Parametrize the curve obtained by intersecting the cylinder x^2 + z^2 = 4 and the plane y = x. Make a single sketch showing both surfaces and their curve of intersection. Finally, find an equation of a second cylinder on which this curve lies.
Answers
The curve of intersection is given by (x,y,z) = (2cos(t),2cos(t),2sin(t)), where t is the angle of rotation. A second cylinder containing this curve has equation (x-y)^2 + z^2 = 4.
To parametrize the curve of intersection, we can substitute y = x into the equation of the cylinder to obtain x^2 + z^2 = 4 - this gives us a circle of radius 2 centered at the origin in the xz-plane. We can then parametrize this circle using polar coordinates as x = 2cos(t) and z = 2sin(t), where t is the angle of rotation.
Substituting y = x into the equation of the plane, we obtain y - x = 0 or y = x. Therefore, the curve of intersection lies on the plane y = x. Using the above parametrization of the circle, we can express the curve of intersection as the set of points (x, y, z) = (2cos(t), 2cos(t), 2sin(t)).
To sketch both surfaces and their curve of intersection, we can draw the cylinder as a circular cylinder with radius 2 along the x-axis, and the plane as a tilted plane passing through the origin with slope 1. The curve of intersection lies on both surfaces and is the intersection of the cylinder with the plane. It is a circle lying in the plane y = x and centered at the origin.
To find an equation of a second cylinder on which this curve lies, note that the curve lies in the plane y = x, which means that any cylinder whose cross section is a circle lying in the plane y = x will contain this curve. Therefore, an equation of a cylinder containing this curve is given by (x - y)^2 + z^2 = r^2 for some radius r. We can verify that the curve lies on this cylinder by substituting x = 2cos(t) and z = 2sin(t) into the equation and simplifying:
(x - y)^2 + z^2 = (2cos(t) - 2cos(t))^2 + (2sin(t))^2 = 4sin^2(t) = 4(1 - cos^2(t)) = 4 - 4cos^2(t)
This is the same as the equation of the original cylinder x^2 + z^2 = 4 after we eliminate y. Therefore, the curve lies on the cylinder (x - y)^2 + z^2 = 4.
Learn more about curve of intersection:
https://brainly.com/question/11482157
#SPJ11
Related Questions
1. which equation is equivalent to the equation 6x 9 = 12? a. x 9=6 b. 2x 3 = 4 c. 3x 9 = 6 d. 6x 12 = 9​
Answers
Using Equivalent equation, equation in option (b) i.e 2x+3 = 4 is equivalent to equation, 6x + 9 = 12. So, The Correct option is Option (b) .
Equivalent equation (Algebra) :
Combine any like terms on each side of the equation: x-terms with x-terms and constants with constants. Arrange the terms in the same order, usually x-term before constants. Then equivalent equation are algebaric expression which having same roots or solution .
We have given an expression as
6x + 9 = 12 --(1)
we have to find out an equation out of given options which is equivalent to equation(1) .
firstly , we evaluate the given expresion and find out solution i.e x .
6x + 9 = 12
Substracts 9 from both sides
=> 6x = 12 -9 = 3
both sides dividing by 6
=> x = 3/6 = 1/2
so, 1/2 is solution
Now, we check the options one by one
a) x + 9 = 6
solving it we get, x = 6- 9 = -3
=> not equivalent
b) 2x + 3 = 4
=> 2x = 4 - 3 = 1
=> x = 1/2
same solution as solution of given expresion
c) 3x+9 = 6
=> 3x = 6-9 = -3
=> x =-1
i.e not equivalent
d) 6x + 12 = 9
=> 6x = 9-12 = -3
=> x = -3/6 = -1/2
=> not equivalent
Hence, the required expression is 2x + 3 = 4
To learn more about equivalent equation, refer:
https://brainly.com/question/2972832
#SPJ4
Finding the Area Under a Curve Using Technology
As an apprentice working for 1 plus 1 Landscaping, you’re learning the tricks of the trade. Your boss wants you to calculate the area between the edge of a garden bed and the side of a house. Using the area, she can calculate the amount of mulch she will need for this job. The edge is defined by the equation y = x + 1
Answers
Finding the area under a curve using technology requires knowledge of calculus or a graphing calculator with a built-in integral function.
We can use either method to find the area between the edge of the garden bed and the side of the house.
