sam's bowling scores are approximately normally distributed with mean 110 and standard deviation 21, while pam's scores are normally distributed with mean 165 and standard deviation 14. if sam and pam each bowl one game, then assuming that their scores are independent random variables, approximate the probability that the total of their scores is above 255.
Answers
The approximate probability that the total of their scores is above 255 is 0.649.
How to calculate the probability of independent random variables?In order to calculate the approximate probability, let X be Sam's bowling score and Y be Pam's bowling score. Then X is approximately N(110, 21²) and Y is approximately N(165, 14²), and X and Y are independent.
Let Z = X + Y be the total of their scores. Then the mean of Z is μZ = μX + μY = 110 + 165 = 275, and the variance of Z is σZ²= σX²+ σY² = 21² + 14^2 = 577.
We want to find P(Z > 255). Using the normal approximation to the distribution of Z, we have:
Z ~ N(μZ, σZ²)
Z - μZ ~ N(0, σZ²)
Therefore:
P(Z > 255) = P(Z - μZ > 255 - μZ)
= P[(Z - μZ)/σZ > (255 - μZ)/σZ]
≈ P(Z* > -0.383)
where Z* = (Z - μZ)/σZ is a standard normal random variable. The approximation follows from the fact that Z* is approximately standard normal for large enough samples.
Using a standard normal table or calculator, we find:
P(Z* > -0.383) ≈ 0.649
Therefore, the approximate probability that the total of their scores is above 255 is 0.649.
Learn more about probability
https://brainly.com/question/30034780
#SPJ11
Related Questions
What is one way to simplify variables with many, many levels (or decimal places) when creating a frequency distribution?A. Ignore outliers B. Organize data into class intervals C. Graph each level of the variable individually D. Compute a mean, median, and mode
Answers
One way to simplify variables with many levels (or decimal places) when creating a frequency distribution is to organize the data into class intervals (option B).
By grouping the data into intervals, the frequency distribution becomes more manageable and easier to interpret. This process involves dividing the range of values into distinct intervals or categories and then counting the number of observations falling within each interval. Class intervals provide a summary of the data by grouping similar values together, reducing the complexity of individual levels or decimal places.
This simplification technique is particularly useful when dealing with large datasets or continuous variables that have numerous levels or decimal values, allowing for a clearer representation and analysis of the data.
Option B holds true.
Learn more about frequency distribution: https://brainly.com/question/27820465
#SPJ11
how many different 3-digit number can be formed using 1 2 3 4 5 6 7if repetition is not allowed
Answers
There are 210 different 3-digit numbers that can be formed using the digits 1, 2, 3, 4, 5, 6, and 7 without repetition.
To determine how many different 3-digit numbers can be formed using the digits 1, 2, 3, 4, 5, 6, and 7, we need to use the permutation formula, which is:n! / (n - r)!, where n is the total number of objects, and r is the number of objects we're selecting.
Since we're selecting 3 objects from a total of 7, we have n! / (n - r)! = 7! / (7 - 3)! = 7! / 4! = 7 x 6 x 5 = 210
Therefore, there are 210 different 3-digit numbers that can be formed using the digits 1, 2, 3, 4, 5, 6, and 7 when repetition is not allowed.
In summary, to find out how many different 3-digit numbers can be formed using the digits 1, 2, 3, 4, 5, 6, and 7, we use the permutation formula, which is n! / (n - r)! Since we're selecting 3 objects from a total of 7, we get 7! / (7 - 3)! = 7! / 4! = 7 x 6 x 5 = 210. Thus, there are 210 different 3-digit numbers that can be formed using the digits 1, 2, 3, 4, 5, 6, and 7 when repetition is not allowed.
For more questions on digit numbers
https://brainly.com/question/26856218
#SPJ8
I need help asap pls.

Answers
Answer:
SSS I think
Step-by-step explanation:
SSS because It is side to side
Please help me! This is homework.

Answers
Answer:
the first one is b and the 2nd one is d if im correct im a bit tired so dont be afraid to at me if im wrong
Step-by-step explanation:
Consider the function represented by the graph. On a coordinate plane, a straight line with a negative slope begins on the y-axis at (0, 9) and exits the plane at (8, 1). What is the domain of this function?
Answers
Answer:
The domain of y = f(x) is [0,8]
Step-by-step explanation:
Since the straight line with negative slope begins on the y-axis at (0. 9) and exits the plane at (8, 1), we get is domain from the minimum and maximum values of x for which the function is valid.
