If the sinø=7/12, what is cosø?
Answers
Answer:
If the sinø=7/12, cosø is \(\frac{\sqrt{95} }{12}\)
Step-by-step explanation:
We are given sinФ = 7/12
We need to find cosФ
The basic trigonometric functions of right triangle are:
\(sin\theta=\frac{opposite}{hypotenuse}\)
\(cos\theta=\frac{adjacent}{hypotenuse}\)
We need values of adjacent and hypotenuse to find cosФ
Using Pythagoras theorem we can find the value of adjacent
\((Hypotenuse)^2= (Opposite)^2+(Adjacent)^2\)
We have Hypotenuse= 12 and Opposite = 7 (because \(sin\theta=\frac{opposite}{hypotenuse}\) and we are given \(sin\theta=\frac{7}{12}\)
Inserting values and finding adjacent:
\((Hypotenuse)^2= (Opposite)^2+(Adjacent)^2\\(12)^2=(7)^2+(Adjacent)^2\\144=49+(Adjacent)^2\\144-49=(Adjacent)^2\\95=(Adjacent)^2\\\sqrt{(Adjacent)^2} =\sqrt{95}\\Adjacent=\sqrt{95}\)
So, value of Adjacent is \(\sqrt{95}\)
Now finding cosФ
\(cos\theta=\frac{adjacent}{hypotenuse}\)
Adjacent = \(\sqrt{95}\), hypotenuse = 12
\(cos\theta=\frac{\sqrt{95} }{12}\)
So, If the sinø=7/12, cosø is \(\frac{\sqrt{95} }{12}\)
Related Questions
Laura is building a fence around her garden. For every feet of fencing, the cost is $18.
Complete the table below showing the length of the fence and the cost.
PLEASE HELP THIS IS DUE IN A COUPLE MIN!! THANKS

Answers
Answer:
8 18 16 27
Step-by-step explanation:
answer and explain the hint is no spaces

Answers
The answer and explanation to the hint is given below.
What is a word problem?A word problem is a topic in mathematics which requires expressing a given statement or situation with a mathematical equation. The mathematical equation derived would be solved further so as to determine the unknown value of a variable.
In the given question, let the age of Marcus' little brother be represented by x. Thus since Marcus is 10 years older than his little brother, then we have to add 10 to his little brother's current age.
Thus,
Marcus age = his little brother's age+10
= x+10
So that, Marcus's age is expressed as; x+10.
Learn more about word problem at https://brainly.com/question/13143857
#SPJ1
(This exercise is from Physical Geology by Steven Earle and is used under a CC BY 4.0 license.) Heavy runoff can lead to flooding in streams and low-lying areas. The graph below shows the highest discharge per year between 1915 and 2014 on the Bow River at Calgary, Canada. Using this data set, we can calculate the recurrence interval (R) for any particular flood magnitude with the equation R=(n+1)/r, where n is the number of floods in the record being considered, and r is the rank of the particular flood. There are a few years missing in this record, and the actual number of data points is 95. The largest flood recorded on the Bow River over that period was in 2013, which attained a discharge of 1,840 m3/s on June 21. R; for that flood is (95+1)/1=96 years. The probability of such a flood in any future year is 1/R; which is 1%. The fifth largest flood was just a few years earlier in 2005 , at 791 m3/5. Ri for that flood is (95+1)/5=19.2 years. The recurrence probability is 5%. - Calculate the recurrence interval for the second largest flood (1.520 m3/s in 1932). Express your answer in units of years. - What is the probability that a flood of 1,520 m3/s will happen next year? - Examine the 100-year trend for floods on the Bow River. If you ignore the major floods (the labeled ones), what is the general trend of peak discharges over that time?
Answers
The recurrence interval for the second largest flood on the Bow River in 1932 is approximately 1.0106 years. The probability of a flood with a discharge of 1,520 m3/s occurring next year is roughly 98.95%. When examining the 100-year trend of peak discharges, excluding major floods, there is likely a general pattern of fluctuations but with overall stability in typical peak discharge values.
Using the provided data on the highest discharge per year on the Bow River at Calgary, Canada, we can calculate the recurrence interval (R) for specific flood magnitudes and determine the probability of such floods occurring in the future. Additionally, we can examine the 100-year trend for floods on the Bow River, excluding major floods, to identify the general trend of peak discharges over time.
