The table below shows the cost per pound of different vegetables.
Prices of Vegetables
Vegetable
Cost (per pound)
Potatoes
$3.89
Squash
$4.68
Carrots
$1.67
Cucumbers
$2.59
What is the estimated cost for 7.8 pounds of potatoes?
$16
$24
$32
$40
Answers
Answer:
16
Step-by-step explanation:
i got it right on the test
Answer:
16...
hope, it helps! x
Related Questions
Determine if the function shows a linear relationship or an absolute value relationship. Then evaluate the
function for the indicated value of x.
A. f(x) = |x-31-2; x = -5
B. g(x) = 1.5x; x = 0.2
C. p(x) = 17 - 2x]; x = -3
Answers
Find the selling price of a $15.25 pair of socks with a 18% discount.
Round to the nearest cent when necessary.
Answers
Answer:
12.50
Step-by-step explanation:
The selling price of the socks will be $12.5.
What is the selling price?The cost at which any product is sold is called the selling price of the product.
The selling price of a $15.25 pair of socks with an 18% discount is calculated:-
Discounted price = 15.25 x ( 18 / 100 )
= $2.754
Selling price = 15.25 - 2.754 = $12.5
Hence, the selling price of socks is $12.5.
To know more about selling price follow
https://brainly.com/question/1153322
#SPJ2
does applying gradient boosting linear regressor multiple times give the same result as linear regression
Answers
No, applying gradient boosting linear regressor multiple times does not necessarily give the same result as linear regression.
Gradient boosting is an iterative machine learning algorithm that involves combining multiple weak models, such as decision trees, to create a strong predictive model. In each iteration of the algorithm, a new model is trained to predict the errors of the previous models, and the final prediction is the sum of the predictions of all the models.
On the other hand, linear regression is a parametric method that involves fitting a linear equation to the data, where the coefficients of the equation are estimated using the least squares method. While gradient boosting linear regression and linear regression both aim to predict a target variable based on a set of input variables, they use different approaches and assumptions, and their results may not be the same.
In particular, gradient boosting can be more effective than linear regression when the relationship between the input variables and the target variable is nonlinear or when there are complex interactions between the input variables. However, linear regression can be more interpretable and easier to implement than gradient boosting in some cases.
To know more about linear regression,
https://brainly.com/question/29665935
#SPJ11
2. Suppose you have a data set of 7 numbers. If the constant 5 is added to each value in the set, what happens to the mean? What happens to the standard deviation?
3. There is a chowder eating contest in a small New England town. The distribution of the amount of chowder consumed is bell-shaped with mean 32 ounces and variance 64 ounces. If two hundred people participated in the contest, find the following.
a. The number of people who consumed between 24 and 40 ounces of chowder.
b. The number of people who consumed between 16 and 40 ounces of chowder.
Answers
If the constant 5 is added to each value in a data set, the mean of the data set increases by 5, and the standard deviation remains the same. This is because adding a constant to each value in the data set shifts the distribution of the data to the right, but it does not change the spread of the data.
What are the responses to other questions?(a) The number of people who consumed between 24 and 40 ounces of chowder can be found by finding the area under the standard normal curve that corresponds to these values and multiplying it by the number of people. To find this area, we need to find the standard scores (z-scores) corresponding to 24 and 40 ounces and then use a table of the standard normal distribution to find the area.
The mean and standard deviation of the distribution are 32 ounces and 8 ounces, respectively. The standard score corresponding to 24 ounces is (24-32)/8 = -1, and the standard score corresponding to 40 ounces is (40-32)/8 = 1. The area under the standard normal curve between -1 and 1 is approximately 0.6826. So, approximately 68.26% of the people consumed between 24 and 40 ounces of chowder.
So, the number of people who consumed between 24 and 40 ounces of chowder is 200 * 0.6826 = 136.52, or approximately 136 people.
(b) To find the number of people who consumed between 16 and 40 ounces of chowder, we can repeat the same process. The standard score corresponding to 16 ounces is (16-32)/8 = -2, and the standard score corresponding to 40 ounces is (40-32)/8 = 1. The area under the standard normal curve between -2 and 1 is approximately 0.8365. So, approximately 83.65% of the people consumed between 16 and 40 ounces of chowder.