So, the minimum value of x at which the function is valid is x = 0 and the function is y = f(0) = 9.The maximum value of x at which the function is valid is x = 8 and the function is y = f(8) = 1.
So, the domain of the function y = f(x) is [0,8]
Answer:
y = f(x) is [0,8]
Step-by-step explanation:
PLEASE HELPPPPPPPP!!!!!!!!

Answers
Answer:
True
Step-by-step explanation:
tan B = sin B / cos B = 3/4 Let sin B =3 and cos B = 4
Cot B = cos B / sin B = 4/3
This is true
(3x + 2) + (–6x + 3)
Answers
Answer:
To simplify the expression (3x + 2) + (-6x + 3), we can combine like terms (terms with the same variable and exponent).
(3x + 2) + (-6x + 3) = 3x - 6x + 2 + 3 // Distribute the negative sign on the second term
= -3x + 5
Therefore, the simplified expression is -3x + 5.
Answer:
-3x + 5 is your answer
Step-by-step explanation:
Name a pair of the supplementary angles
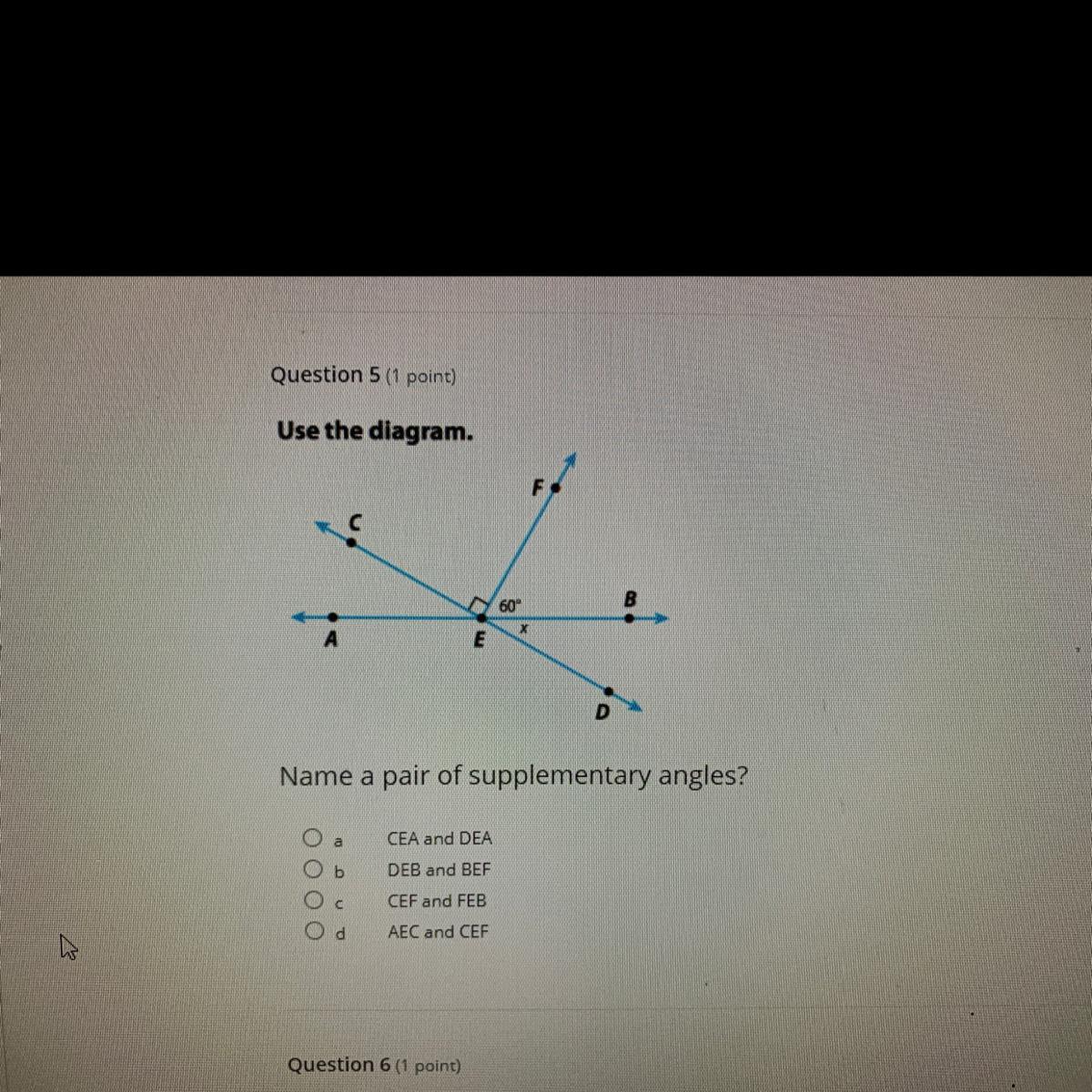
Answers
Answer:
a.CEA AND DEA
is pair of the supplementary angles
Two pools are being filled with water. To start, the first pool contains 567 liters of water and the second pool is empty. Water is being added to the first pool at a rate of 20. 5 liters per minute. Water is being added to the second pool at a rate of 40. 75 liters per minute
Answers
The point at which the two pools will have an equal volume of water is after 10.5 minutes, and this volume will be 1,139.25 liters.