To find the area between the edge of the garden bed and the side of the house, we need to integrate the function that represents the distance between the two. In this case, the distance between the edge of the garden bed and the side of the house is given by the equation y = x + 1.
To integrate this function, we can use calculus or a graphing calculator with a built-in integral function. Calculus involves finding the antiderivative of the function, while a graphing calculator can use numerical methods to approximate the integral.
If using a graphing calculator, we can graph the function y = x + 1 and then use the integral function to find the area between the curve and the x-axis. The result will be the area between the edge of the garden bed and the side of the house, which can be used to calculate the amount of mulch needed for the job.
Learn more about calculus here:
https://brainly.com/question/6581270
#SPJ4
Helppppppppppppppppppppppppppppppppppppppppppppppp\
Due soonnnnnn T-T

Answers
Step-by-step explanation:
1)......mean= sum of observations/ total observations
= 5.2+8.4+4.3+6.7+5.8/5= 6.08
median= n=5(odd)=n+1/2=6/2=3rdterm= 5.8( when arranged in ascending order).....
mode= 3median- 2meam= 3×5.8-2×6.08= 5.24
range=8.4-4.3=4.1(when done A.O)
2)......mean= -2-13-13-5-7/5= -8
median= 3rd term= -5.....(n=5..odd)(when done A.o)
mode=largest frequency= -13
range= -13-(-2) = -13+2= -11(A.O)
3).....mean= sum/no.= 8+6+13/2+17/2+15/2+7+8+11/2+7+8//10=7.2
median=n=10(even)
=
mode= 8
range=8.5-5.5=3
median:==
(10/2)+(10/2+1)//2=5 term + 6term/2=7+7.5=14.5/2=7.25
4)....
5)...remove 62...then 73will be having highest frequency
A medical company is building a model to predict the occurrence of thyroid cancer. The training data contains 900 negative instances (people who don't have cancer) and 100 positive instances. The resulting model has 90% accuracy, but extremely poor recall. What steps can be used to improve the model's performance? (SELECT TWO)
A. Under-sample instances from the positive (has cancer) class
B. Generate synthetic samples using SMOTE
C. Over-sample instances from the negative (no cancer) class
D. Collect more data for the positive case
E. Use Bagging
Answers
To improve the model's performance in predicting thyroid cancer occurrence, two potential steps to consider are: generating synthetic samples using SMOTE and collecting more data for the positive cases. option b and d
The given problem scenario involves imbalanced classes, with a significantly higher number of negative instances compared to positive instances. This class imbalance can lead to biased model performance, such as poor recall for the minority class (positive instances in this case). Here are the two selected steps and their rationale:
B) Generating synthetic samples using SMOTE: SMOTE is a technique used to address class imbalance by creating synthetic samples of the minority class. It generates new instances by interpolating between neighboring instances of the minority class. By using SMOTE, the positive class can be over-sampled, increasing the representation of thyroid cancer cases in the training data. This can help the model learn better decision boundaries for positive instances and improve recall.
D) Collecting more data for the positive cases: Increasing the number of positive instances in the training data can provide the model with more information to learn from. Collecting additional data specifically for positive cases, such as acquiring more samples of individuals diagnosed with thyroid cancer, can help in better capturing the characteristics and patterns associated with cancer occurrence. This can lead to a more balanced representation of the classes and potentially improve recall.
While options A (under-sampling instances from the positive class) and E (using Bagging) are also strategies to address class imbalance, they may not be as effective in this specific scenario. Under-sampling positive instances may further reduce the information available for learning, and Bagging, although useful for ensemble learning, may not directly address the class imbalance issue or improve recall.
learn ore about training data here:
https://brainly.com/question/31866369
#SPJ11
An observation that has a strong effect on the regression results is called a(n) O a. influential observation b. residual O c. sum of squares error d. None of these answers are correct.
Answers
The correct answer to the question is option a) influential observation. An influential observation is an observation that has a significant impact on the regression results, meaning that if it is removed, the regression equation and the coefficients can change significantly.
In other words, it can have a strong effect on the fit of the regression model.
For instance, an influential observation could be an outlier, a point that deviates significantly from the general pattern of the data. This point can affect the slope and intercept of the regression line, and therefore the predictions and inference based on the model. Another example of an influential observation could be a point that has a high leverage, meaning that it has a high leverage on the estimated coefficients due to its position in the predictor space.