So, the number of people who consumed between 16 and 40 ounces of chowder is 200 * 0.8365 = 167.3, or approximately 167 people.
learn more about standard deviation: https://brainly.com/question/475676
#SPJ1
Solve for p. 2p 5>2(p−3) no solution no solution all real numbers all real numbers p>−9 p greater than negative 9 p>−3
Answers
The solution set for given inequality is the set of all real numbers. Therefore the correct option is C.
According to the given question.
We have an inequality.
2p + 5 > 2(p - 3)
We have to find the solution for the given inequality.
A solution for an inequality in variableis a number such that when we substitute that number for variable we have a true statement.
Therefore, the solution for inequality 2p + 5 > 2(p - 3) is given by
2p + 5 > 2(p -3)
⇒ 2p + 5 > 2p - 6
⇒ 2p -2p + 5 > -6 (subtract 2p both the sides)
⇒ 5 > -6
This inequality is free from variable p and it is true for any value of p.
Hence, the solution set for given inequality is the set of all real numbers. Therefore the correct option is C.
Find out more information about solution for an inequality here:
https://brainly.com/question/22010462
#SPJ4
The function of f is defined by f(x)=x²-2x-24, find the range of f
Answers
Answer:
[-25, ∞) , {y|y ≥ -25}
Step-by-step explanation:
^^^
Evie rolls a fair number cube with faces labeled 1 through 6. She selects a marble from a bag were 3 are green and 1 is red. Select which point on the number line correctly represents the probability she
will land on an even number and then selects a green marble
Answers
The point on the number line that represents the probability of rolling an even number and selecting a green marble is 3/8, which is between 0.3 and 0.4 on the number line.
Will she land on an even number and then selects agreen marble?
The probability of rolling an even number is 3/6, which can be simplified to 1/2, because there are three even numbers (2, 4, and 6) out of six possible outcomes.
The probability of selecting a green marble from the bag is 3/4, because there are three green marbles out of four total marbles in the bag.
To calculate the probability of both events happening together (rolling an even number and selecting a green marble), you multiply the probabilities of each event:
P(even number and green marble) = P(even number) x P(green marble)
P(even number and green marble) = (1/2) x (3/4)
P(even number and green marble) = 3/8
Learn more about probability
brainly.com/question/31878378
#SPJ11
Find an equation of the tangent line at the given value of x. y= 0∫x sin(2t2+π2),x=0 y= ___
Answers
The equation of the tangent line at x=0 is y = x.
To find the equation of the tangent line at the given value of x, we need to find the derivative of the function y with respect to x and evaluate it at x=0.
Taking the derivative of y=∫[0 to x] sin(2t^2+π/2) dt using the Fundamental Theorem of Calculus, we get:
dy/dx = sin(2x^2+π/2)
Now we can evaluate this derivative at x=0:
dy/dx |x=0 = sin(2(0)^2+π/2)
= sin(π/2)
= 1
So, the slope of the tangent line at x=0 is 1.
To find the equation of the tangent line, we also need a point on the line. In this case, the point is (0, y(x=0)).
Substituting x=0 into the original function y=∫[0 to x] sin(2t^2+π/2) dt, we get:
y(x=0) = ∫[0 to 0] sin(2t^2+π/2) dt
= 0
Therefore, the point on the tangent line is (0, 0).
Using the point-slope form of a linear equation, we can write the equation of the tangent line:
y - y1 = m(x - x1)
where m is the slope and (x1, y1) is a point on the line.
Plugging in the values, we have:
y - 0 = 1(x - 0)
Simplifying, we get:
y = x
So, the equation of the tangent line at x=0 is y = x.