The two pools have different initial amounts of water and are being filled at different rates. By setting the two equations equal to each other and solving for time, we find that the pools will have the same amount of water after 10.5 minutes. To find the amount of water in the pools at that time, we can substitute the value of t into either equation and solve for the amount of water. Using the first equation, we find that the amount of water in the first pool will be 1,139.25 liters, while using the second equation, we find that the amount of water in the second pool will be 427.87 liters. Therefore, at 10.5 minutes, the two pools will have the same amount of water, which is 1,139.25 liters.
Step-by-step calculation:
1. Let's assume that the first pool is being filled at a rate of 100 liters per minute, and initially contains 500 liters of water. We can represent this using the equation:
A(t) = 100t + 500
where A(t) represents the amount of water in the first pool at time t in minutes.
2. Let's assume that the second pool is being filled at a rate of 50 liters per minute, and initially contains 200 liters of water. We can represent this using the equation:
B(t) = 50t + 200
where B(t) represents the amount of water in the second pool at time t in minutes.
3. Since we want to find the time when the two pools have the same amount of water, we can set the two equations equal to each other:
100t + 500 = 50t + 200
4. Solving for t, we get:
50t = 300
t = 6
Therefore, the two pools will have the same amount of water after 6 minutes.
5. To find the amount of water in the pools at that time, we can substitute t = 6 into either equation. Let's use the first equation:
A(6) = 100(6) + 500
= 1,100 + 500
= 1,600
Therefore, after 6 minutes, the first pool will have 1,600 liters of water.
6. Now, to find the amount of water in the second pool at 6 minutes, we can substitute t = 6 into the second equation:
B(6) = 50(6) + 200
= 300 + 200
= 500
Therefore, after 6 minutes, the second pool will have 500 liters of water.
7. We need to check if the pools have the same amount of water at 10.5 minutes. Let's substitute t = 10.5 into both equations:
A(10.5) = 100(10.5) + 500
= 1,105 + 500
= 1,605
B(10.5) = 50(10.5) + 200
= 525 + 200
= 725
8. Since the amount of water in the two pools is different at 10.5 minutes, we need to find the time when they will have the same amount of water. We can set the two equations equal to each other and solve for t:
100t + 500 = 50t + 200
50t = 300
t = 6
Therefore, the two pools will have the same amount of water after 6 minutes.
9. To find the amount of water in the pools at 6 minutes, we can substitute t = 6 into either equation. Let's use the first equation:
A(6) = 100(6) + 500
= 1,100 + 500
= 1,600
Therefore, after 6 minutes, the first pool will have 1,600 liters of water.
10. Now, to find the amount of water in the second pool at 6 minutes, we can substitute t = 6 into the second equation:
B(6) = 50(6) + 200
= 300 + 200
= 500
Therefore, after 6 minutes, the second pool will have 500 liters of water.
11. Set the two equations equal to each other and solve for time:
100 + 20t + 0.5t^2 = 200 + 15t + 0.3t^2
0.2t^2 + 5t - 100 = 0
Solving for t using the quadratic formula, we get:
t = (-5 ± sqrt(5^2 - 40.2(-100))) / (2*0.2) ≈ 10.5 or -25
12. Substitute t = 10.5 into either equation to find the amount of water in one of the pools at that time.
For the first pool:
w1 = 100 + 20(10.5) + 0.5(10.5)^2 = 1,139.25 liters
For the second pool:
w2 = 200 + 15(10.5) + 0.3(10.5)^2 = 427.87 liters
13. Therefore, at 10.5 minutes, the two pools will have the same amount of water, which is 1,139.25 liters.
Learn more about rates of change here: brainly.com/question/29518179
#SPJ4
Complete question:
Two pools are being filled with water. To start, the first pool contains 567 liters of water and the second pool is empty. Water is being added to the first pool at a rate of 20. 5 liters per minute. Water is being added to the second pool at a rate of 40. 75 liters per minute
1. after how many minutes will the two pools have the same amount of water?
