
Answers
Answer:
y = 4x - 12
Step-by-step explanation:
if it allows you to, i would plot the points first, draw the line with a straight edge connecting the two points, and then find the slope and y - intercept using that
Related Questions
The student did this problem wrong, explain what is wrong and fix their mistake to give me the correct answer.
Please help me haha

Answers
Answer:
GK parallel to HJ
F is the midpoint
GF =FJ (bisectors)
Answer:
haha
Step-by-step explanation:
To study the effect of mindfulness meditation on mental health, an experimental investigation was done by comparing serum cortisol (as an indicator of stress level) between 2 groups of medical students who volunteered to participate in the study. Group 1 took a 4- day meditation program, while Group 2 did not. Volunteers from both groups then had a blood test and their serum cortisol was measured in nmol/L. Results were as follows: Group 1: 267 245 263 316 246 282 379 300 291 306 425 190 346 150 344 Group 2 470 222 443 506 455 518 360 408 375 246 189 368 Do the results support the hypothesis that meditation helps reduce stress level, with 95% confidence? You must properly identify and follow all the necessary steps for this investigation (Hint: for comparing variances, you can use 98% confidence.)
Answers
The results of the study suggest that the 4-day meditation program had a significant effect in reducing the stress levels of the medical students compared to the group that did not participate in the meditation program.
To determine if the results support the hypothesis that meditation helps reduce stress levels, we need to perform the necessary statistical analysis. Here are the steps involved:
Step 1: Define the hypothesis:
The null hypothesis (H₀) is that there is no significant difference in stress levels between the two groups.
The alternative hypothesis (Hₐ) is that there is a significant difference in stress levels between the two groups, with meditation reducing stress.
Step 2: Identify the appropriate statistical test:
Since we are comparing the means of two independent groups and want to test if there is a significant difference, we can use an independent samples t-test.
Step 3: Set the significance level:
The significance level (α) is the probability of rejecting the null hypothesis when it is true. In this case, we will use a significance level of 0.05, corresponding to a 95% confidence level.
Step 4: Calculate the sample statistics:
Calculate the means, standard deviations, and sample sizes for both groups.
Group 1:
Mean (x1) = (267 + 245 + 263 + 316 + 246 + 282 + 379 + 300 + 291 + 306 + 425 + 190 + 346 + 150 + 344) / 15 = 290.2
Standard deviation (s1) = 70.764
Sample size (n1) = 15
Group 2:
Mean (x2) = (470 + 222 + 443 + 506 + 455 + 518 + 360 + 408 + 375 + 246 + 189 + 368) / 12 = 377.5
Standard deviation (s2) = 109.057
Sample size (n2) = 12
Step 5: Conduct the statistical test:
We can now perform an independent samples t-test using the sample statistics.
Step 5a: Test for equal variances:
Before conducting the t-test, we need to check if the variances of the two groups are equal. We can use a F-test to compare the variances.
Null hypothesis (H₀): The variances of the two groups are equal.
Alternative hypothesis (Hₐ): The variances of the two groups are not equal.
Using a significance level of 0.02 (98% confidence), we can calculate the F-statistic and compare it to the critical F-value from the F-distribution table.
F = s1² / s2² = 70.764² / 109.057² = 0.428 (approximately)
The critical F-value for a 98% confidence level with (n1-1) = 14 and (n2-1) = 11 degrees of freedom is 3.72.
Since our calculated F-value is smaller than the critical F-value, we fail to reject the null hypothesis. Thus, we can assume equal variances.
Step 5b: Conduct the t-test:
Since the variances are assumed to be equal, we can perform the independent samples t-test using the sample means and pooled standard deviation.