Learn more about Fundamental Theorem of Calculus here:
brainly.com/question/30761130
#SPJ11
Find x:
(Round the answer to the nearest tenth if there is a decimal)
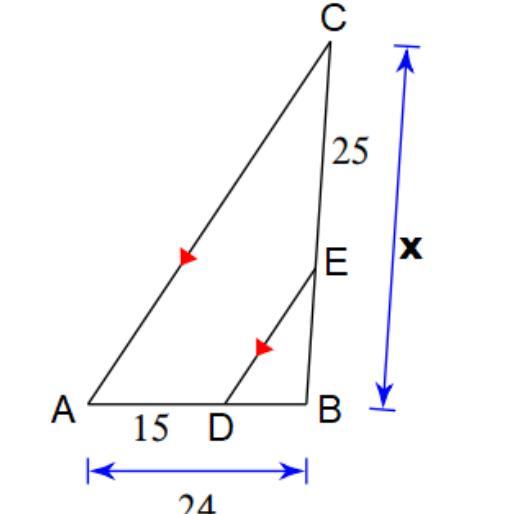
Answers
Answer:Angle x is congruent with the interior angle opposite side 8 (alternate interior angles)
Use tangent:
tan x = 8/15
x = arctan (8/15)
x = 28.1° (rounded)
Step-by-step explanation:
Given that y is invesly proportional to the cube root of x and that x=64 when y=12.75,find the change in the value of y when the value of x is divided by 125
Answers
The relationship between y and x is described as inversely proportional to the cube root of x. When x is divided by 125, the value of y changes.
To find the change in y, we first need to determine the constant of proportionality between y and x. By using the given values x = 64 and y = 12.75, we can calculate the constant of proportionality. Then, we can calculate the new value of y when x is divided by 125.
The inverse proportionality between y and the cube root of x can be expressed as y = k/(∛x), where k is the constant of proportionality. Given that x = 64 and y = 12.75, we can substitute these values into the equation:
12.75 = k/(∛64)
To find the constant k, we need to solve for it. Taking the cube root of 64 gives us 4:
12.75 = k/4
Multiplying both sides by 4:
k = 51
Now, we can use this value of k to find the new value of y when x is divided by 125:
y' = 51/(∛(64/125)) = 51/(∛(0.512))
Simplifying further:
y' ≈ 51/0.8 ≈ 63.75
Therefore, when x is divided by 125, the value of y changes to approximately 63.75.
Learn more about Proportionality here :
brainly.com/question/8598338
#SPJ11
A bicycle rides over a freshly painted line, and the front wheel picks up a visible paint mark. The front wheel has a diameter of 24 inches and makes one revolution every six seconds. What is the height of the paint mark when the bicycle has traveled for 14 seconds after crossing the line
Answers
The height of the paint mark when the bicycle has traveled for 14 seconds after crossing the line is approximately 55.92 inches.
First, we need to find the distance traveled by the bicycle in 14 seconds. We can use the formula:
distance = rate x time
The rate of the bicycle is the same as the speed of the front wheel, which is equal to the circumference of the wheel. The circumference of a circle is given by the formula:
circumference = 2 x pi x radius
where pi is approximately 3.14 and the radius of the wheel is half its diameter, or 12 inches. Therefore, the circumference of the front wheel is:
circumference = 2 x 3.14 x 12 = 75.36 inches
The rate of the bicycle is therefore:
rate = 75.36 inches/revolutions
Since the front wheel makes one revolution every six seconds, the rate of the bicycle is:
rate = 75.36 inches/6 seconds = 12.56 inches/second
The distance traveled by the bicycle in 14 seconds is:
distance = rate x time = 12.56 inches/second x 14 seconds = 175.84 inches
When the paint mark is made on the ground, it will be at the lowest point of the front wheel. After the bicycle has traveled for 14 seconds, the front wheel will have made 14/6 = 2.33 revolutions. Therefore, the height of the paint mark above the ground is:
height = 2.33 x 24 inches = 55.92 inches
So the height of the paint mark when the bicycle has traveled for 14 seconds after crossing the line is approximately 55.92 inches.
