can use the formula:
Upper CI = sample mean + margin of error
First, we calculate the sample mean. Adding up all the measured diameters and dividing by the sample size gives us:
Sample mean = (8.24 + 8.25 + 8.20 + 8.23 + 8.24 + 8.21 + 8.26 + 8.26 + 8.20 + 8.25 + 8.23 + 8.23 + 8.19 + 8.36 + 8.24) / 15 = 8.2353 (rounded to 4 decimal places)
Next, we need to calculate the margin of error. Since we have a sample size of 15, we can use the t-distribution with 14 degrees of freedom (n - 1) for a 95% confidence level. Consulting the t-distribution table or using statistical software, we find that the critical value for a two-sided 95% CI is approximately 2.145.
The margin of error is then given by:
Margin of error = critical value * (sample standard deviation / √n)
From the given data, the sample standard deviation is approximately 0.0489. Plugging in the values, we have:
Margin of error = 2.145 * (0.0489 / √15) ≈ 0.0407 (rounded to 4 decimal places)
Finally, we calculate the upper CI:
Upper CI = 8.2353 + 0.0407 ≈ 8.276 (rounded to 3 decimal places)
To learn more about confidence interval click on,
https://brainly.com/question/17019362
#SPJ4
Please help me with this.. its the last question and I dont get it. its just number 12 please help

Answers
Answer:
Lawrence was incorrect.
Step-by-step explanation:
Amy: 2(3x) +2(4x + 3)
= 14x + 6 ✓
Kaye: 3x + 3x + 4x + 3 + 4x + 3
= 14x + 6 ✓
Lawrence: 4(3x) + 2(4x)
= 20x Ø
Sufjan: 6 + 3x + 3x + 4x + 4x
14x + 6 ✓
(Advanced analysis) The equation for the demand curve in the below diagram:
Answers
The equation for the demand curve is Q = a - bP, where Q represents the quantity demanded, P represents the price of the product, a represents the intercept of the demand curve, and b represents the slope of the demand curve.
The equation for the demand curve is a fundamental concept in economics that helps us understand the relationship between the price of a product and the quantity of the product that consumers are willing to buy at that price.
The equation is typically expressed as:
Q = a - bP
Q represents the quantity demanded, which is the amount of the product that consumers are willing to buy at a given price.P represents the price of the product.a represents the intercept of the demand curve, which is the quantity demanded when the price is zero. It represents the maximum quantity consumers are willing to buy at any price.b represents the slope of the demand curve, which shows the change in quantity demanded for a one-unit change in price. It represents the responsiveness of consumers to changes in price.The equation shows that as the price of a product increases, the quantity demanded decreases, and vice versa. This is known as the law of demand. It reflects the inverse relationship between price and quantity demanded.
The demand curve is downward sloping because of this inverse relationship. It slopes downwards from left to right, indicating that as the price decreases, the quantity demanded increases, and as the price increases, the quantity demanded decreases.
Learn more:About equation here:
https://brainly.com/question/29538993
#SPJ11
what is an equation of the line the passes through the point -8,0 and is parallel to the line x+2y=14
Answers
Answer:
y = -\(\frac{1}{2}\)x - 4
Step-by-step explanation:
If a line is parallel then it has the same slope as your original line, so solve your equation for y, 2y = -x +14, divide both sides by 2 so y = - 1/2 x + 7
So your new parallel line has a slope of -1/2, since it passes through (-8,0) now find your y-intercept, so y = -1/2 x + 7 is 0 = -1/2(-8) + b so 0 = 4 + b
so b = -4, so put it all together
y = -\(\frac{1}{2}\)x - 4