1) Calculating the Recurrence Interval for the Second Largest Flood (1,520 m3/s in 1932):
To calculate the recurrence interval (R) for the second largest flood, we need to determine the rank of that flood. Since there are 95 data points in total, the rank of the second largest flood would be 94 (as the largest flood, in 2013, is excluded). Applying the formula R = (n + 1) / r, we have:
R = (95 + 1) / 94 = 1.0106 years
Therefore, the recurrence interval for the second largest flood (1,520 m3/s in 1932) is approximately 1.0106 years.
2) Probability of a Flood of 1,520 m3/s Occurring Next Year:
The probability of a flood of 1,520 m3/s happening next year can be calculated by taking the reciprocal of the recurrence interval for that flood. Using the previously calculated recurrence interval of 1.0106 years, we can determine the probability:
Probability = 1 / R = 1 / 1.0106 = 0.9895 or 98.95%
Thus, the probability of a flood of 1,520 m3/s occurring next year is approximately 98.95%.
3) Examination of the 100-Year Trend for Floods on the Bow River:
To analyze the 100-year trend for floods on the Bow River while excluding major floods, we focus on the peak discharges over time. Without considering the labeled major floods, we can observe the general trend of peak discharges.
Unfortunately, without specific data on the peak discharges for each year, we cannot provide a detailed analysis of the 100-year trend. However, by excluding major floods, it is likely that the general trend of peak discharges over time would show fluctuations and variations but with a relatively stable pattern. This implies that while individual flood events may vary, there might be an underlying consistency in terms of typical peak discharges over the 100-year period.
In summary, the recurrence interval for the second largest flood on the Bow River in 1932 is approximately 1.0106 years. The probability of a flood with a discharge of 1,520 m3/s occurring next year is roughly 98.95%. When examining the 100-year trend of peak discharges, excluding major floods, there is likely a general pattern of fluctuations but with overall stability in typical peak discharge values.
Learn more about probability here
https://brainly.com/question/25839839
#SPJ11
What is the difference between addition and subtraction of polynomials?
Answers
The difference between addition and subtraction of polynomials is that addition involves like terms and subtraction involves taking one polynomial away from another.
A polynomial is characterized as an expression that is composed of variables, exponents, and constants, that are combined utilizing numerical operations such as addition, subtraction, multiplication, and division (No division operation by a variable).In addition to polynomials, the like terms are included whereas, in subtraction, the like terms are subtracted. The addition of polynomials involves combining like terms to form a single expression, while subtraction involves taking one polynomial away from another. In addition, when subtracting polynomials, the sign of each term in the second polynomial needs to be changed (from positive to negative, or from negative to positive).
To know more about polynomials refer to the link brainly.com/question/11536910
#SPJ4
This season, the probability that the Yankees will win a game is 0. 61 and the probability that the Yankees will score 5 or more runs in a game is 0. 48. The probability that the Yankees lose and score fewer than 5 runs is 0. 32. What is the probability that the Yankees would score fewer than 5 runs when they lose the game? Round your answer to the nearest thousandth
Answers
Answer:
0.238
Step-by-step explanation:
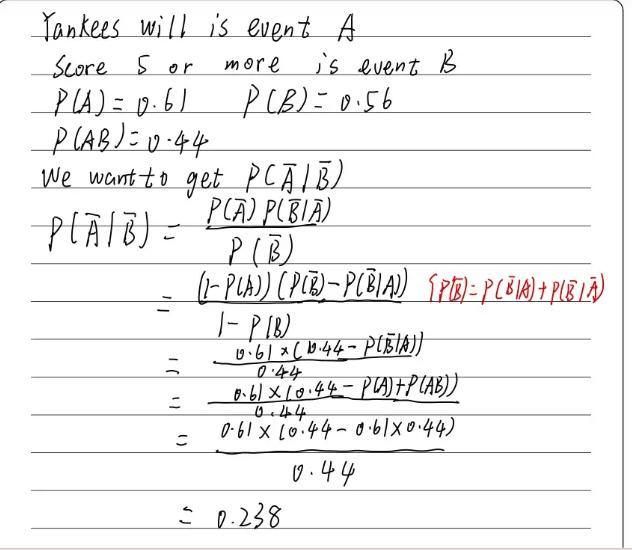
Juanita drove 205.1 miles in 3.5 hours. What was Juanita's average speed in miles per hour?