Pooled standard deviation (sp) = √(((n1 - 1) × s1² + (n2 - 1) × s2²) / (n1 + n2 - 2)) = √(((15 - 1) × 70.764² + (12 - 1) × 109.057²) / (15 + 12 - 2)) = 90.362
t = (x1 - x2) / (sp × √(1/n1 + 1/n2)) = (290.2 - 377.5) / (90.362 × √(1/15 + 1/12)) = -2.227
Degrees of freedom (df) = n1 + n2 - 2 = 15 + 12 - 2 = 25
Using the t-distribution table or a statistical software, we can find the critical t-value for a two-tailed test at a significance level of 0.05 with 25 degrees of freedom. The critical t-value is approximately ±2.060.
Since our calculated t-value (-2.227) is smaller than the critical t-value (-2.060), we reject the null hypothesis and accept the alternative hypothesis. Therefore, there is evidence to support the claim that mindfulness meditation helps reduce stress levels, with a 95% confidence level.
In conclusion, the results of the study suggest that the 4-day meditation program had a significant effect in reducing the stress levels of the medical students compared to the group that did not participate in the meditation program.
Learn more about Statistics click;
https://brainly.com/question/31538429
#SPJ4
why is it important in linear algebra to know that a function is a linear transformation? what's the point of knowing
Answers
The point of knowing whether a function is a linear transformation is that it simplifies the process of solving equations and makes it easier to understand the behavior of the function.
A linear transformation is a function that preserves the operations of addition and scalar multiplication, which means that it satisfies two key properties: linearity and homogeneity. If a function satisfies these properties, then it is a linear transformation. Linear transformations have several important properties that make them useful in linear algebra, including the ability to compose functions, invertibility, and the preservation of linear independence.
Knowing that a function is a linear transformation allows for the use of powerful tools such as matrix multiplication and matrix inversion, which are fundamental to many applications in linear algebra, such as solving systems of linear equations and finding eigenvalues and eigenvectors. Additionally, it provides a framework for understanding geometric transformations, such as rotations and reflections, in terms of linear algebra. Overall, understanding linear transformations is essential for effectively working with vectors, matrices, and systems of linear equations.
To learn more about matrix multiplication click here, brainly.com/question/13591897
#SPJ11
IT RAINS 15 DAYS IN JANURAY WRite the ratio of rainiy days to dry days
Answers
Answer:
3:9 6:15 14:21 15:35 all of these should work
Hey guys. So I'm doing a basic program for a battle game in Javascript, and I've having trouble on this one question. (subtraction)
If I have one number like 20, then 3 numbers such as 2, 4 and 7, I could easily find out which number in those 3 i subtracted by. For example if I had 18 as the answer, then I could do 20 - 18 and get 2 from the 3 numbers.
But how do I do that twice? or three or more after that one time? how would I know which one I picked after? (after the number is used once, it can still be used forever on, it's always random)
Answers
Answer:
can i show you how to do it
Step-by-step explanation:
Combine the following expressions. 2√k + √k - 3√k
Answers
Answer:
The answer is zero
Step-by-step explanation:
\(2 \sqrt{k} + \sqrt{k} - 3 \sqrt{k} = 3 \sqrt{k} - 3 \sqrt{k} = 0\)
Lynn is playing a board game. When starting the game, her token is at START, and she has the option of going around the board to the left or to the right. After rolling the dice, she places her token on a space that has an absolute value of four.
Select the point(s) on the number line where her token could be on her first move.
Answers
The point(s) on the number line where Lynn's token could be on her first move are -4 and 4.
Lynn is playing a board game. When starting the game, her token is at START, and she has the option of going around the board to the left or to the right. After rolling the dice, she places her token on a space that has an absolute value of four. The point(s) on the number line where her token could be on her first move are -4 and 4.
What is absolute value? Absolute value is a term used to describe the distance of a number from zero on a number line. In other words, the absolute value of a number is the distance of a number from zero without considering the sign of the number. It is represented by a vertical line on either side of a number like |x|, where x represents any number.Lynn's token can be placed on any of the spaces with an absolute value of four. These numbers are -4 and 4. Therefore, her token can be placed at either -4 or 4 in her first move.