Learn more about height here:
https://brainly.com/question/29131380
#SPJ11
If the vertex of a parabola is (3,5), what is the symmetry
Answers
Answer:
axis of symmtery: x = 3 or h = 3
Step-by-step explanation:
The vertex (h, k) of a parabola is the point wherein the graph intersects the axis of symmetry—the imaginary straight line that bisects a parabola into two symmetrical parts, where x = h.
In the standard form of quadratic equation, y = ax² + bx + c, the equation of the axis of symmetry is: \(x = \frac{-b}{2a}\).In the vertex form of the quadratic equation, y = a(x - h)² + k, the equation of the axis of symmetry is: \(h = \frac{-b}{2a}\).Regardless of whether the quadratic equation is in standard or vertex form, the x-coordinate (h) of the vertex determines the axis of symmtetry, hence, x = h.
Therefore, given that the vertex of a parabola is at point (3, 5), then it means that the axis of symmetry occurs at x = 3 or h = 3.
distributive property 91 = - 7 (3x - 1 )
Answers
Let’s distribute that.
-7 x 3x = -21x
-7 x -1 = 7
Let’s rewrite, using the distributed numbers I just got.
91 = -21x + 7
Now, let’s solve for x.
91 -7 = -21x + 7 -7
(Remember, whatever you do on one side you do on the other)
84=-21x
84/-21=-21x/-21
-4=x
Solution : x=-4
10 The height of a window is 1 meter 35 centimeters, How tall is the window in millimeters+F 135 millimetersG 1.35 millimetersH 1,350 millimeters31,035 millimeters
Answers
ok
1.- Convert 1 m to mm
1 m ------------------ 100 cm 10 mm ------ 1 cm
there are 10 x 100 = 1000 mm in a meter
2.- Convert 35 cm into mm
10 mm -------------- 1 cm
x -------------- 35 cm
x = (35 x 10) / 1
x = 350 mm
3.- Total = 1000 + 350 = 1350 mm
The answer is H. 1350 mm
when two or more independent variables in the same regression model can predict each other better than the dependent variable, the condition is referred to as .
Answers
High intercorrelations between two or more independent variables in a multiple regression model are referred to as multicollinearity.
A single dependent variable and several independent variables can be analyzed using the statistical technique known as multiple regression. With the use of independent variables whose values are known, multiple regression analysis aims to predict the value of a single dependent variable.
Multicollinearity, also known as collinearity, is a phenomena in statistics when one predictor variable in a multiple regression model can be linearly predicted from the others with a high level of accuracy. In this case, minor adjustments to the model or the data may cause the multiple regression's coefficient estimates to fluctuate unpredictably.
Learn more about to Multicollinearity visit here:
https://brainly.com/question/17216244
#SPJ4
what is the density of the rock???!!!!!!!!!!

Answers
Answer:
he actual densities of pure, dry, geologic materials vary from 880 kg/m3 for ice (and almost 0 kg/m3 for air) to over 8000 kg/m3 for some rare minerals. Rocks are generally between 1600 kg/m3 (sediments) and 3500 kg/m3 (gabbro).
Step-by-step explanation:
Yesterday, it took 40 minutes to drive to school. Today, it took 32 minutes to drive to school. What is your percent of change?
Answers
Step-by-step explanation:
decrease by 20%
xxxxxxxx
.........................
Okay one more thank you guy for bieng on my team. whoeveranswer my questions i will give you a brainliest.

Answers
Answer:
6 3/4 miles
Step-by-step explanation:
In order to solve this problem, you can think of it like a ratio:
27 miles : 2 hours
That means you can just divide both sides by 4 so to make 2 hours into 1/2 hour:
27/4 miles : 1/2 hour
6 3/4 miles : 1/2 hour
Can someone help me with this Question.

Answers
The formula we need to use is given above. In this formula, we will substitute the desired values. Let's start.
\(P=3W+D\)A) First, we can start by analyzing the first premise. The team has \(8\) wins and \(5\) losses. It earned \(8 \times 3 = 24\) points in total from the matches it won and \(1\times5=5\) points in total from the matches it drew. Therefore, it earned \(24+5=29\) points.