Therefore, it is essential to detect and address influential observations when building regression models to ensure that the results are reliable and valid. Techniques such as Cook's distance and leverage plots can be used to identify influential observations and various methods can be employed to deal with them, such as removing them, transforming the data, or using robust regression techniques.
To learn more about regression, refer:-
https://brainly.com/question/31735997
#SPJ11
Please help me with this please and thank you please actually help me

Answers
Step-by-step explanation:
f(-1) = 4(2)^-1 ≈ 4 × 1/2 = 2
(x, f(x)) = (-1, 2)
f(0) = 4(2)⁰ = 4×1 = 4
(x, f(x)) = (0, 4)
f(1) = 4(2)¹ = 4×2 = 8
(x, f(x)) = (1, 8)
f(2) = 4(2)² = 4×4 = 16
(x, f(x)) = (2, 16)
6.1.11 suppose we have a statistical model {fθ : θ ∈ [0, 1]} and we observe x0. is it true that 8 1 0 l(θ | x0) dθ = 1? explain why or why not.
Answers
No, it is not true that ∫_0^1 l(θ | x0) dθ = 1. The integral of the likelihood function l(θ | x0) over the parameter space [0, 1] does not necessarily equal 1.
The likelihood function l(θ | x0) measures the probability of observing the data x0 given the parameter value θ. It is a function of the parameter θ, and not a probability distribution over θ.
Therefore, the integral of the likelihood function over the parameter space does not have to equal 1, unlike the integral of a probability density function over its support.
In fact, the integral of the likelihood function over the parameter space is often referred to as the marginal likelihood or the evidence, and is used in Bayesian inference to compute the posterior distribution of the parameter θ given the data x0. The marginal likelihood is given by: ∫_0^1 l(θ | x0) p(θ) dθ
where p(θ) is the prior distribution of the parameter θ. The marginal likelihood is used to normalize the posterior distribution so that it integrates to 1:
p(θ | x0) = l(θ | x0) p(θ) / ∫_0^1 l(θ | x0) p(θ) dθ
In conclusion, the integral of the likelihood function over the parameter space does not necessarily equal 1, and is used in Bayesian inference to compute the posterior distribution of the parameter θ given the data x0.
You can read more about probability at https://brainly.com/question/24756209
#SPJ11
Use properties of operations to write an expression equivalent to the expression below.
p6+(q+8)
Answers
Answer:
q8+p6=14
Step-by-step explanation:
Answer:
Answer:14
Step-by-step explanation:
Use PEMDAS
What is a multiplecation and division sentence for there are 9thirds in 3ones
Answers
Answer:
Eight $5 bills are worth $40. 5x8=40 40/5=8
There are 9 thirds in 3 ones. 3x3=9 9/3=3
A tape diagram of 5 equal parts. Each part is labeled one fifth. Above the bar is a bracket, labeled 1, that spans the entire length of the bar.
5x 0.20=1 5/1= 0.20
Step-by-step explanation:
Still stuck? Get 1-on-1 help from an expert tutor now.n:
−12 = 9 + 5v + 2v what is it
Answers
Answer:
-3=v
Step-by-step explanation:
-12=9+7v
-9 from both sides
-21=7v
Divide both sides by 7
-3=v
Hope this helps:) Have a good day!
Answer:
v = - 3
Step-by-step explanation:
- 12 = 9 + 5v + 2v , that is
- 12 = 9 + 7v ( subtract 9 from both sides )
- 21 = 7v ( divide both sides by 7 )
- 3 = v
Hey guys! Need help asap! Pls help! Will give brainliest!!!