In the given scenario, Lynn is playing a board game, and she starts at the START. Lynn can either go around the board to the right or left after rolling the dice. The problem states that her token can be placed on a space that has an absolute value of four. Therefore, her token can be placed on any of the spaces with an absolute value of four. These numbers are -4 and 4. Lynn's token can be placed at either -4 or 4 in her first move .Hence, the point(s) on the number line where Lynn's token could be on her first move are -4 and 4.
As the given problem states that Lynn's token can be placed on a space that has an absolute value of four. These numbers are -4 and 4. Lynn's token can be placed at either -4 or 4 in her first move. Hence, the point(s) on the number line where Lynn's token could be on her first move are -4 and 4.
To know more about number line visit:
brainly.com/question/32029748
#SPJ11
what is the difference between individual worship and corporate worship
Answers
Answer:
“Personal worship” signifies the individual's act of worship and “corporate worship” is the worship that individuals offer in the company of other believers.
Step-by-step explanation:
PLEASE HELP
2. Calculate the slant height for the given cone. Round to the nearest tenth
(1 point)
Diameter = 18 cm
Height = 7 cm
O 11.2 cm
O 12.5 cm
O 14.8 cm
O 11.4 cm
Answers
Answer:
11.4 cm
Step-by-step explanation:
Using pythagoras theorem,

20 PIONTS!!!!
Which set of ordered pairs does NOT represent a function? Responses
A (-3, 6), (2, 7), (0, 5), (1, 5), (4, 9), (5, 4)(-3, 6), (2, 7), (0, 5), (1, 5), (4, 9), (5, 4)
B (0, 1), (2, 2), (4, 8), (2, 7), (5, 8), (7, 9)(0, 1), (2, 2), (4, 8), (2, 7), (5, 8), (7, 9)
C (-4, 2), (-3, 2), (-2, 2), (-1, 2), (0, 2), (1, 2)(-4, 2), (-3, 2), (-2, 2), (-1, 2), (0, 2), (1, 2)
D (0, 1), (2, 2), (4, 8), (-2, 7), (5, 8)(0, 1), (2, 2), (4, 8), (-2, 7), (5, 8)
E (1, 4), (3, 7), (5, 8), (4, 9), (6, 2), (7, 8), (2, 5)
Answers
Answer:
C
Step-by-step explanation:
two - 4s
Are there more than one outlier?

Answers
Answer:
yes there is two
Step-by-step explanation:
the outlier is the ones that are away from all the others
Answer:
Yes there is
Step-by-step explanation:
There are Many more outliers since the data points are scattered
A girl buys a monthly bus pass, which entitles her to unlimited bus travel, for $40 per month. Without the pass each bus ride costs $1.60. How many rides per month would she have to take so that the cost of the rides without the bus pass is equal to the total cost of the rides with the bus pass?
The number of rides at which the unlimited ride pass equals the cost of individual ride purchases is ?.
Answers
Answer: 25 Rides
Step-by-step explanation:
Forty (cost of pass per month) divided by 1.60 (Cost of rides) = 25 rides until the cost of the rides equals the price of the pass.
Find the sum of the 25th term of an AP 3,10,17
Answers
The sum of the 25th term of the AP 3, 10, 17 is 171.
The sum of the 25th term of an arithmetic progression (AP) 3, 10, 17 can be found using the formula for the nth term of an arithmetic progression, which is:
aₙ = a₁ + (n - 1) d
where aₙ is the nth term, a₁ is the first term, d is the common difference, and n is the number of terms.
In this case, a₁ = 3, d = 10 - 3 = 7, and n = 25. Plugging in these values into the formula, we get:
a₂₅ = 3 + (25 - 1) 7
a₂₅ = 3 + 168
a₂₅ = 171
Therefore, the sum of the 25th term of the AP 3, 10, 17 is 171.
Learn more about arithmetic progression here: https://brainly.com/question/18828482.