Answers
Answer:
58.6 miles per hour
Step-by-step explanation:
205.1 miles /3.5 hours= 58.6 mph
What is the image of (10, -12) after a
dilation by a scale factor of centered at the
origin?
Answers
Answer:
-5, -3
Step-by-step explanation:
T/F regardless of whether a distribution of scores that is symmetrically shaped has one mode or two modes, the mean value tends to be similar to the median value.
Answers
True
In a symmetrically shaped distribution of scores, regardless of whether it has one mode or two modes, the mean value tends to be similar to the median value.
When a distribution is symmetric, it means that the data is evenly distributed around the central point, resulting in a bell-shaped curve. In such cases, the mean, median, and mode are typically close to each other.
The mean is the arithmetic average of all the scores in a distribution, while the median represents the middle value when the scores are arranged in ascending or descending order. In a symmetric distribution, the mean and median are located at the exact center of the distribution.
If the distribution has only one mode, it means that there is one prominent peak or high point in the data. In this case, the mean and median will coincide with the mode and will be similar.
If the distribution has two modes, it means that there are two prominent peaks in the data, but they are symmetrical around the center. Even though there are multiple modes, the mean and median will still be similar and tend to be located between the two modes.
In summary, in symmetrically shaped distributions, regardless of the presence of one or two modes, the mean and median values are expected to be close to each other.
Learn more about Distribution
brainly.com/question/29664127
#SPJ11
Q2) If z is directly proportional to x and z = 12 when x = 3, find the value of x when z = 18.
Answers
Answer:
4.5
Step-by-step explanation:
→ Set up the direct proportion equation
z = kx
→ Substitute in the values
12 = 3k
→ Divide both sides by 3 to isolate k
4 = k
→ Substitute the value of k back into the original direct proportion equation
z = 4x
→ Substitute the value of z in
18 = 4x
→ Divide both sides by 4 to isolate x
4.5 = x
Answer:
4.5
Step-by-step explanation:
You have decided both to open a savings account and to purchase a vehicle. You would like a savings account with the highest interest rate and a vehicle loan with a low interest rate. From the banks listed below, determine with which bank you should open a savings account and at which bank should you apply for your vehicle loan.
Bank A for the savings account and Bank A for the car loan
Bank B for the savings account and Bank B for the car loan
Bank C for the savings account and Bank C for the car loan
Bank C for the savings account and Bank A for the car loan
Answers
The bank you should open a savings account with is Bank A and the bank, should you apply for your vehicle loan is Bank B. Thus the correct option is C.
What is Bank?
A bank is referred to as a financial institution that allows an individual to deposit and withdraw cash and allow them to borrow funds with a fixed interest rate for the purpose of investment.
In the given case, it is explained that Both opening a savings account and getting a car are decisions you have made. You want to borrow money for a car at a cheap interest rate and have the greatest interest rate savings account.
In order to avoid any burden you should make decisions with Bank B for the car loan and Bank A for the savings account and enjoy the assets for a lifetime with appropriate benefits.
Therefore, option C is appropriate.
Learn more about the bank, here:
brainly.com/question/14042269
#SPJ1
The index of refraction of the core of a typical fiber optic is ncore = 1.46; the cladding has nclad = 1.4. calculate the critical angles for the total internal reflection icrit and crit .
Answers
Critical angle for the total internal reflection icrit, β = 78.28⁰
Critical angle for the total internal reflection crit, α = 17,22⁰
We have the refractive index of core, \(n_c_o_r_e\) = 1.46
We have the refractive index of clad , \(n_c_l_a_d\) = 1.4
Critical angle can be defined as the incidence angle which results in the refraction angle being equal to at that angle of incidence.
For Total Internal Reflection to occur, the incidence angle must be greater than the critical angle.