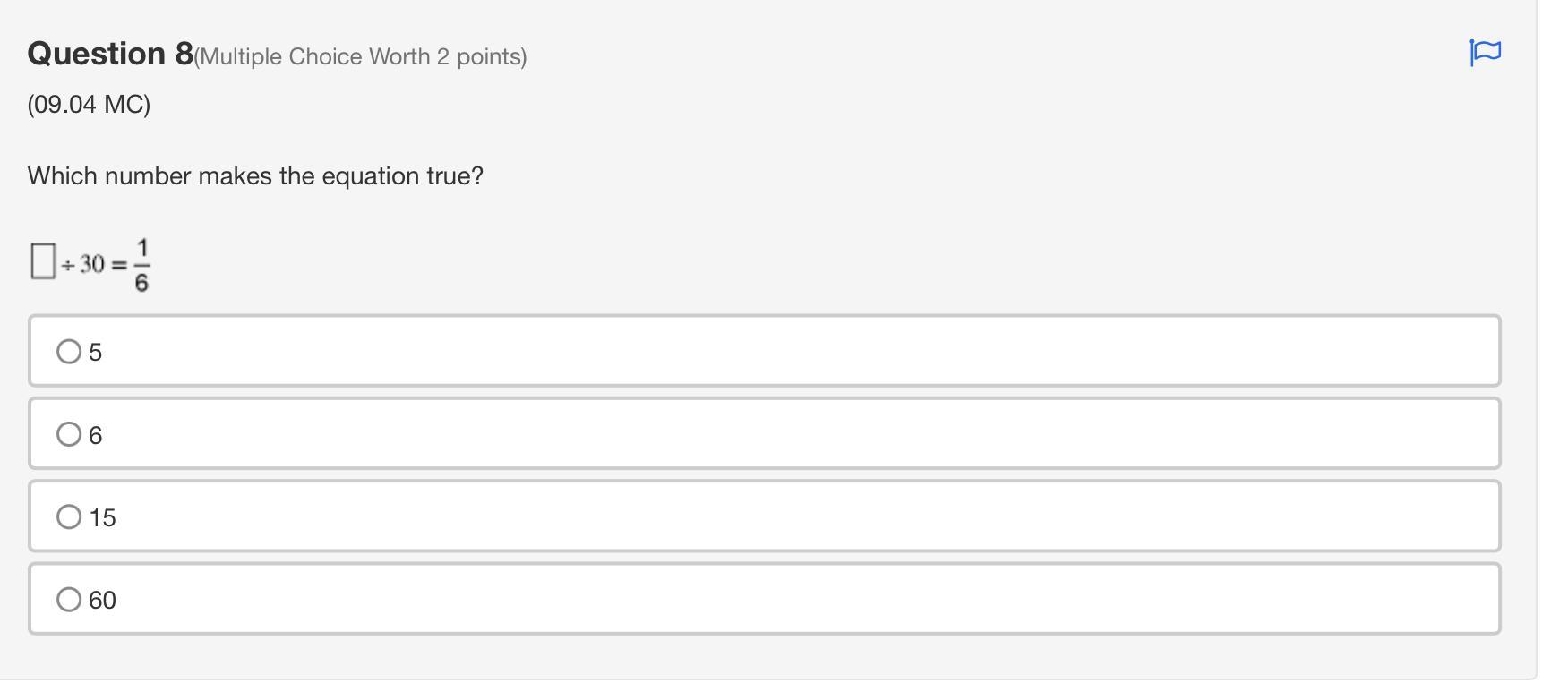

Answers
Answer:
The answer for 1 = B for second one it is D
6. The right triangles ABC and DEF
are similar. The hypotenuse of ABC
measures 12 cm and the hypotenuse
of DEF measures 24 cm. If one of
the legs of ABC measures 9 cm,
what does the corresponding leg
of DEF measure?
A 4.5 cm
B 18 cm
Answers
Answer:
B. 18 cm
Step-by-step explanation:
24 / 12 = 2.
9 x 2 = 18 cm.
Hope this helps!
Follow the Order of Operations to simplify each expression below. 2(9-6)2/18
Answers
Answer:
3
Step-by-step explanation:
What is the slope for theses two

Answers
graphing lines and killing zombies
Graph the equations on a graph and pick which zombie the arrow points to. then write down each one starting from 1 to 12.