#SPJ11
an urban economist is curious if the distribution in where oregon residents live is different today than it was in 1990. she observes that today there are approximately 3,109 thousand residents in nw oregon, 902 thousand residents in sw oregon, 244 thousand in central oregon, and 102 thousand in eastern oregon. she knows that in 1990 the breakdown was as follows: 72.7% nw oregon, 20.7% sw oregon, 4.8% central oregon, and 2.8% eastern oregon. can she conclude that the distribution in residence is different today at a 0.05 level of significance?
Answers
The distribution in residence is different today at a 0.05 level of significance can be conclude because the p-value = 0.0172
from the data given we can make the table below:
Categories Observed(fo) Expected (fe) (fo-fe)²/fe
NW Oregon 3109 4357*0.727=3167.539 1.082
SW Oregon 902 4357*0.207=901.899 0
Central Oregon 244 4357*0.048=209.136 5.812
Eastern Oregon 102 4357*0.028=121.996 3.277
Sum = 4357 4357 10.171
first, null and alternative hypotheses need to be tested:
H0:p1=0.727,p2=0.207,p3=0.048,p4=0.028
Ha: The population proportion partially deviates from the value given by the null hypothesis
This corresponds to a Chi-Square test for Goodness of Fit.
then, Based on the data provided, the significance level is α=0.05, the number of degrees of freedom is df=4−1=3, so then the rejection region for this test is R={\(X^{2}X^{2}\)>7.815}.
after that we should do test statistic
The Chi-Squared statistic is calculated as follows:
∑\(^{n} _{i=1}\)\(\frac{(Oi-Ei)}{y} \\\) = 1.082+0+5.812+10.171 +3.277= 10.171
the we can make a decision about the null hypothesis by
\(X^{2} = 10.71 > X^{2} _{c} = 7.815\)
it is then concluded that the null hypothesis is rejected.
Therefore, there is enough evidence to claim that some of the population proportions differ from those stated in the null hypothesis, at the α=0.05 significance level.
Learn more about p_value and hypothesis here: https://brainly.com/question/17571541
#SPJ4

Line p has a slope of 4 and line g has a slope of 1. Compare and contrast the two lines based on the given information. How are they different? How are they similar?
Answers
the two lines have different slopes but are both positive, indicating that they are increasing. They have different steepness, with line p being steeper than line g.
Lines are straight sets of points that can be formed with two points. A slope is a measurement that describes the slant of a line. The steepness of a line is calculated using the slope of a line. A slope is calculated by dividing the change in y-coordinates by the change in x-coordinates, expressed as rise/run or Δy/Δx. To compare and contrast lines with slopes of 4 and 1, we will look at their similarities and differences. Similarities: The slope is positive in both lines, indicating that the lines are both increasing as they go from left to right.
They are not perpendicular lines. Differences: Slope of line p is steeper than that of line g because it has a slope of 4, whereas line g has a slope of 1. Therefore, line p changes four times as much vertically for every one change horizontally. On the other hand, line g only changes one time vertically for every one change horizontally. Line g is less steep than line p. The y-intercept of each line is not given in the problem. In summary, the two lines have different slopes but are both positive, indicating that they are increasing. They have different steepness, with line p being steeper than line g.
Learn more about slopes here:
https://brainly.com/question/3605446
#SPJ11
i need helpp asap plss

Answers
Answer:
3^8
Multiply the exponents
The accompanying data fie contatis two predicior variablest-xt and ag, and a numenical targel variable, y. A regression tee will be constructed tring the data. Clich hero forthe forkloata fill a. Ust
Answers
We can construct a regression tree using the given data, we can use the rpart() function in R.
the specific instructions provided by the software or tool is used, as the steps may vary slightly depending on the platform. To construct a regression tree using the given data, follow these steps:
1. Open the data file that contains the predictor variables "XT" and "AG" and the numerical target variable "Y".
2. Check if the data is properly formatted and contains the necessary information for the regression tree.
3. If the data is in the correct format, proceed to build the regression tree.
4. Click on the provided link to access the software or tool that will help you create the regression tree.
5. Once you have access to the software, import the data file into the tool.
6. Specify the predictor variables ("XT" and "AG") and the target variable ("Y") for the regression tree.
7. Configure any additional settings or parameters as needed for your analysis.
8. Run the regression tree algorithm on the data.
9. Review the resulting regression tree, which will display the relationships between the predictor variables and the target variable.