We know that the critical angle, θ is given by:
sinθ = \(\frac{n_c_l_a_d}{n_c_o_r_e}\)
sinθ = \(\frac{1.4}{1.46}\)
sinθ = 0.959 = sin⁻¹(0.979) = 78.28⁰
β = θ = 78.28⁰
Now, for α:
\(\frac{sin(90-\alpha )}{sin\alpha } = \frac{1}{n_c_o_r_e}\)
sinα = sin(90⁰-78.28⁰) × 1.46
sinα = sin(11.72⁰) × 1.46
α = sin⁻¹(0.296)
α = 17,22⁰
For more information on this visit:
https://brainly.com/question/13193665
#SPJ4
Critical angle for total internal reflection icrit β = 78.28⁰
Critical angle for total internal reflection crit, α = 17.22⁰
The critical angle can be defined as the angle of incidence at which the angles of refraction are equal to angle of incidence.
The angle of incidence must be greater than the critical angle for total internal reflection to occur.
The refractive index of the core is ncore = 1.46.
The refractive index of clad is nclad = 1.4.
We know that the critical angle, θ is given by:
sinθ = nclad/ ncore
sinθ = 1.4/1.46
sinθ = 0.959
sin⁻¹(0.979) = 78.28⁰
β = θ = 78.28⁰
Now, for α:
sin(90- α) / sin α = 1 / ncore
sinα = sin(90⁰-78.28⁰) × 1.46
sinα = sin(11.72⁰) × 1.46
α = sin⁻¹(0.296)
α = 17.22⁰
Critical angle for icrit β = 78.28⁰
Critical angle for crit α = 17.22⁰
Learn more about Total internal reflection here
https://brainly.com/question/13088998
#SPJ4
In statistical experiments, each time the experiment is repeateda. the same outcome must occurb. the same outcome can not occur againc. a different outcome may occurd. None of the other answers is correct.
Answers
In statistical experiments, each time the experiment is repeated, a different outcome may occur. The correct answer is C.
Statistical experiments involve random processes, such as the random selection of individuals from a population, the random assignment of subjects to groups, or the random measurement of a variable.
The outcome of a statistical experiment is influenced by chance and is inherently uncertain, so it is not possible to guarantee that the same outcome will occur every time the experiment is repeated. Different outcomes may occur, even if the experimental conditions are kept constant, due to the random nature of the processes involved.
Learn more about statistical experiments here: https://brainly.com/question/22044990
#SPJ4
1. Name the quadrant or axis containing the point (-1, 2)
A
V-axis
B
x-axis
с
quadrant II
D
quadrant III
Answers
Answer:
Can u put a pic 9f the question
If you are putting a quadratic function in the form of \(ax^2 + bx + c\) into quadratic formula (\(x = \frac{-b+/- \sqrt{b^2-4ac} }{2a}\)) and the b value in the function is negative, do you still write it as negative in the quadratic formula?
Answers
If you are putting a quadratic function in the form of \(ax^2 + bx + c\) into the quadratic formula \(x = \frac{-b\pm\sqrt{b^2-4ac}}{2a}\) and the b value in the function is negative, then you still write it as negative in the quadratic formula.
The reason is that the b term in the quadratic formula is being added or subtracted, depending on whether it is positive or negative.The quadratic formula is used to solve quadratic equations that are difficult to solve using factoring or other methods. The formula gives the values of x that are the roots of the quadratic equation.
The quadratic formula \(x = \frac{-b\pm\sqrt{b^2-4ac}}{2a}\) can be used for any quadratic equation in the form of \(ax^2 + bx + c = 0\).
In the formula, a, b, and c are coefficients of the quadratic equation. The value of a cannot be zero, otherwise, the equation would not be quadratic.
The discriminant \(b^2-4ac\) determines the nature of the roots of the quadratic equation. If the discriminant is positive, then there are two real roots, if it is zero, then there is one real root, and if it is negative, then there are two complex roots.
For more such questions on quadratic function, click on:
https://brainly.com/question/1214333
#SPJ8
25 points!!! The question is on the picture
A: 2/5
B: 4/5
C: 5/2
D: 5/4

Answers
Answer:
C
Step-by-step explanation:
the scale factor is the ratio of corresponding sides, image P to original N
scale factor = \(\frac{10}{4}\) = \(\frac{5}{2}\)
-Answer: The scale factor that takes polygon N to polygon P is 2.5.
there are black, blue, and white marbles in a bag. the probability of choosing a black marble is 0.36 . the probability of choosing a black and then a white marble is 0.27 . to the nearest hundredth, what is the probability of the second marble being white if the first marble chosen is black?