Answers
The order of points is:
1. -33 5. -55 9. 2.4
2. -23 6. -2.6 10. 7.6
3. -11.5 7. -2.5 11. 9.3
4. -10 8. 2.33 12. 10.6
Given,
The equations:
1. y = (-2/3) × -16 = 10.66
2. y = (1/2) × -23 = -11.5
3. y = (3/2) × -22 = -33
4. y = (4/3) × -2 = -2.66
5. y = (1/3) × 23 = 7.66
6. y = (1/2) × -5 = -2.5
7. y = (-1/4) × 22 = -5.5
8. y = 1 × -23 = -23
9. y = (4/3) × 7 = 9.33
10. y = (1/3) × 7 = 2.33
11. y = -1 × 10 = -10
12. y = (-2/5) × -6 = 2.4
We have to order this from 1 to 12. That is ascending order:
Here is the equations:
1. y = (3/2) × -22 = -33
2. y = 1 × -23 = -23
3. y = (1/2) × -23 = -11.5
4. y = -1 × 10 = -10
5. y = (-1/4) × 22 = -5.5
6. y = (4/3) × -2 = -2.66
7. y = (1/2) × -5 = -2.5
8. y = (1/3) × 7 = 2.33
9. y = (-2/5) × -6 = 2.4
10. y = (1/3) × 23 = 7.66
11. y = (4/3) × 7 = 9.33
12. y = (-2/3) × -16 = 10.66
Learn more about equations here:
https://brainly.com/question/14603452
#SPJ1
Determine whether the following sets form subspaces of R2.
(a) {(x1,x2)T|x1 + x2 = 0}
(b) {(x1,x2)T|x21 = x22}
Answers
(a) The set {(x1,x2)T|x1 + x2 = 0} is a subspace of R2.
To check whether the given set is a subspace of R2, we need to check whether it is closed under vector addition and scalar multiplication. Let u = (u1,u2)T and v = (v1,v2)T be two arbitrary vectors in the set, and let c be an arbitrary scalar. Then:
u + v = (u1 + v1, u2 + v2)
Since u1 + v1 + u2 + v2 = (u1 + u2) + (v1 + v2) = 0 + 0 = 0 (since u and v are in the set), we see that u + v is also in the set.
c*u = (c*u1, c*u2)
Since c*u1 + c*u2 = c*(u1 + u2) = c*0 = 0 (since u is in the set), we see that c*u is also in the set.
Therefore, the set {(x1,x2)T|x1 + x2 = 0} is a subspace of R2.
(b) It is not a subspace of R2
To check whether the given set is a subspace of R2, we need to check whether it is closed under vector addition and scalar multiplication.
Let u = (u1,u2)T and v = (v1,v2)T be two arbitrary vectors in the set, and let c be an arbitrary scalar. Then:
u + v = (u1 + v1, u2 + v2)
Since u21 = u22 and v21 = v22 (since u and v are in the set), we see that (u1 + v1)2 = (u2 + v2)2. Therefore, u + v is in the set.
c*u = (c*u1, c*u2)
Since u21 = u22 (since u is in the set), we see that (c*u1)2 = (c*u2)2. Therefore, c*u is in the set.
However, the set {(x1,x2)T|x21 = x22} is not a subspace of R2 because it does not contain the zero vector (0,0)T, which is required for any set to be a subspace.
To know more about set subspace refer here:
https://brainly.com/question/14983844?#
#SPJ11
Solve for X. I don’t know how to solve

Answers
The value of x is approximately 10.57 and the value of y is approximately 15.25.
Describe Chords?In mathematics, a chord is a straight line segment that connects two points on a curve. More specifically, a chord is a line segment that has its endpoints on the curve.
The term "chord" is most commonly used in the context of circle geometry, where a chord is a line segment that connects two points on the circumference of a circle. In this context, the length of a chord can be calculated using the Pythagorean theorem, given the lengths of the radii of the circle and the distance between the endpoints of the chord.
In a circle, if four chords are connected to form a quadrilateral, then opposite angles of the quadrilateral are supplementary. Using this property, we can set up the following equation:
105 + (7y + 1) + (7x + 1) + (4y + 14) = 180
Simplifying and solving for x and y, we get:
7x + 4y + 122 = 180
7x + 4y = 58 ......(1)
Also, we know that the opposite angles of a cyclic quadrilateral are supplementary. Therefore, we can set up the following equations:
105 + (4y + 14) = 180 ......(2)
(7y + 1) + (7x + 1) = 180 ......(3)
Simplifying and solving for y in equation (2), we get:
4y + 119 = 180
4y = 61
y = 15.25
Substituting this value of y in equation (3) and solving for x, we get:
(7x + 1) + (7*15.25 + 1) = 180
7x + 106 = 180
7x = 74
x = 10.57
Therefore, the value of x is approximately 10.57 and the value of y is approximately 15.25.