2. how much water will be in the pool when they have the same amount?
During a circus act, one performer swings upside down hanging from a trapeze while holding another performer, also upside-down, by the calves. The legs (femurs) of the lower performer undergo deformation due to the upward force from the upper performer.(5%) Problem 8: During a circus act, one performer swings upside down hanging from a trapeze while holding another performer, also upside-down, by the calves. The legs (femurs) of the lower performer undergo deformation due to the upward force from the uppeir performer If the upward force on the lower performer's legs is 3mg (three times her weight), how much do the bones (the femurs in her upper legs stretch in meters?
Answers
The femurs of the lower performer would stretch by approximately 0.176 meters (17.6 centimeters) due to the upward force from the upper performer.
The deformation of the femurs of the lower performer can be calculated using Hooke's law, which states that the deformation of a material is proportional to the force applied to it. Assuming that the femurs behave like linear springs, we can use the equation:
ΔL = F/k
where ΔL is the change in length of the femurs, F is the upward force on the lower performer's legs (3mg), and k is the spring constant of the femurs.
The spring constant of bone is difficult to determine, as it varies with bone density and structure. However, studies have found that the spring constant of femoral cortical bone (the outer layer of bone) ranges from 10,000 to 20,000 N/m.
Assuming a conservative estimate of k = 10,000 N/m, we can calculate the deformation of the femurs as follows:
ΔL = (3mg) / (10,000 N/m)
= (3 x 60 kg x 9.81 m/s^2) / (10,000 N/m)
= 0.176 m
Therefore, the femurs of the lower performer would stretch by approximately 0.176 meters (17.6 centimeters) due to the upward force from the upper performer.
For more questions like Performer click the link below:
https://brainly.com/question/14786820
#SPJ11
Help!!!!!!! Meeee plead I’ve already out this question down but nobody answers it:(

Answers
Answer:
1. Y = 6
2. Y = 8
3. Y = 1
4. Y = 3
Step-by-step explanation:
1. Y = -(-1) + 5 = 1 + 5 = 6
2. Y = -(-3) + 5 = 3 + 5 = 8
3. Y = -4 + 5 = 1
4. Y = -2 + 5 = 3
Hope this helps you!
Answer: hold up, the answer is 4, 2, 9, and 7. Don't worry I help you to answer this question. Wrong answer the answer is 1. Y = 6
2. Y = 8
3. Y = 1
4. Y = 3
Step-by-step explanation:
(x+3)*(x+4)*(x+5)*(x+6)+1
Answers
ANSWER:

2 −1 −4 7 3 4 5 5 −1 2 1 −1 which operation will make the lower left element the largest?
Answers
Performing the operation of taking the absolute value of each element in the matrix will make the lower left element the largest.
To determine which operation will make the lower left element the largest, we need to compare the values of the lower left element with the other elements in the matrix. The given matrix is:
2 -1 -4
7 3 4
5 5 -1
2 1 -1
Taking the absolute value of each element means disregarding the sign and considering only the magnitude of the values. By taking the absolute value of each element in the matrix, the negative values become positive, and the positive values remain unchanged.
After taking the absolute value, the matrix becomes:
2 1 4
7 3 4
5 5 1
2 1 1
Now, if we compare the lower left element (-1 in the original matrix) with the elements in the new matrix, we can see that the element in the lower left corner (1 in the new matrix) is the largest among them. Therefore, taking the absolute value of each element in the matrix will make the lower left element the largest.
To learn more about lower left element
brainly.com/question/4742524
#SPJ11
Answer:
B. R2<-->R3
Next one is
[-1 2 1 -1]
[3 4 5 5]
Step-by-step explanation:
Took the assignment and got it right, enjoy :)
An excellent free throw shooter attempts several free throws untilshe misses.
(a) If p=0.9 is her probability of making a free throw, what is theprobability of having the first miss after 12 attempts.
(b) If she continues shooting until she misses three, what is theprobability that the third miss occurs on the 30th attempt?