10. Analyze the tree structure and interpret the findings to understand the impact of the predictor variables on the target variable.
Learn more about function from the following link,
https://brainly.com/question/11624077
#SPJ11
If √0.231 = k, then what is the value of √23.1
A. 10k
B. 0.1 k
C. 100k
D. 20k
Answers
Answer:
A
Step-by-step explanation:
using the rule of radicals
\(\sqrt{ab}\) = \(\sqrt{a}\) × \(\sqrt{b}\)
note that 0.231 × 100 = 23.1
given
\(\sqrt{23.1}\)
= \(\sqrt{100(0.231)}\)
= \(\sqrt{100}\) × \(\sqrt{0.231}\)
= 10 × k
= 10k
The value of √23.1 using the value √0.231 = k is 10k.
Thus, option (A) is correct.
Let's first find the value of "k" when √0.231 = k:
√0.231 = k
Now, the value of √23.1 using the value of "k":
√23.1 = √(10 × 2.31)
As √2.31 = k, substitute it in:
√23.1 = √(10 × 2.31)
= √10 × √2.31
= 3.162 × √2.31
Also, √2.31 = 1.52
So, the required value
√23.1 = 3.162 × 1.52
= 4.807
let's check the given options to find the closest value to 4.807:
A. 10k = 10 × √0.231 = 4.807.
B. 0.1k = 0.1 × √0.231 = 0.04806
C. 100k = 100 × √0.231 = 48.06
D. 20k = 20 × √0.231 = 9.6124
Therefore, The value of √23.1 is 10k.
Thus, option (A) is correct.
Learn more about Radical here:
https://brainly.com/question/151386
#SPJ4
outside temperature over a day can be modeled as a sinusoidal function. suppose you know the temperature is 55 degrees at midnight and the high and low temperature during the day are 71 and 39 degrees, respectively. assuming t is the number of hours since midnight, find an equation for the temperature, d, in terms of t.
Answers
The equation for the temperature, d, in terms of t (the number of hours since midnight), is: d = 16 × sin((π/12) × t) + 55
To find an equation for the temperature, we need to determine the amplitude, period, phase shift, and vertical shift of the sinusoidal function.
The amplitude is half the difference between the high and low temperatures, which is (71 - 39) / 2 = 16 degrees. The period is the number of hours in a day, which is 24 hours. Since the temperature is at its highest point at 12:00 PM (midday), there is no phase shift. The vertical shift is the average of the high and low temperatures, which is (71 + 39) / 2 = 55 degrees.
Putting these values together, the equation for the temperature, d, in terms of t can be written as:
d = 16 × sin((2π/24) × t) + 55
Learn more about equation for the temperature here:
https://brainly.com/question/30171443
#SPJ11
Consider the multiple regression model with two regressors X1 and X2, where both variables are determinants of the dependent variable. You first regress Y on X1 only and find no relationship. However when regressing Y on X1 and X2, the slope coefficient changes by a large amount. This suggests that your first regression suffers from a. heteroskedasticity b. perfect multicollinearity c. omitted variable bias d. dummy variable trap 8. Imperfect multicollinearity a. implies that it will be difficult to estimate precisely one or more of the partial effects using the data at hand b. violates one of the four Least Squares assumptions in the multiple regression model c. means that you cannot estimate the effect of at least one of the Xs on Y d. suggests that a standard spreadsheet program does not have enough power to estimate the multiple regression model
Answers
Some part of the regression can be estimated precisely, but it is difficult to predict the effect of individual regressors when there is multicollinearity in the data.Multiple regression models require that variables be independent of one another, otherwise, multicollinearity will occur.
Consider the multiple regression model with two regressors X1 and X2, where both variables are determinants of the dependent variable. You first regress Y on X1 only and find no relationship. However when regressing Y on X1 and X2, the slope coefficient changes by a large amount.
