if a function is not continuous is it differentiable
Answers
If a function is not continuous, it may or may not be differentiable.
The differentiability of a function is not determined solely by its continuity.
What is a continuous function?A continuous function is a function that can be drawn without picking up a pen. In mathematical terms, a function f(x) is continuous if, as x approaches a point a, f(x) approaches f(a).
For a function to be differentiable, it must be continuous. If a function is not continuous, it is not differentiable. However, the opposite is not always true; a function may be continuous but not differentiable.
In summary, a function that is not continuous may or may not be differentiable, while a function that is differentiable must be continuous.
To know more about continuous function: https://brainly.com/question/18102431
#SPJ11
Related Questions
Plot 213, −56, and −312 on the number line.

Answers
Answer:
Step-by-step explanation:

Plot 213, −56, and −312 on the number line.
Which choices are equivalent to the fraction below

Answers
Answer:
E and F
Step-by-step explanation:
(16/20 = 0.80)
14/8 = 1.75
9/10 = 0.90
8/5 =1.60
13/10 = 1.30
4/5 = 0.80
8/10 = 0.80
You have to to put the reduce the fractions and then put them in to decimal form then see if they are the same as the one you want it to be.
for any integers xx, yy and zz, if x∤zx∤z, then x∤yx∤y or x∤(y z)x∤(y z). what would be assumed to be true?
Answers
The assumed truth for this statement is that x, y, and z are integers and x does not divide z.
We have to given that,
For any integers x, y and z,
And, if x ∤ zx ∤ z,
Then, x ∤ yx ∤ y or x ∤ (y z)x ∤(y z).
Hence, Assuming x, y, and z are integers and x does not divide z, the statement is: if x does not divide z, then x does not divide y or x does not divide yz.
Thus, The assumed truth for this statement is that x, y, and z are integers and x does not divide z.
Learn more about the divide visit:
https://brainly.com/question/28119824
#SPJ12
A t-shirt increased in price by 14. After the increase it was priced at £30. What was the original price of the t-shirt?
Answers
So the cost before was 30 - 14 = 16
Answer:
Either £16 or £26.32 depending on what you meant in the question
Step-by-step explanation:
I'm going to answer the question in 2 ways, since I'm not sure if you mean £14 or 14%
If its £14, then the original price is 30-14 = £16
If its 14% then that means after the increase, the shirt will be 100%+14% of the original price or 114% of the original price.
This means that
£30 = 114%
To make it easier, reduce the 114% to 1 %
1% = 30/114
1% = £0.26316
100% = £26.32 (rounded to 2 decimal places)
Therefore the original price was £26.32
Of the 600 people at a music festival, 420 had attended the previous year. How many people
out of 100 had attended the previous year?
Answers
Answer:
70 people
Step-by-step explanation:
divide both answers by 6
Answer:
70
Step-by-step explanation:
i-ready BOIIIII
Given an array of strings words and an integer k, return the k most frequent strings.
Return the answer sorted by the frequency from highest to lowest. Sort the words with the same frequency by their lexicographical order.
Answers
We can use a priority queue to keep track of the k most frequent strings. The priority queue should be sorted by the frequency of the strings, and in case of ties, we should sort by lexicographical order.
Here's the step-by-step algorithm to solve the problem:
1. Create a hash map to count the frequency of each string in the array.
2. Create a priority queue and define a custom comparator function that compares strings based on their frequency and lexicographical order.
3. Iterate over the keys of the hash map and add each string to the priority queue.
4. Pop the top k strings from the priority queue and add them to the result array.
5. Return the result array sorted in descending order of frequency.
Here's the Python code that implements this algorithm:
```
import heapq
from collections import defaultdict
def topKFrequent(words, k):
freq = defaultdict(int)
for word in words:
freq[word] += 1
pq = []
for word, count in freq.items():
heapq.heappush(pq, (-count, word))
res = []
for i in range(k):
res.append(heapq.heappop(pq)[1])
return sorted(res, key=lambda x: (-freq[x], x))
```
In this code, we use a defaultdict from the collections module to count the frequency of each string. We then use a heap (implemented as a list) to keep track of the k most frequent strings. The -count value is used as the first element of each tuple in the heap, so that we can sort the strings by frequency in descending order. The second element of each tuple is the string itself, which is used to break ties in case of equal frequency. Finally, we sort the result array based on the frequency and lexicographical order using the sorted function and a lambda function.