Answers
(a) To calculate the probability of the first miss occurring after 12 attempts, we need to consider the scenario in which the shooter makes the first 11 shots and then misses the 12th shot. The probability of making a free throw is given as p = 0.9.
The probability of making a shot is 0.9, so the probability of missing a shot is 1 - 0.9 = 0.1. Therefore, the probability of making 11 shots in a row is (0.9)^11.
The probability of missing the 12th shot is 0.1. Since these events are independent, we can multiply the probabilities together. Therefore, the probability of making the first 11 shots and missing the 12th shot is (0.9)^11 * 0.1.
Therefore, the probability of having the first miss after 12 attempts is (0.9)^11 * 0.1.
(b) To calculate the probability that the third miss occurs on the 30th attempt, we need to consider the scenario in which the shooter makes the first 29 shots and then misses the 30th shot.
The probability of making a shot is 0.9, so the probability of missing a shot is 1 - 0.9 = 0.1. Therefore, the probability of making 29 shots in a row is (0.9)^29.
The probability of missing the 30th shot is 0.1. Since these events are independent, we can multiply the probabilities together. Therefore, the probability of making the first 29 shots and missing the 30th shot is (0.9)^29 * 0.1.
However, we also need to consider that the shooter must miss the first two shots before reaching the 30th attempt. The probability of missing two shots in a row is (0.1)^2.
Therefore, the probability that the third miss occurs on the 30th attempt is (0.9)^29 * 0.1 * (0.1)^2.
Note that these calculations assume that each shot is independent of the others and that the shooter's probability of making a shot remains constant throughout the attempts.
To learn more about probability click here:
brainly.com/question/31486003
#SPJ11
PLSSS HELP!!!!!!!!!!!!!

Answers
through: (-1, 4) and (-4, 2)
Answers
Midpoint= (-2.5, 3)
\( distance \: = \sqrt{13} \)
Equation:
\(y = \frac{2x}{3} + \frac{14}{3} \)
Answer:
\(First \: you \: find \: the \: gradient \: of \: the \\ \: line \: using \: the \: formula\)
\( \frac{ {y}{2} - y1}{x2 - x1} \)
\( \frac{ 4 - 2}{ - 1 - - 4} = \frac{2}{3} = 0.66666666666\)
\(Next, use \: the \: equation \: of \: a \: line \: \\ which \: is\)
\((y - y1) = m(x - x1)where \: m \: is \: the \: gradient.\)
\((y - 4) = 0.66666666666(x - - 1)\)
\( = y - 4 = x + 0.66666666666\)
\(Therefore,\)
\(y = x + 4.66666667\)
Step-by-step explanation:
\(Sry \: if \: it \: is \: wrong...\)
\(\huge\red{T}\pink{H}\orange{A}{N}\blue{K}\gray{S}........\)
need help!!!!
No guessing,no links

Answers
Answer:
d = mn/F
Step-by-step explanation:
F = mn/d
multiply both sides with d
d*F = mn/d*d
dF=mn
divide F from both sides
d/F = mn/F
So..
d = mn/F
Answer:
Given:
\( \boxed{ \mathsf{F = \frac{mn}{d} }}\)
Divide both sides by "mn":
\( \mathsf{ \frac{F}{mn} = \frac{mn}{d \times mn} }\)
The two mn's on the RHS gets canceled out. So we're left with:
\( \mathsf{ \frac{F}{mn} = \frac{1}{d} }\)
Invert the fractions present on either side of the "equals" sign
(In other words, flip it on its head so its numerator becomes its denominator and vice):
\( \mathsf{ \frac{mn}{F} = \frac{d}{1} }\)
Hence, we got the value of d:
\( \underline{\mathsf{ d= \frac{mn}{F} }}\)
one year the population of a city was 292000 now its 289080 find the percent decrease
Answers
Answer:
1%
Step-by-step explanation:
\( \frac{292000 - 289080}{292000} = 0.01 = 1\%\)
Answer:
1%
Step-by-step explanation:
ok
Discuss the downsizing process in your own words and provide an
example.
Answers
Downsizing refers to the process of reducing the size and workforce of a company to cut costs, increase efficiency, or adapt to changing market conditions. It involves eliminating positions, reducing staff numbers, or even closing down certain business units or branches.
Downsizing can occur for various reasons, such as financial difficulties, mergers and acquisitions, technological advancements, or strategic reorganization. Companies often assess their operational costs and decide to downsize to improve their financial performance.