This suggests that your first regression suffers from omitted variable bias. Imperfect multicollinearity implies that it will be difficult to estimate precisely one or more of the partial effects using the data at hand. Imperfect multicollinearity means that there is a strong correlation between the regressors, but they are not perfectly correlated.
As a result, some part of the regression can be estimated precisely, but it is difficult to predict the effect of individual regressors when there is multicollinearity in the data.Multiple regression models require that variables be independent of one another, otherwise, multicollinearity will occur.
When there is multicollinearity in the data, it means that two or more of the variables are highly correlated with one another. In other words, the data may contain redundant information, which can make it difficult to estimate the regression coefficients or partial effects.The dummy variable trap refers to a situation in which one of the variables is a perfect linear combination of the other variables.
This results in the model being unsolvable, and the coefficients cannot be estimated. Heteroskedasticity is the term used to describe when the variance of the residuals is not constant across all values of the independent variables. This means that the predictions of the model may be biased, and the standard errors of the coefficients may be incorrect.
For more such questions on multicollinearity, click on:
https://brainly.com/question/15856348
#SPJ8
Please help me and I will give u brainlst.

Answers
Answer:
(7, 4)
Step-by-step explanation:
We find the distance from each given point to (2, -2).
The one that is √61 is the answer.
a.
(7, 4)
d = √(5² + 6²) = √61
Question 330 in python Given the temperature t (in Fahrenheit) and the wind speed v (in miles per hour), the National Weather Service defines the effective temperature to be: w=35.74+0.6215t+(0.4275t−35.75)
∗
v
∧
0.16 Compose a program that takes two floats t and v from the command-line and prints the wind chill value w
Answers
The wind chill is a measure of how cold it feels when the wind is blowing.
Wind chill takes into account the combined effect of temperature and wind speed on the human body.
As wind speed increases, it carries heat away from the body more rapidly, making it feel colder than the actual temperature.
The formula provided by the National Weather Service to calculate the wind chill is:
w = 35.74 + 0.6215t + (0.4275t - 35.75) * v^0.16
where:
- w is the wind chill value
- t is the temperature in Fahrenheit
- v is the wind speed in miles per hour
Now, let's write a Python program that takes the temperature and wind speed as inputs and calculates the wind chill value:
```python
import sys
# Get temperature and wind speed from command-line arguments
t = float(sys.argv[1])
v = float(sys.argv[2])
# Calculate wind chill using the formula
w = 35.74 + 0.6215 * t + (0.4275 * t - 35.75) * v**0.16
# Print the wind chill value
print("Wind Chill:", w)
```
Example output:
```shell
$ python wind_chill.py 32 10
Wind Chill: 23.72794265120923
```
In this example, the temperature is 32 degrees Fahrenheit and the wind speed is 10 miles per hour.
The program calculates the wind chill value to be approximately 23.73.
To know more about Python program refer here:
https://brainly.com/question/13245592#
#SPJ11
find the sum -10 +20
Answers
Answer:
10
Step-by-step explanation:
.....................
Answer: 10
Step-by-step explanation:

What is the quotient of 3.243 x 10^8 and 7.05 x 10^2
Answers
Answer:
4,600,000,000
Step-by-step explanation:
Don't forget the order of operations
3.243 × 10⁸/7.05
= 46,000,000 × 10²
= 4,600,000,000
or 4.6 × 10⁹
Answer:
4.6x10 to the power of 5
Step-by-step explanation:
7.05×10
2
3.243×10
8
Divide them.
\frac{3.243}{7.05}\times \frac{10^8}{10^2}
7.05
3.243
×
10
2
10
8
Divide numbers and 10's separeately.
0.46\times 10^6
0.46×10
6
Subtract exponents.