Visit here to learn more about lambda function : https://brainly.com/question/30904350
#SPJ11
Please help. I keep getting these wrong and I am not sure why!
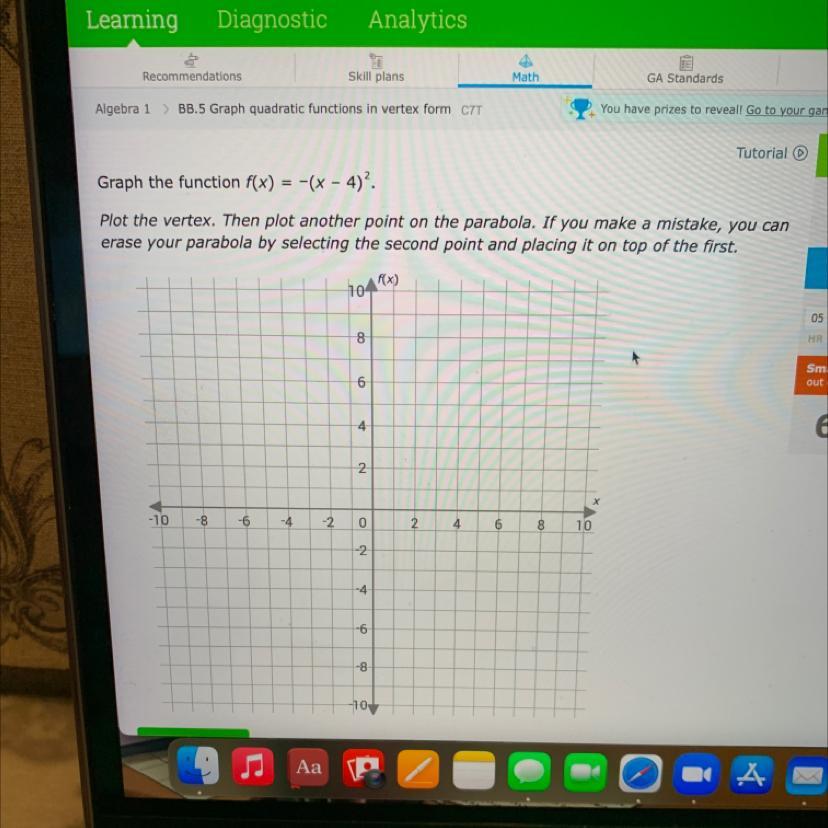
Answers
Solution
\(f\left(x\right)=-\left(x-4\right)^{2}\)The graph
The vertex of a parabola is the point at the intersection of the parabola and its line of
symmetry
Any other point is a point on the graph, you can choose any desired point on the graph


given the first layer of a convolutional neural network with units, and which inputs in grayscale images that have pixel dimensions, what is the size of the weight matrix for this cnn? describe what the rows/columns represent
Answers
To determine the size of the weight matrix for the given convolutional neural network (CNN), we need to consider the number of units in the first layer and the dimensions of the input grayscale images.
In a CNN, the weight matrix is used to perform the convolution operation, which involves applying filters to the input images. Each unit in the first layer corresponds to a specific filter or kernel. The size of the weight matrix will depend on the number of units in the layer and the dimensions of the filters.Let's assume that the number of units in the first layer is N, and the input grayscale images have pixel dimensions MxM. In this case, the weight matrix will have dimensions N x (K x K), where K represents the kernel size. Each row of the weight matrix corresponds to the weights associated with a specific unit in the first layer.The number of columns in the weight matrix is determined by the kernel size, which is typically a square matrix.
The values in the weight matrix represent the learnable parameters of the CNN. By adjusting the weights in the matrix, the CNN can learn to extract meaningful features from the input images and make accurate predictions. Overall, the size of the weight matrix for the given CNN is N x (K x K), where N is the number of units in the first layer, and K is the kernel size. The rows of the weight matrix correspond to the units in the first layer, and the columns represent the weights associated with each pixel in the kernel used for convolution.
To learn more about convolutional neural network (CNN) click here:
brainly.com/question/31285778
#SPJ11
According to the product structure tree for Bell laptops on p. 4
of the lecture materials on Master Scheduling and Bill of
Materials, how many hard drives (01-hdrive) are required to produce
250 Bell
Answers
If 250 Bell laptops are to be produced, then 250 hard drives will be required.
According to the product structure tree for Bell laptops on page 4 of the lecture materials on Master Scheduling and Bill of Materials, the total number of hard drives (01-hdrive) required to produce 250 Bell laptops is 250.Each Bell laptop requires one hard drive to be produced.