Answers
There are black, blue, and white marbles in a bag. The probability of choosing a black marble is 0.75.
Let's assume that there are 100 marbles in the bag. If the probability of choosing a black marble is 0.36, there are 36 black marbles in the bag. Therefore, there are 64 marbles of other colors (white and blue) in the bag.
Using the same method, we can say that the probability of choosing a white marble after drawing a black one is \(\frac{0.27}{0.36}= 0.75\) (rounded to the nearest hundredth). It means that there are 75 white marbles for every 100 black marbles in the bag.
Therefore, the probability of the second marble being white if the first marble chosen is black is
Learn more about Probability here:
brainly.com/question/13604758
#SPJ11
The graph of g(x) is a transformation of the graph of f(x)=2x. Enter the equation for g(x) in the box. g(x) =

Answers
The -3 is not in the exponent
Explanation:
The parent function is \(f(x) = 2^x\). Plugging in x = 0 leads to y = 1. So the point (0,1) is on the f(x) curve. Going from (0,1) to (0,-2) is a vertical shift of 3 units downward. To represent this shift, we tack on a "-3" at the end of the f(x) function.
\(g(x) = f(x) - 3\\\\g(x) = 2^x - 3\)
You could look at other points as well, but I find working with x = 0 is easiest.
As a check, plugging x = 0 into g(x) leads to...
\(g(x) = 2^x - 3\\\\g(0) = 2^0 - 3\\\\g(0) = 1 - 3\\\\g(0) = -2\)
This confirms our answer.
Select the correct answer from each drop-down menu.
Sam’s teacher wrote two Boolean expressions on the whiteboard. Identify the names of the laws of these expressions.
Expression 1: X (Y + Z) = X.Y + X.Z
Expression 2: X(Y.Z) = (X.Y)Z = X.Y.Z
The first expression is known as the
law. The second expression is known as the
law.
Answers
The first expression X (Y + Z) = X.Y + X.Z is distributive property of multiplication and the second expression X(Y.Z) = (X.Y)Z = X.Y.Z is associative property of multiplication.
According to the question,
We have the following two expressions:
X (Y + Z) = X.Y + X.Z
X(Y.Z) = (X.Y)Z = X.Y.Z
Now, the distributive property of multiplication states that the number outside the bracket is multiplied into each number within the bracket and the sign remains the same.
For example, 2(5+7) is 2*5+2*7.
The associative property of multiplication states that the result of the multiplication of numbers is same even when the bracket is changed from one number to another.
Hence, the first expression X (Y + Z) = X.Y + X.Z is distributive property of multiplication and the second expression X(Y.Z) = (X.Y)Z = X.Y.Z is associative property of multiplication.
To know more about distributive property here
https://brainly.com/question/5637942
#SPJ1
According to the Boolean algebra, the first expression X (Y + Z) = X.Y + X.Z uses distributive property of multiplication and
The second expression X(Y.Z) = (X.Y)Z = X.Y.Z uses the associative property of multiplication.
Boolean Algebra:
Basically, Boolean algebra is a branch of mathematics that deals with operations on logical values with binary variables.
And there are three properties in Boolean algebra.
They are, Commutative, associative, and distributive properties.
Given,
Sam’s teacher wrote two Boolean expressions on the whiteboard. Identify the names of the laws of these expressions.
Expression 1: X (Y + Z) = X.Y + X.Z
Expression 2: X(Y.Z) = (X.Y)Z = X.Y.Z
Here we need to find the name of the property used by the teacher on those two expression.
While we looking into the question,
We have the give the two expressions:
They are
=> X (Y + Z) = X.Y + X.Z
=> X(Y.Z) = (X.Y)Z = X.Y.Z
When we take the first expression,
X (Y + Z) = X.Y + X.Z
That states that the distributive property of multiplication is used here and the process of the distribution property is the number outside the bracket is multiplied into each number within the bracket and the sign remains the same.
Similarly, when we take the second expression
X(Y.Z) = (X.Y)Z = X.Y.Z
That uses the associative property of multiplication which is the result of the multiplication of numbers is same even when the bracket is changed from one number to another.
Therefore, the first expression X (Y + Z) = X.Y + X.Z uses the distributive property of multiplication and the second expression X(Y.Z) = (X.Y)Z = X.Y.Z uses the associative property of multiplication.