To know more about equation visit:
https://brainly.com/question/15298662
#SPJ1
A quarterback throws an incomplete pass. The height of the football at time t is modeled by the equation h(t) = –16t2 + 40t + 7. Rounded to the nearest tenth, the solutions to the equation when h(t) = 0 feet are –0.2 s and 2.7 s. Which solution can be eliminated and why?
The solution –0.2 s can be eliminated because time cannot be a negative value.
The solution –0.2 s can be eliminated because the pass was not thrown backward.
The solution 2.7 s can be eliminated because the pass was thrown backward.
The solution 2.7 s can be eliminated because a ball cannot be in the air for that long due to gravity.
Answers
The solution that will be eliminated when a quarterback throws an incomplete pass is –0.2 s can be eliminated because time cannot be a negative value
What is parabolic equation?This is the equation used to trace the path made by a parabola. It is another name for quadratic equation.
We can say that the football traced a parabolic path represented by the equation h(t) = –16t2 + 40t + 7.
Parabolic equation will always produce two solutions then depending on the applicability of the solution the best option will be picked.
In this case time, which cannot be a negative value hence option A is the correct answer
Read more on parabolic equations here: https://brainly.com/question/2956567
#SPJ1
gcf of 6x^2 and 18x^5
Answers
The answer is 6x^2. To find this, just find the greatest factor of each question, aka the greatest "common" factor (GCF), of both since it is the greatest factor they each have in common. Hope this helps!
A square tile mesures 20 cm by 20cm a rectangular tile is 3 cm longer and 2 cm narrower. What is the different in area between the two tiles?
Answers
Answer:
Rectangular tile has 14 cm² larger area-----------------
Find each area and then find their difference.
A(square) = 20² = 400 cm²A(rectangle) = (20 + 3)(20 - 2) = 23*18 = 414 cm²The difference is:
414 - 400 = 14 cm²our boss is a biologist who needs wood samples from long-leaf pine trees with a fungal disease which is only visible under a microscope, and she sends you on an assignment to collect the samples. She wants at least 50 different diseased samples. She tells you that approximately 28% of long-leaf pine trees currently have the fungal disease. If you sample 160 long-leaf pine trees at random, what is the probability you’ll have at least 50 diseased samples to return to your boss? (Use the normal approximation to calculate this probability and chose the closest answer to the question.)
Answers
Answer:
Step-by-step explanation:
In this scenario, the probability of success, p is 28% = 28/100 = 0.28
Number of samples, n = 160
Probability of failure, q = 1 - p = 1 - 0.28 = 0.72
Mean,µ = np = 0.28 × 160 = 44.8
Standard deviation, σ = √npq = √160 × 0.28 × 0.72 = 5.68
Let x be the random variable representing the number of wood samples from long-leaf pine trees with a fungal disease. Since it is normally distributed and the population mean and population standard deviation are known, we would apply the formula,
z = (x - µ)/σ
Where
x = sample mean
µ = population mean
σ = standard deviation
the probability that you’ll have at least 50 diseased samples to return to your boss is expressed as
P(x ≥ 50) = 1 - P(x < 50)
For P(x < 50)
z = (50 - 44.8)/5.68 = 0.91
Looking at the normal distribution table, the probability corresponding to the z score is 0.819
Therefore,
P(x ≥ 50) = 1 - 0.819 = 0.181
What is the measure of Boc

Answers
Answer:
BOC, since angle B and angle C are bisected, sum of angle OBC and OCB will be half of sum of angles B and C which is 108 degrees.
uiz / 3 of 5
Two different cell phone companies charge a monthly fee, plus a cost per text message. Cell phone company M charges a monthly fee of
$10, plus $0.15 per text message. The table below shows monthly charges of cell phone company N based on the number of texts.
Phone Company N
Number of Monthly
Texts
Charge
(x)
(y)
25
$17.50
50
$20.00
75
$22.50
Answers
Answer:
$22.50....................
please answer this for me

Answers
Answer:
x=409
Step-by-step explanation:
you just solve, -15+5x=2030
add 15 both sides->5x=2030
divide by 5 both sides-> x=409
Answer:
409
Step-by-step explanation:
Mark as Brainliest!!! Hopes This Helps:)
Any has 10 pieces of fruit. 7 are apples and the rest are oranges.
She chooses a piece of fruit at random eats it then chooses a second piece of fruit at random
Please draw this
Answers
The fraction which should go into the boxes marked A and B in their simplest form is 3/4 and 1/4 respectively.