Therefore, if 250 Bell laptops are to be produced, then 250 hard drives will be required.
This can be seen in the product structure tree where the hard drive is a sub-assembly of the Bell laptop, and each Bell laptop requires exactly one hard drive. The product structure tree also shows that each hard drive requires a number of components to be produced, such as a hard drive case, a circuit board, and a motor.
These components are also shown as sub-assemblies of the hard drive.
Overall, the product structure tree is a useful tool for understanding the relationships between the components and sub-assemblies that are required to produce a finished product. It provides a detailed breakdown of the product structure, which is essential for effective production planning and scheduling.
Know more about hard drive here,
https://brainly.com/question/10677358
#SPJ11
what’s the slope lol

Answers
Step-by-step explanation:
From the figure , assume that OAB is a right angle triangle and angle OAB is alpha
\(Slope = \tan( \alpha ) \)
\( = \frac{opposite \: side}{adjacent \: side} \)
\( = \frac{ - 3}{ - 1} \)
\( = 3\)

Maria is making a rectangular quilt. She starts with a square of fabric with side length x cm.
She adds some fabric to one side of the square and a different amount of fabric to an adiacent side of the square. Her final quilt has an area of x2 + 13x + 30 cm?. How much longer is the long dimension of the quilt than the short dimension?
Answers
Therefore, the long dimension of the quilt is (26x + 60)/(x + 6) cm longer than the short dimension.
What is area?Area is the measure of the extent of a 2-dimensional surface or region, usually measured in square units such as square meters (m²), square feet (ft²), or square centimeters (cm²). It is the amount of space inside the boundary of a flat shape or the surface of an object.
Here,
The area of the original square is x^2 cm². Maria adds some fabric to one side of the square, which increases the length of the rectangle by a certain amount, and adds a different amount of fabric to the adjacent side, which increases the width of the rectangle by a certain amount. Let's say Maria adds y cm of fabric to one side and z cm of fabric to the other side. Then the length of the rectangle is x + y cm and the width is x + z cm. The area of the rectangle is given by:
(x + y)(x + z) = x^2 + xy + xz + yz
We know that the area of the rectangle is x² + 13x + 30 cm². So we can set these two expressions equal to each other:
x² + xy + xz + yz = x² + 13x + 30
Simplifying this equation, we get:
xy + xz + yz = 13x + 30
We want to find the difference between the length and the width of the rectangle, which is (x + y) - (x + z) = y - z. To solve for y - z, we need to express yz in terms of y - z. We can do this by factoring the left side of the equation above:
xy + xz + yz = y(x + z) + xz = (y - z)(x + y + z)
Substituting this expression for yz in the equation above, we get:
(y - z)(x + y + z) = 13x + 30
We want to solve for y - z, so let's focus on the left side of the equation:
(y - z)(x + y + z) = y(x + y + z) - z(x + y + z)
= xy + y² + yz - xz - z² - yz
= y² - z² + xy - xz
Substituting the expression we found earlier for xy - xz, we get:
(y - z)(x + y + z) = y² - z² + (y - z)(x + z)
(y - z)[x + y + z - (x + z)] = y² - z²
y - z = (y² - z²)/(y - z) = y + z
= (13x + 30)/(x + 6)
So the difference between the length and the width of the rectangle is:
y - z = (13x + 30)/(x + 6)
Therefore, the long dimension of the quilt is (x + y) = x + (13x + 30)/(x + 6) cm, and the short dimension is (x + z) = x + (30 - 13x)/(x + 6) cm. The difference between the long and short dimensions is:
[x + (13x + 30)/(x + 6)] - [x + (30 - 13x)/(x + 6)]
= (13x + 30)/(x + 6) - (30 - 13x)/(x + 6)
= (26x + 60)/(x + 6)
To know more about area,
https://brainly.com/question/28016184
#SPJ1
i have no idea what i’m doing

Answers
Answer:
f(x)=x^2+1 -> f(a+1)=(a+1)^2+1=a^2+2a+1+1=a^2+2a+2
Step-by-step explanation:
How does Naomi's solution compare with Peter's solution? Complete the statement.
Answers
Answer: first one is subtract by 7 and the second step is to divide by 10.
Step-by-step explanation:
hope it helped
Answer:
WHat he said ;D
GL <3
(it was correct if u wanna kno!)