To know more about Boolean algebra here
https://brainly.com/question/23774072
#SPJ1
f The table above gives selected values for _ differentiable and increasing funclion f and its derivative Let g be the Increasing function given by g(1) (#)f (8)6 ajaym '("3)f f(3) (9)f 9. Which of the following describes correct process for finding (9 7(9) (9-1) (9) 9'(9 "(08) and 9' (3) = f' (3) + 2f' (6) (6),(1-6) ((o)u-61,6 3() and 9'(3) = f' (3) + f' (6) (8) / pue (8),6 = ((6),-6),6 = (6),(1-6) (9) ,f + (8) ,f (g ') (9) 9(g '(9)) = 9'(3) &nd 9'(3) = f' (3) + 2f" (6)
Answers
The correct process for finding 9'(9) involves using the chain rule of differentiation. Thus the closest is probably (9) ,f + (8) ,f (g ') (9) 9(g '(9)) = 9'(3) &nd 9'(3) = f' (3) + 2f" (6).
We know that g(9) = f(8), and therefore we can write 9'(9) = f'(8) * g'(9). To find g'(9), we can use the values given in the table and the definition of an increasing function. Since g is increasing, we know that g(1) = f(3) and g(3) = f(9). Therefore, we can write:
g'(9) = (g(3) - g(1))/(3-1) = (f(9) - f(3))/2
To find f'(8), we can use the value given in the table. We know that f'(6) = 4, and therefore we can use the mean value theorem to find f'(8). Specifically, since f is differentiable and increasing, there exists some c between 6 and 8 such that:
f'(c) = (f(8) - f(6))/(8-6) = (g(1) - g(8))/2
Now we can use the given equation to find 9'(3):
9'(3) = f'(3) + f'(6) = 2f'(6)
And we can use the values we just found to find 9'(9):
9'(9) = f'(8) * g'(9) = (g(1) - g(8))/2 * (f(9) - f(3))/2
Note that none of the answer choices given match this process exactly, but the closest is probably (9) ,f + (8) ,f (g ') (9) 9(g '(9)) = 9'(3) &nd 9'(3) = f' (3) + 2f" (6).
More on chain rule: https://brainly.com/question/30478987
#SPJ11
A cylinder and a cone have the same volume. The cylinder has radius x and height y. The cone has radius 3/2x. Find the height of the cone in terms of y.
Answers
4) What is the measure of the intercepted arc with a central angle of 72®?
Answers
Answer:
EGQ ERKNG BQEG'QERJ
Step-by-step explanation:
(I need these answered fast and with work and explanation)
A)What is the conditional probability of being on the marching band, given that you know
the student plays a team sport? Show your work.
b. What is the probability of being on the marching band, and how is this different from part
(a)? Explain completely.
C.
Are the two events, {on the marching band) and {on a team sport} associated? Use
probabilities to explain why or why not.

Answers
Answer:
most I know I don't know and I don't want to know
Consider the following confidence interval: (4 , 10).
The population standard deviation is LaTeX: \sigma=17.638 Ï = 17.638 .
The sample size is 52.
What are the degrees of freedom used in the calculation of this confidence interval?
10
51
degrees of freedom do not apply to this problem
53
52
Answers
The degrees of freedom used in the calculation of this confidence interval is 51.
Given that,
Confidence interval is (4, 10).
Population standard deviation, σ = 17.638
Sample size, n = 52
Degrees of freedom can be calculated using the formula,
Df = n - 1
Here, n = 52
So, Df = 52 - 1 = 51
Hence the degrees of freedom associated with the given situation is 51.
Learn more about Degrees of Freedom here :
https://brainly.com/question/29307864
#SPJ4
Andrea is conducting an experiment rolling a pair of number cubes, numbered from 1 through 6. She will roll the number cubes 36 times to test the prediction of a 1 out of 6 chance of rolling matching numbers; that is, both cubes show the same number. If her experiment holds true to the prediction, how many of the 36 times would matching numbers appear?

Answers
Answer:
6 times
Step-by-step explanation:
\( \frac{1}{6} \times 36 = 6\)
Which system of equations has no solution?