B) After \(39\) matches, the team managed to earn \(54\) points in total. \(12\) of these matches have ended in draws. Therefore, this team has won and lost a total of \(39-12=27\) matches. This number includes all matches won and lost. In total, the team earned \(12\times1=12\) points from the \(12\) matches that ended in a draw.
\(54-12=42\) points is the points earned after \(27\) matches. By dividing \(42\) by \(3\) ( because \(3\) points is the score obtained as a result of the matches won), we find how many matches team won. \(42\div3=14\) matches won.
That leaves \(27-14=13\) matches. These represent the matches team lost.
Finally, the answers are below.
\(A)29\)
\(B)13\)
Answer:
a) 29 points
b) 13 losses
Step-by-step explanation:
You want to know points and losses for different teams using the formula P = 3W +D, where W is wins and D is draws.
A 8 wins, 5 drawsThe number of points the team has is ...
P = 3W +D
P = 3(8) +(5) = 29
The team has 29 points.
B 54 pointsYou want the number of losses the team has if it has 54 points and 12 draws after 39 games.
The number of wins is given by ...
P = 3W +D
54 = 3W +12
42 = 3W
14 = W
Then the number of losses is ...
W +D +L = 39
14 +12 +L = 39 . . . substitute the known values
L = 13 . . . . . . . . . . subtract 26 from both sides
The team lost 13 games.
__
Additional comment
In part B, we can solve for the number of losses directly, using 39-12-x as the number of wins when there are x losses. Simplifying 3W +D -P = 0 can make it easy to solve for x. (In the attached, we let the calculator do the simplification.)
<95141404393>

Lisa makes $23. 50 an hour at her job, and every week she pays $25 to her health insurance. How much money did Lisa make if she worked 35. 8 hours last week? $587. 50 $841. 30 $816. 30 $895. 0.
Answers
Lisa made $841.30 last week after working 35.8 hours and payingpaying $25 for health insurance.
To calculate Lisa's earnings, we need to multiply her hourly rate by the number of hours she worked. Lisa earns $23.50 per hour, and she worked for 35.8 hours. Multiplying these values, we get $23.50 * 35.8 = $841.30.
In addition to her earnings, we need to subtract the amount she paid for health insurance. Lisa pays $25 every week. So, to find her total earnings after deducting health insurance, we subtract $25 from $841.30: $841.30 - $25 = $816.30.
Therefore, Lisa made $816.30 last week after working 35.8 hours and paying $25 for health insurance.
Learn more about paying here
https://brainly.com/question/13143081
#SPJ11
Please do number 19 for me.

Answers
20x=180
x=9
Angle ABC is the top one
8x9=72
Answer:
\(x = 9\)
\(angle \: abc = 8x + 6x + 6x \\ 20x = 180 \\ x = \frac{180}{20} \\ x= 9\)
\(plzz \: \: mark \: as \: brainliest\)
Someone Pls solve both fast

Answers
Answer:
#1) x=38
#2) x=12
Step-by-step explanation:
For (1)
Since its a triangle we know that all 3 interior angles added up is gonna eqaul 180 degrees. So we already have 2 angles which are 21 and 17. You add those up and you’d get 38. Now since the final angles is unknown we can just make a simple equation of 38+x=180 since we know 2 angles and we need 1 more and a triangle is 180 degrees alli ddded up together. You’d get 142 for that angle. X is adjacent to that angle and they form a straight line so it also has to be 180. We got 1 side and so we subtract 180-142= 38. X will be 38.
For (2)
Since its 2 parallel lines cut by a transversal and we have two same side interior angles we know its gonna be supplementary Which means that both those angles added up will be 180. Now we have the two different angles so we add them up and solve for x. (10x+17)+(3x+7)= 180. Commbine like terms which will turn out to be 13x+24=180. Subtract 24 on both sides. 13x= 156. Solve for x by diving 13 on both sides which will lead to x= 12
\(4x -3 = 11x\)
Answers
You move the terms so it looks like: 4x = 11x + 3
Then you collect like terms so you should have -7x = 3
After that just divide both sides by -7x and x should equal -3/7
Answer:
\(x=-\frac{3}{7}\)
Step-by-step explanation:
\(4x-3=11x\\\\4x-3+3=11x+3\\\\4x=11x+3\\\\4x-11x=11x-11x+3\\\\-7x=3\\\\\frac{-7x=3}{-7}\\\\\boxed{x=-\frac{3}{7}}\)
Hope this helps.