GL AGAIN XD :D
In a hostel, 50 students have food enough for 54 days. How many students should be added in the hostel so that the food is enough for only 45 days ?
Answers
We need to add 10 students to the hostel so that the food is enough for only 45 days.
How many students should be added in the hostel so that the food is enough for only 45 days? Let's assume that "x" students need to be added to the hostel so that the food is enough for only 45 days.
We know that the total amount of food available is fixed, so the product of the number of students and the number of days that the food will last must also be fixed.
We can use this fact to set up an equation:
50 × 54 = (50 + x) × 45
To solve for x, we can simplify and solve for x:
Expand using FOIL method
50 × 54 = (50 + x)45
50 × 54 = 45 × 50 + 45 × x
2700 = 2250 + 45x
450 = 45x
x = 10
Therefore, number of students to be added is 10.
Learn to used PEMDAS and FOIL in solving equations here: https://brainly.com/question/36185
#SPJ1
Chrissy ate 10% of the Christmas cookies. If she ate 6 cookies, how many Christmas cookies were left?
Answers
Answer:
If Chrissy eats 6 cookies so 54 cokies are left. .
Step-by-step explanation:
Cashews cost $6.75/lb. and Jeanna can spend at most $30 for them. How many pounds can
she buy?
Answers
Answer:
4.44 lb
Step-by-step explanation:
$6.75 ---> 1 lb
$1 ---> (1/6.75) lb
$30 ---> [$30* (1/6.75)] lb
$30 ---> 4.44
So she can buy most 4.44 lb of pounds
Answer:
4.44 lb
Step-by-step explanation:
$6.75 ---> 1 lb
$1 ---> (1/6.75) lb
$30 ---> [$30* (1/6.75)] lb
$30 ---> 4.44
So she can buy most 4.44 lb of pounds
Step-by-step explanation:
pls branliest to me he/she have 210 me onley 4
Suppose that f(x,y)={ 15x 2
y
0
;
;
0
otherwise
a) Compute E(X∣y),Var(X) and Var(Y). b) Hence, deduce the value of rho=Corr(X,Y).
Answers
That further simplification may be possible depending on the specific values of x and y.
To compute E(X|y), Var(X), Var(Y), and Corr(X,Y), we need to calculate the marginal distributions and conditional expectations.
Given the joint probability distribution:
f(x,y) =
15x^2 * y, if x > 0 and y > 0
0, otherwise
Let's calculate the marginal distribution of X and Y first:
Marginal distribution of X:
\(fX(x) = ∫f(x,y)dy = ∫(15x^2 * y)dy (from y = 0 to infinity) = 15x^2 * ∫y dy = 15x^2 * [y^2/2] (evaluating the integral) = 7.5x^2 * y^2\)
Marginal distribution of Y:
\(fY(y) = ∫f(x,y)dx = ∫(15x^2 * y)dx (from x = 0 to infinity) = 15y * ∫x^2 dx = 15y * [x^3/3] (evaluating the integral) = 5y * x^3\\\)
Now, let's calculate the conditional expectation E(X|y):
\(E(X|y) = ∫x * f(x|y) dx = ∫x * (f(x,y)/fY(y)) dx (using Bayes' rule) = ∫x * ((15x^2 * y) / (5y * x^3)) dx = 3/y * ∫dx = 3/y * x (integrating with respect to x) = 3/y * x^2/2 (evaluating the integral) = 1.5/y * x^2\)
\(To compute Var(X), we need to calculate E(X^2) first:E(X^2) = ∫x^2 * fX(x) dx = ∫x^2 * (7.5x^2 * y^2) dx = 7.5y^2 * ∫x^4 dx = 7.5y^2 * [x^5/5] (evaluating the integral) = 1.5y^2 * x^5\\\)
Now, we can calculate Var(X):
\(Var(X) = E(X^2) - (E(X))^2 = 1.5y^2 * x^5 - (1.5/y * x^2)^2 = 1.5y^2 * x^5 - 2.25/y^2 * x^4To compute Var(Y), we need to calculate E(Y^2) first:E(Y^2) = ∫y^2 * fY(y) dy = ∫y^2 * (5y * x^3) dy = 5x^3 * ∫y^3 dy = 5x^3 * [y^4/4] (evaluating the integral) = 1.25x^3 * y^4\)
Now, we can calculate Var(Y):
\(Var(Y) = E(Y^2) - (E(Y))^2 = 1.25x^3 * y^4 - (5x^3 * y)^2 = 1.25x^3 * y^4 - 25x^6 * y^2\\\)
Finally, let's deduce the value of rho = Cor
r(X,Y):
\(Corr(X,Y) = Cov(X,Y) / sqrt(Var(X) * Var(Y))Cov(X,Y) = E(X * Y) - E(X) * E(Y)E(X * Y) = ∫∫x * y * f(x,y) dx dy = ∫∫x * y * (15x^2 * y) dx dy = 15 * ∫∫x^3 * y^2 dx dy = 15 * ∫(1.5/y * x^2) * y^2 dx dy (using E(X|y) = 1.5/y * x^2) = 22.5 * ∫x^2 dx dy = 22.5 * [x^3/3] (evaluating the integral) = 7.5x^3\)