What fraction should go into the boxes?Total number of fruits Amy has = 10
Number of Apples = 7
Number of Oranges = 3
First random pieces of fruits chosen:
Probability of choosing Apples = 6/9
Probability of choosing Oranges = 3/9
Second random pieces of fruits chosen:
Probability of choosing Apples = 6/8
= 3/4
Probability of choosing Oranges = 2/8
= 1/4
Therefore, the probability of choosing Apples or oranges as the second piece is 3/4 or 1/4 respectively.
Read more on probability:
https://brainly.com/question/251701
#SPJ1

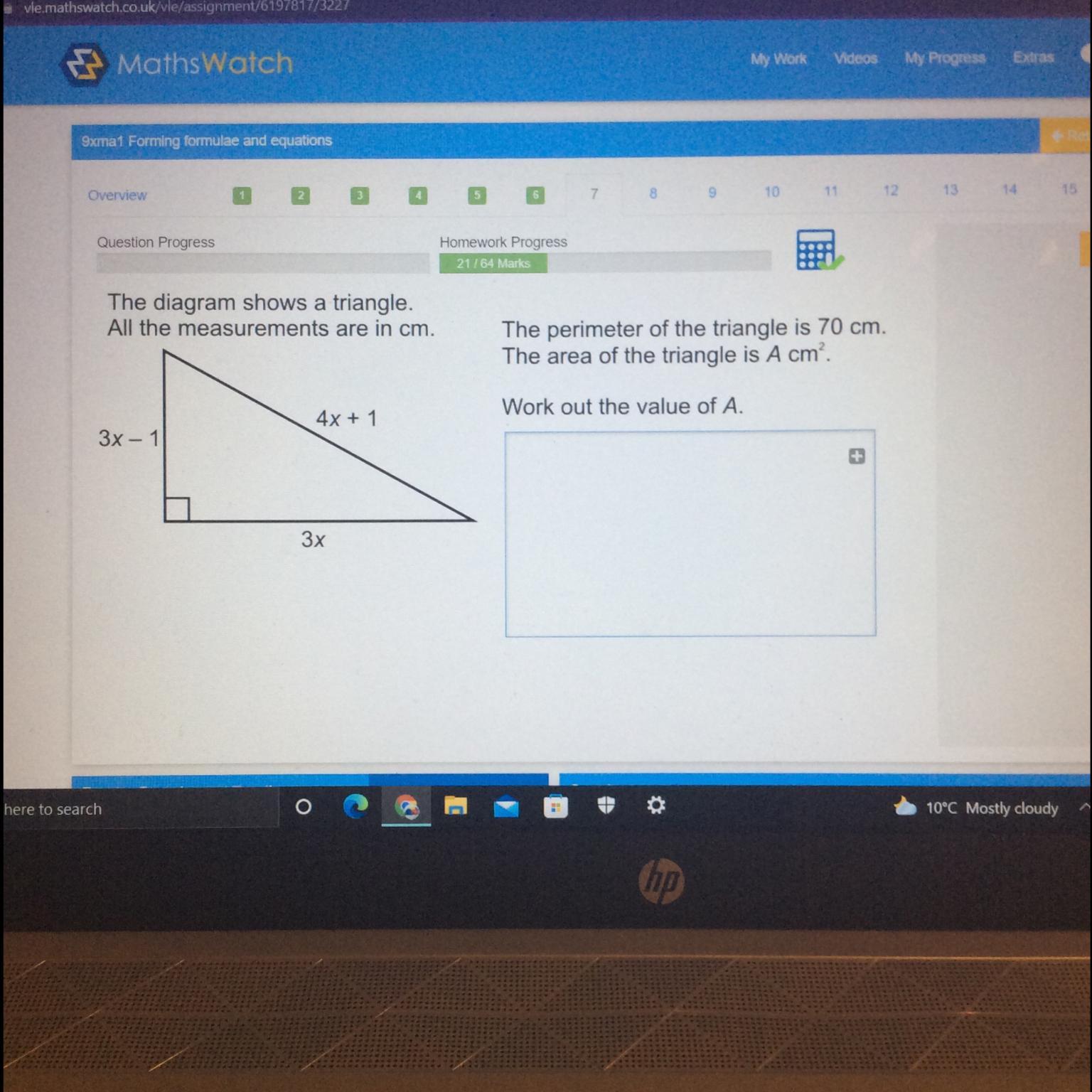
The diagram shows a triangle.