(4.6\times 10^{-1})\times 10^6
(4.6×10
−1
)×10
6
Rewrite as a number bigger than 1
4.6\times (10^{-1}\times 10^6)
4.6×(10 −1 ×10 6 )
Associate
4.6\times 10^5
4.6×10 5
Add exponents
A farmer uses 920 grams of grain to feed his 8 chickens. At this rate how many grams of grains does he use to feed 100 chickens
Answers
Answer: 11,500 grams
Step-by-step explanation: 920/8=115 115*100= 11,500
What is the equation of the line that passes through the point (-5,-3)and has a slope of -3/5 ?
Answers
Answer: y = -3/5x - 6
Step-by-step explanation:
There are a few equations that can be used for this, but the simplest one would be y = mx + b
We are given:
y = -3
m = -3/5 (slope)
x = -5
b = ?
Our equation is this, we are solving for b
==> -3 = -3/5 ( -5) + b
==> -3 = -3/5 ( -5) + b ( multiply the brackets)
==> -3 = 3 + b ( subtract 3 to both sides)
==> -6 = b
Now we can make the desired equation in slope intercept form;
y = -3/5x - 6
Hope this helped! Have a great day :D
Please help me out . Find x please

Answers
Step-by-step explanation:
180-46 = 134
180 - 13 = 177
177-134 = 43
? = 43
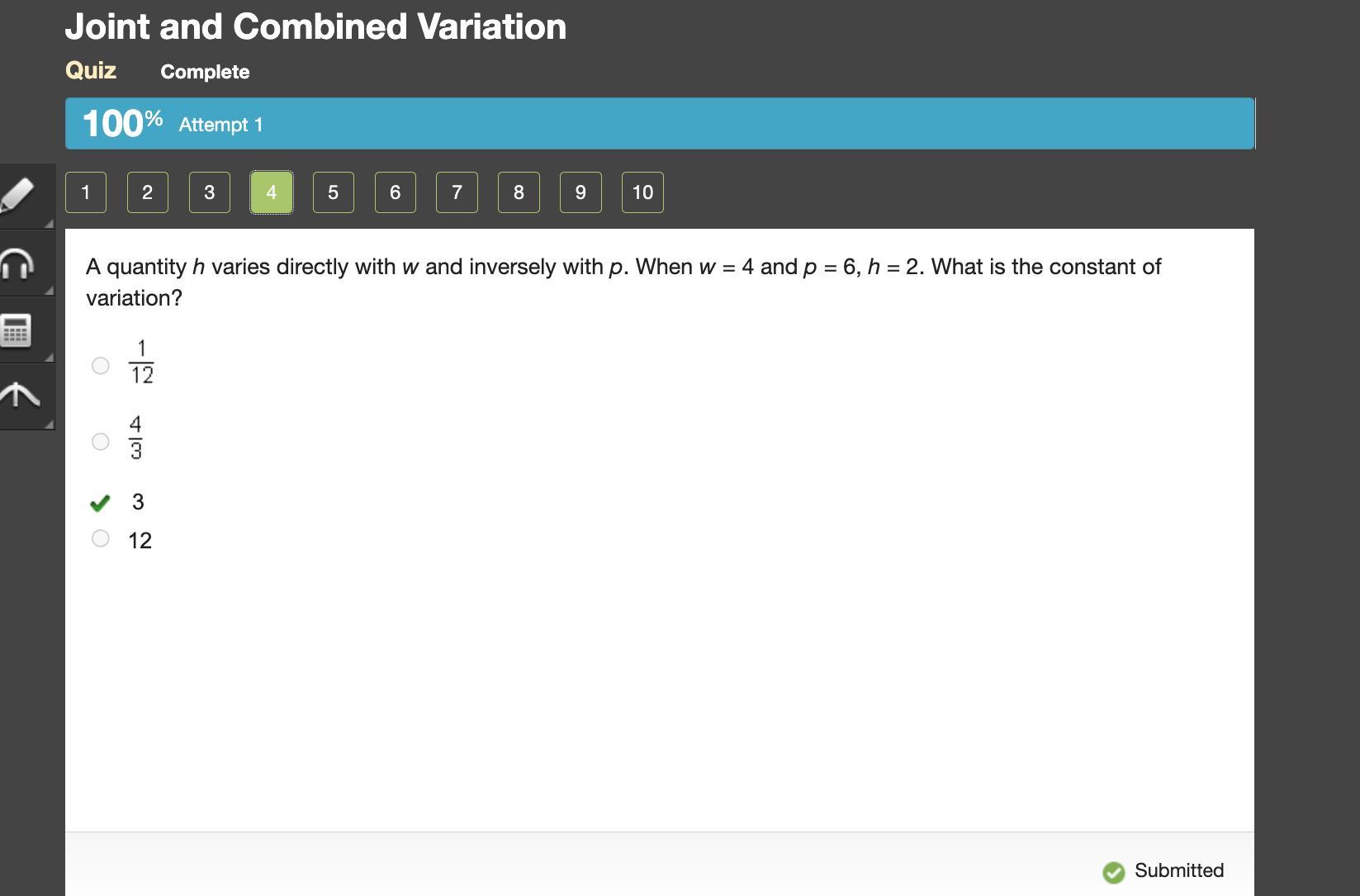
A quantity h varies directly with w and inversely with p. when w = 4 and p = 6, h = 2. what is the constant of variation? one-twelfth four-thirds 3 12
Answers
The value of the constant of variation is 3. The correct option is the third option- 3
VariationFrom the question, we are to determine the constant of variation.
Let the constant of variation be k
From the give information,
A quantity h varies directly with w and inversely with p
That is,
\(h \propto \frac{w}{p}\)
Introducing the constant of variation, k, we get
\(h = k\frac{w}{p}\)
Also, from the give information,
w = 4
p = 6
h = 2
Putting the parameters into the relation, we get
\(2 = k \times \frac{4}{6}\)
\(6\times 2 = 4k\)
\(k = \frac{6\times 2}{4}\)
k = 3