What is the z-score of x = -2, if it is 2.78 standard deviations to the left of the mean?A. Less than 0B. 1.6 – 2.5C. 0 – 0.5D. More than 2.5E. 0.6 – 1.5
Answers
The z-score of x = -2, if it is 2.78 standard deviations to the left of the mean, is D. More than 2.5.
A z-score is a measure of how many standard deviations a data point is from the mean. In this case, the data point x = -2 is 2.78 standard deviations to the left of the mean. This means that the z-score is -2.78. Since the absolute value of -2.78 is greater than 2.5, the correct answer is D. More than 2.5.
Here's how to calculate the z-score:
z = (x - μ) / σ
where z is the z-score, x is the data point, μ is the mean, and σ is the standard deviation.
In this case, we are given that x = -2 and that it is 2.78 standard deviations to the left of the mean. This means that:
z = -2.78
So the z-score is -2.78, which is greater than 2.5 in absolute value. Therefore, the correct answer is D. More than 2.5.
know more about standard deviations here
https://brainly.com/question/23907081#
#SPJ11
[30 PTS!!] Using mathematically precise language, explain in detail how you would multiply the complex number \(z_1=r_1(cos\)θ\(_1+i sin\)θ\(_1)\) with the complex number \(z_2=r_2(cos\)θ\(_2+isin\)θ\(_2)\).
![[30 PTS!!] Using mathematically precise language, explain in detail how you would multiply the complex](https://i5t5.c14.e2-1.dev/h-images-qa/contents/attachments/MVgV0cSVSrSvGz7khy4KfjpdadXwVO52.png)
Answers
Multiplying z₁ and z₂ involves calculating their products
The product of z₁ and z₂ is r₁r₂(cos(Θ₁ + Θ₂) + isin(Θ₁ + Θ₂))
How to multiply the complex numbers?The numbers are given as:
z₁ = r₁(cosΘ₁ + isinΘ₁)
z₂ = r₂(cosΘ₂ + isinΘ₂)
The product is represented as:
z₁ * z₂ = r₁(cosΘ₁ + isinΘ₁) * r₂(cosΘ₂ + isinΘ₂)
This gives
z₁ * z₂ = r₁r₂(cosΘ₁ + isinΘ₁) (cosΘ₂ + isinΘ₂)
Expand
z₁ * z₂ = r₁r₂(cosΘ₁cosΘ₂ + icosΘ₁sinΘ₂+ isinΘ₁cosΘ₂ + i²sinΘ₁sinΘ₂ )
In complex numbers,
i² = -1.
So, we have:
z₁ * z₂ = r₁r₂(cosΘ₁cosΘ₂ + icosΘ₁sinΘ₂+ isinΘ₁cosΘ₂ - sinΘ₁sinΘ₂ )
Rewrite as:
z₁ * z₂ = r₁r₂(cosΘ₁cosΘ₂ - sinΘ₁sinΘ₂ + icosΘ₁sinΘ₂+ isinΘ₁cosΘ₂ )
Apply sine and cosine ratios
z₁ * z₂ = r₁r₂(cos(Θ₁ + Θ₂) + isin(Θ₁ + Θ₂))
Hence, the product of z₁ and z₂ is r₁r₂(cos(Θ₁ + Θ₂) + isin(Θ₁ + Θ₂))
Read more about complex numbers at:
https://brainly.com/question/10662770
A betting site allows you to bet $1,000 on the winner of a national election. There are two parties, A and B. The incumbent is from party A and is the only candidate of that party. Party B is still in the middle of its primaries, and it has two candidates, B1 and B2; one of them will compete with A in the national elections.