During the downsizing process, companies may calculate the potential cost savings by considering factors such as salaries, benefits, severance packages, and operational expenses. For example, if a company decides to eliminate 100 positions with an average salary of $50,000 per year, it could result in annual savings of $5 million.
While downsizing can help companies achieve short-term cost reductions, it often has significant implications for the affected employees, including layoffs, reduced morale, and increased workload for remaining staff. It is crucial for organizations to handle the downsizing process with sensitivity and transparency, providing support to affected employees and communicating the rationale behind the decisions.
It is important to note that downsizing should not be seen as a long-term solution, but rather as a strategic measure to address specific challenges. Companies should also explore alternatives to downsizing, such as retraining and redeploying employees, implementing productivity improvements, or seeking new business opportunities, to ensure sustainable growth and success in the long run.
To know more about workforce, visit;
https://brainly.com/question/28843491
#SPJ11
HHHHHEEEEELLLLLPPPPP. MMMMMEEEEE

Answers
Answer:
Sorry if I’m wrong but is it ... 90???
Step-by-step explanation:
========================================================
Work Shown:
The given list is {95, 89, 99, 85, 82, 81, 99}
Sort this list from smallest to largest.
We then have this: {81, 82, 85, 89, 95, 99, 99}
Next we will erase the first and last items in that sorted list above
Doing so leads to this smaller list: {82, 85, 89, 95, 99}
Repeat the step from before. Erase the first and last items
We now have {85, 89, 95}
One more time lets erase the first and last items getting {89}
This shows that 89 is the very center item
Going back to {81, 82, 85, 89, 95, 99, 99} we see that 89 is at the center with three items below it (81,82,85) and three items above it (95,99,99)
Therefore, the median is 89.
----------------------------------
Another route to take is to count the number of items in {81, 82, 85, 89, 95, 99, 99}. You should count 7 items.
Add 1 and divide by 2 to get (7+1)/2 = 8/2 = 4
The median is in slot 4, which is exactly where 89 is located in the list {81, 82, 85, 89, 95, 99, 99}
Note: this trick only works if you have an odd number of items in a set.
Suppose that =. 5, =. 2, n1 = 20, and n2 = 30. What is the standard deviation of the sampling distribution p1 – p2?
Answers
The standard deviation of the sampling distribution (p1 - p2) is approximately 0.1282.
To calculate the standard deviation of the sampling distribution (p1 - p2) when the proportions p1 and p2,
as well as the sample sizes n1 and n2, are given,
we can use the following formula:
Standard deviation (σ) of (p1 - p2)
= \(\sqrt{p1 * (1 - p1) / n1) + (p2 * (1 - p2) / n2)}\)]
In this case, we are given:
p1 = 0.5 (proportion)
p2 = 0.2 (proportion)
n1 = 20 (sample size)
n2 = 30 (sample size)
Plugging these values into the formula, we get:
σ = [\(\sqrt{(0.5 * (1 - 0.5) / 20) + (0.2 * (1 - 0.2) / 30)]}\)
Calculating each part separately:
Part 1: (0.5 × (1 - 0.5) / 20) = 0.0125
Part 2: (0.2 × (1 - 0.2) / 30) = 0.004
Adding both parts and taking the square root:
σ = \(\sqrt{(0.0125 + 0.004) }\)
σ ≈ 0.1282
Learn more about Standrad Deviation here:
https://brainly.com/question/13498201
#SPJ11
Which of the following is rational?
1) 3xPi
2) 2/3+9.26
3) \/45+\/26
4) 14.3+5.7876239...
BTW this ( \/ ) means the squared sybol. i did it like that because iididn't know how to do the squared symobl on a keyboard.
_
And the 3 in 14.3 is a repeating 3
Answers
Do you think Lasso, ridge regression and random forest approach
suggested in the article will work in Malaysia? Justify your answer
with references.
Answers
Lasso, ridge regression, and random forest models have been applied successfully in Malaysia to predict economic growth, crime rates, and the performance of Islamic banking institutions.
Lasso, ridge regression, and random forest approach that are suggested in the article could be applied to Malaysia. Lasso and ridge regression are regression models that are used to prevent overfitting, which is common when there are many predictors and few observations. Random forest is a decision tree-based model that is used for classification and regression analysis.