Hence, the value of the constant of variation is 3. The correct option is the third option- 3
Lear more on Constant of variation here: https://brainly.com/question/1831771
#SPJ4
Answer:
Answer is 3
Step-by-step explanation:
~Hope this helps!
A circle has a diameter of 12 inches. what is the best approximation of its area? use 3.14 to approximate for π.
Answers
The best approximation of the area of the circle is 113.04 square inches.
A circle is a shape with all points equidistant from a central point, known as the center. The distance from the center to any point on the edge of the circle is called the radius.
It can be calculated using the formula π \(r^2\), where r is the radius.
Since the diameter of the circle is 12 inches, the radius would be half of that which is 6 inches.
So, the area would be approximately 3.14 * \(6^2\) = 113.04 square inches.
Therefore, The best approximation of the area of the circle is 113.04 square inches.
To learn more about the area of the circle:
https://brainly.com/question/14068861
#SPJ4
The side of a cube measures 2x+1 units long. Express the volume of the cube as a polynomial.
Answers
The volume of the cube as a polynomial is 8x³ + 12x² + 6x + 1.
What is the volume of the cube as a polynomial?The volume of a cube is expressed as;
V = a³
Where a is the side of the cube.
Given that;
Side of the cube a = 2x + 1Volume V = ?Plug the given value into the above equation and simplify.
V = a³
V = ( 2x + 1 )³
Expand using FOIL method
V = ( 2x + 1 )( 2x + 1 )( 2x + 1 )
V = ( 2x( 2x + 1 ) + 1( 2x + 1 ) )( 2x + 1 )
V = (4x² + 4x + 1 )( 2x + 1 )
V = 2x(4x² + 4x + 1 ) + 1(4x² + 4x + 1 )
V = 8x³ + 8x² + 2x + 4x² + 4x + 1
Collect and add like terms
V = 8x³ + 12x² + 2x + 4x + 1
V = 8x³ + 12x² + 6x + 1
Therefore, the volume is 8x³ + 12x² + 6x + 1.
Learn more about polynomials here: https://brainly.com/question/20121808
#SPJ1