If you bet $1,000 that candidate A (the incumbent) will win the national election and A wins, you’ll get $2,200. If A loses, you get nothing.
If you bet $1,000 that candidate B1 will win the national election and B1 wins, you’ll get $2,000. If B1 loses (either to B2 in the primaries or in the national election to A), you get nothing.
If you bet $1,000 that candidate B2 will win the national election and B2 wins, you’ll get $10,000. If B2 loses (either to B1 in the primaries or in the national election to A), you get nothing.
You want to bet $1,000 on one candidate to maximize your expected payoff. You believe there is a 50% chance that A will win the national election (regardless of whether they compete with B1 or B2). You believe there’s an 80% chance that B1 will win the primaries and a 20% chance that B2 will win the primaries.
Below type who will you bet on: A, B1, or B2.
Answers
It is recommended that a wager of $1,000 be placed on candidate B1 to win the national election so that the potential return can be maximised.
For each candidate, we first compute the probability of each result, and then we multiply that probability by the payout that corresponds to that outcome. This gives us the expected payoff for each candidate. The projected return for candidate A comes to 0.5 times $2,200, which equals $1,100. The estimated reward for candidate B1 is 0.5 times 0.8 times $2,000, which equals $800. In conclusion, the expected payment for selection B2 is half (0.5) times (0.2) times (10,000), which is $1,000.
According to these calculations, the expected return on investment for a wager placed on candidate A is $1,100, but the expected return on investment for a bet placed on candidate B1 is $800 and the expected return for candidate B2 is $1,000. Because we want to make sure that the amount of money we win is as big as possible, we should place our bets on candidate A, who has the potential to win us the most money. As a result, placing a wager of one thousand dollars on candidate B1 to win the national election is recommended.
Learn more about probability here:
https://brainly.com/question/31828911
#SPJ11
Find the mode for the following data set:10 30 10 36 26 22
Answers
In this particular data set, 10 is the only value that occurs more than once, so it is the only mode
The mode is the value that occurs most frequently in a data set. In the given data set {10, 30, 10, 36, 26, 22}, we can see that the value 10 occurs twice, and all other values occur only once. Therefore, the mode of the data set is 10, since it occurs more frequently than any other value in the set.
Note that a data set can have multiple modes if two or more values occur with the same highest frequency. However, in this particular data set, 10 is the only value that occurs more than once, so it is the only mode.
To learn more about frequently visit:
https://brainly.com/question/13959759
#SPJ11
Area of a solid box in the shape of a cube with side length 9cm
Answers
Answer:
486
Step-by-step explanation:
area of a cube =6x²
length= 9
area=6×9²
=6×81
=486
Area = 729 cm^3
Surface area = 486 cm ^2
Step by step
A cube has all sides that are equal
Area = L x W x H
A = 9 x 9 x 9
A= 729 cubic cm
Surface area = 6 x S^2
This is LxW x 6 sides
Surface area = 81 x 6
Surface area = 486
f(x)=2/x find (f x f)(x)
Answers
f(x)=x−2f(x)=x-2 , g(x)=x+2g(x)=x+2
Set up the composite result function.
g(f(x))g(f(x))
Evaluate g(f(x))g(f(x)) by substituting in the value of ff into gg.
g(x−2)=(x−2)+2g(x-2)=(x-2)+2
Combine the opposite terms in (x−2)+2(x-2)+2.
g(x−2)=x
NEED HELP ASAP GIVING A TON OF POINTS
Han and Priya want to know the mean height of the 30 students in their dance class. They each select a random sample of 5 students.
The mean height for Han's sample is 59 inches.
The mean height for Priya's sample is 61 inches.
Does it surprise you that the two sample means are different?
Answers
The difference in the mean heights of Han and Priya's samples do not surpise me.
What are samples?A sample is a smaller group of the population. A sample is sometimes needed as it might not be feasible to survey all the population due to large numbers. It might also not be cost effective to access the whole population.
Han and Priya would measure different students, so it is expected that the mean heights would be different.
To learn more about samples, please check: https://brainly.com/question/18521835