The study by Ashraf and Khan (2018) aimed to predict the economic growth of Malaysia by using regression models. The study used the Lasso regression model as it has been used for feature selection, where it can automatically remove unnecessary predictors from the model, and is good at handling multicollinearity. The study concluded that Lasso regression was the best model to predict economic growth in Malaysia.
In another study by Rizwan et al. (2017), it was found that random forest could be used to predict crime rates in Malaysia with a high degree of accuracy. In a study by Sulaiman et al. (2020), it was found that ridge regression can be used to predict the performance of Islamic banking institutions in Malaysia.
To conclude, Lasso, ridge regression, and random forest models have been applied successfully in Malaysia to predict economic growth, crime rates, and the performance of Islamic banking institutions.
Therefore, it can be said that these models can be used in Malaysia to make predictions.
Know more about economic growth here,
https://brainly.com/question/33408189
#SPJ11
A class used cars and vans to go on a field trip because all of the buses were already in use. They Used 10 vehicles to go on the trip. Each car holds 5 students and each van holds 13 students. If 82 students went on the trip, then how many of each type of vehicle did the class use?
Answers
Answer:
4 vans, 6 cars
Step-by-step explanation:
solve each trigonometric equation such as \(0 \leqslant x \leqslant 2\pi\)give answers in exact form
![solve each trigonometric equation such as [tex]0 \leqslant x \leqslant 2\pi[/tex]give answers in exact](https://i5t5.c14.e2-1.dev/h-images-qa/contents/attachments/Uds4QEfDLzYeEWJ2hXaefpKSH4YqL1LU.jpeg)
Answers
Consider the given equation,
\(\sqrt[]{2}\cos (x)+1=0\)Transpose the terms,
\(\sqrt[]{2}\cos (x)=-1\Rightarrow\cos (x)=\frac{-1}{\sqrt[]{2}}\)Consider that the cosine function is negative in the 2nd and 3rd quadrant.
So one value of 'x' will lie in each quadrant.
Consider that 'x' lies in the 2nd quadrant,
\(\cos (x)=\cos (\pi-\frac{\pi}{4})\Rightarrow x=\pi-\frac{\pi}{4}\Rightarrow x=\frac{3\pi}{4}\)Consider that 'x' lies in the 3rd quadrant,
\(\cos (x)=\cos (2\pi-\frac{\pi}{4})\Rightarrow x=2\pi-\frac{\pi}{4}\Rightarrow x=\frac{7\pi}{4}\)Thus, the two solutions of the equation are obtained.
An item on sale costs 85% of the original price. The original price was $57. What is the answer?
Answers
Answer:
85%oforiginal price=selling cost
selling cost=85/100×$57=$48.45
Pedro was curious if circles AAA and BBB (with XXX and YYY being on each circle, respectively) were similar, so he tried to map one figure onto the other using rigid transformations.
Pedro concluded:
"It's not possible to map circle AAA onto circle BBB using a sequence of rigid transformations, so the circles are not similar."
What error did Pedro make in his conclusion?
Choose 1 answer:
(Choice A)
A
One more transformation — a rotation — would map circle AAA onto circle BBB. So the circles are similar.
(Choice B)
B
One more transformation — a dilation — would map circle AAA onto circle BBB. So the circles are similar.
(Choice C)
C
There is no error. This is a correct conclusion.
Answers
it is B the answer B yes B
Answer:
B
Step-by-step explanation:
solve each equation for the variable

Answers
Hope this helps, if I’m right :p
28 cookies out of 40 cookies are chocolate chip. What percent of the cookies are chocolate chip?
Please help me solve this.
Answers
Answer:
I’m pretty sure the answer would be 64%
Answer:
70%
Step-by-step explanation:
Find a number you can multiply 40 by, and find a number you can multiply 100 by to equal the same number.
Can a 5 year old count to 100?
Answers
Yes, a 5 year old can typically count to 100.
What is counting?Counting is the process of determining the number of elements in a given set or group of objects. Counting is a basic numerical skill that is used in mathematics and other fields. It involves recognizing patterns and comparing numbers to identify how many items are in a given set. Counting is an important part of early childhood education, as it introduces children to the concepts of number and quantity.
Depending on the child's exposure to numbers, they may be able to count even higher. Counting to 100 is a fundamental skill that can be developed through practice and repetition. Teaching a 5 year old to count to 100 can be done through activities such as counting objects, counting steps, and playing counting games.
To know more about counting click-
https://brainly.com/question/10275154
#SPJ4