All the measurements are in cm.
The perimeter of the triangle is 70 cm.
The area of the triangle is A cm.
Work out the value of A.
4x + 1
3x - 1
-
Зх
Answers
Answer: 210
Explanation:
Recall that the perimeter is the distance around the figure. It's the amount of fencing needed to enclose such a shape.
Add up all three sides and set the sum equal to the perimeter 70. Then solve for x.
side1+side2+side3 = perimeter
(3x)+(3x-1)+(4x+1) = 70
10x = 70
x = 70/10
x = 7
We can then calculate each side
horizontal leg = 3x = 3*7 = 21vertical leg = 3x-1 = 3*7-1 = 21-1 = 20hypotenuse = 4x+1 = 4*7+1 = 28+1 = 29Notice how 21+20+29 = 70 to confirm we have the correct side lengths.
Once we know the horizontal and vertical leg (aka base and height), we can find the area.
Area = 0.5*base*height
Area = 0.5*21*20
Area = 210 square cm
Step-by-step explanation:
first you have to find x . Then you can add them and equal them with triangle area.


For each babysitting job, Tamar charges $6 for bus fare plus $8 per hour. She only accepts babysitting jobs if the total charge is at least $30. What is the minimum number of hours for a babysitting job she would accept?
A 2 and one-half hours
B 3 hours
C 4 hours
D 4 and one-half hours
Answers
Answer:
B. 3 hours
Step-by-step explanation:
It’s 6+8x=30
Answer:
B) 3 hours
Step-by-step explanation:
Hope this helped <333
PLZ HELP :)
The graph of linear functions f(x) and g(x) are shown on the graph. Which function is best represented by the graph of g(x)?
A. g(x) = 3f(x)
B. g(x) = f(x)+3
C. g(x) = f(x-3)
D. g(x) = f(x+3)

Answers
what is the difference between a value model of variables and a reference model of variables? why is the distinction important?
Answers
The difference between a value model of variables and a reference model of variables lies in how they handle data.
In a value model, variables store the actual values, while in a reference model, variables store references to the memory location where the values are stored. The distinction is important because it affects how data is shared and manipulated, impacting memory usage, performance, and behavior in programming languages.
In a value model of variables, each variable stores its own independent value. When assigning a value to a variable or passing it to a function, a copy of the value is made. This means that any modifications to the copied value do not affect the original value. Value models are commonly used in languages like C or Java, where variables represent the actual data.
In contrast, a reference model of variables stores references or pointers to memory locations where the values are stored. Instead of copying the value, the reference is copied, allowing multiple variables to refer to the same memory location and share data. Changes made to the data through one variable will be reflected in all variables referencing the same memory location. Reference models are often used in languages like Python or JavaScript, where variables act as references to objects.
The distinction between value and reference models is important because it impacts memory usage and performance. In a value model, each variable consumes its own memory space, which can be inefficient for large data structures or when passing data between functions. In a reference model, memory usage can be optimized as variables can share the same data, but it requires careful handling to avoid unintended side effects when modifying shared data.
Additionally, the distinction affects the behavior of programming languages. In a value model, modifying a variable does not affect other variables referencing the same value. In a reference model, modifications made through one variable are visible to all variables referencing the same memory location. This difference can lead to different programming patterns and requires developers to be aware of how data is shared and manipulated.
In summary, the difference between a value model of variables and a reference model of variables lies in how data is handled and shared. The distinction is important as it impacts memory usage, performance, and the behavior of programming languages. Understanding these models helps programmers choose the appropriate approach and avoid unintended consequences when working with variables and data.
To learn more about variables visit:
brainly.com/question/15078630
#SPJ11
Given that g(x) = −2x+20, find g(−3).
Answers
Answer: 26
Step-by-step explanation:
Okay, so... The new equation would be -2(-3)+20...
So follow the rule of PEMDAS, PEMDAS is;
Parentheses
Exponents
Multiplication
Division
Adding
and Subtracting
Since there are no equations in parentheses and no exponents, we start with multiplication. Which would be -2(-3). ANY parenthesized number beside another number means you must multiply them.
-2(-3) = 6 because a negative multiplied by a negative is a positive..
Now we have 6 + 20 which is 26, so 26 is your answer.