5x+ 5y = 10 and 2x+2y = 4
3x-Gy=4 and - 4x+8y = 7
6x+2y = 6 and 7x+3y=9
3x-4y= 16 and 2x+3y=5
Answers
Answer:B
Step-by-step explanation:
joe has dime and nickels in his piggy bank totaling $1.45 the number of nickels he has is 5 more than twice the number of dimes , d . which equation could be used to find the number of dimes he has ?
Answers
The expression 0.3d = 0.95 could be used to find the number of dimes he has.
What is a expression? What is a mathematical equation? What is Equation Modelling?A mathematical expression is made up of terms (constants and variables) separated by mathematical operators. A mathematical equation is used to equate two expressions. Equation modelling is the process of writing a mathematical verbal expression in the form of a mathematical expression for correct analysis, observations and results of the given problem.
We have joe who has dime and nickels in his piggy bank totaling $1.45 the number of nickels. He has is 5 more than twice the number of dimes [d].
We can write the the number of nickels as -
[n] = 2d + 5
0.1d + 0.1(2d + 5) = 1.45
0.1d + 0.2d + 0.5 = 1.45
0.3d = 0.95
Therefore, the expression 0.3d = 0.95 could be used to find the number of dimes he has.
To solve more questions on Equations, Equation Modelling and Expressions visit the link below -
brainly.com/question/14441381
#SPJ1
SOLVE FOR X IN THE DIAGRAM BELOW PLS HELP
BRAINLIEST


Answers
Answer:
x=6,25
Step-by-step explanation:
8x=50
8÷8 which we will be only left with x and then 50÷8 will give us 6,25
an example of a linear equation.
Answers
An example is y = ax + b. yay
En una empresa líder en investigación se quiere estimar la proporción de personas a favor de una nueva reforma política en el distrito A. ¿A cuántas personas se necesitará para la estimación, si de una muestra piloto se obtuvo que el 64. 1% de las personas están a favor de la reforma política, se desea estar seguro con un 97% de confianza y tener a lo más 4. 7% de error de estimación?
Answers
A sample of at least 870 people is needed to estimate the proportion of people in favor of the political reform in District A with a 97% confidence level and a maximum estimation error of 4.7%
To estimate the sample size, we can use the following formula:
n = (Z^2 * p * (1-p)) / E^2
where:
n = sample size
Z = the Z-score for a given confidence level (for 97% confidence, Z = 2.33)
p = the proportion in the pilot sample (0.641)
E = the maximum allowed error of estimation (0.047)
Plugging in the values, we get:
n = (2.33^2 * 0.641 * (1 - 0.641)) / 0.047^2
n = (5.3929 * 0.359) / 0.00222009
n = 1.928 / 0.00222009
n = 869.75
Since the sample size must be a whole number, we round up to the nearest whole number.
n = 870
Therefore, a sample of at least 870 people is needed to estimate the proportion of people in favor of the political reform in District A with a 97% confidence level and a maximum estimation error of 4.7%
To learn more about confidence level:
https://brainly.com/question/17090798
#SPJ4
Guessing game where players can choose a number between 0 and 100. The winner is the one who chooses closest to 2/3 of the average of the guesses.
With only 2 players you and an inexperienced player. What number would you choose? Why?
Answers
The specific number within the range of 33 to 40 would depend on my assessment of the situation and my intuition at the time of playing the game
In this guessing game, the goal is to choose a number that is closest to 2/3 of the average of the guesses. To determine the optimal strategy, we need to consider the likely approach of the inexperienced player.
Given that the inexperienced player may not be aware of the optimal strategy, they might choose their number based on a random guess or by focusing on their intuition rather than employing any specific mathematical reasoning.
To maximize my chances of winning, I would consider the average behavior of inexperienced players and make an educated guess. Based on statistical analysis, inexperienced players often tend to choose numbers towards the middle of the given range, such as around 50. To counter this, I would choose a number that is slightly below the midpoint, but still close enough to benefit from the averaging process.
Considering these factors, I would choose a number around 33 to 40. This range is likely to be below the average of the inexperienced player's guess, but still close enough to the 2/3 threshold to increase my chances of winning. By strategically positioning my guess in this manner, I aim to take advantage of the likely choices made by the inexperienced player.
Ultimately, the specific number within the range of 33 to 40 would depend on my assessment of the situation and my intuition at the time of playing the game.
To know more about average:
https://brainly.com/question/24057012
#SPJ11