\(E(X) = ∫x * fX(x) dx = ∫x * (7.5x^2 * y^2) dx = 7.5y^2 * ∫x^3 dx = 7.5y^2 * [x^4/4] (evaluating the integral) = 1.875y^2 * x^4E(Y) = ∫y * fY(y) dy = ∫y * (5x^3 * y) dy = 5x^3 * ∫y^2 dy = 5x^3 * [y^3/3] (evaluating the integral) = 1.667x^3 * y^3Cov(X,Y) = E(X * Y) - E(X) * E(Y) = 7.5x^3 - (1.875y^2 * x^4) * (1.667x^3 * y^3) = 7.5x^3 - 3.125x^7 * y^5\)
Now, we can calculate rho:
\(rho = Corr(X,Y) = Cov(X,Y) / sqrt(Var(X) * Var(Y)) = (7.5x^3 - 3.125x^7 * y^5) / sqrt((1.5y^2 * x^5 - 2.25/y^2 * x^4) * (1.25x^3 * y^4 - 25x^6 * y^2))\\\)
Please note that further simplification may be possible depending on the specific values of x and y.
To know more about value click-
http://brainly.com/question/843074
#SPJ11
About 30% of people age 50 to 60 suffer from mild depression. A researcher is interested in determining if a vitamin d supplement will increase or decrease the proportion of people that have mild depression. The researcher randomly selects 500 people between the ages of 50 and 60 and ask them to take a vitamin d supplement for 6 months. At the end of the six months, the participants are asked to complete a survey. A psychologist then classifies each participant as either depressed or not. The psychologist classifies 158 people as depressed. Is the proportion of people that are classified as depressed different from 0. 30? what is the null and alternative hypothesis?.
Answers
Using percentages we can conclude that yes, the proportion of people that are classified as depressed is different from 30% which is 31.6%.
What are percentages?A percentage is a figure or ratio stated as a fraction of 100 in mathematics. Although the abbreviations "pct.", "pct.", and occasionally "pc" is also used, the percent symbol, "%," is frequently used to indicate it. By dividing the value by the entire value and multiplying the result by 100, one may determine the percentage. The percentage calculation formula is (value/total value)100%.So, the proportion of people different from 30%:
The number of people selected for the survey is 500.The number of people who resulted was depressed 158.Now, calculate as follows:
158/500 × 1000.316 × 10031.6
Therefore, using percentages we can conclude that yes, the proportion of people that are classified as depressed is different from 30% which is 31.6%.
Know more about percentages here:
https://brainly.com/question/9553743
#SPJ4
The correct question is given below:
About 30% of people aged 50 to 60 suffer from mild depression. A researcher is interested in determining if a vitamin d supplement will increase or decrease the proportion of people that have mild depression. The researcher randomly selects 500 people between the ages of 50 and 60 and asks them to take a vitamin d supplement for 6 months. At the end of the six months, the participants are asked to complete a survey. A psychologist then classifies each participant as either depressed or not. The psychologist classifies 158 people as depressed. Is the proportion of people that are classified as depressed different from 0. 30?
problem solving and/or application: explain why 8x + 3y cannot be factorised
Answers
Answer:
It is already at its simplest form and nothing further can be done.
Step-by-step explanation:
Is -9x²-30x-25 a perfect square trinomial? And if not, is it because of the negative? Please help, giving brainlyest :)
Answers
Answer:
no; because of the factor of -1.
Step-by-step explanation:
-9x² -30x -25 = -(3x +5)²
The trinomial is a square with an extra factor (-1), so cannot be called a "perfect square trinomial."
Answer:
no
placement of negative signs
Step-by-step explanation:
It is not a perfect square trinomial because of the negative signs in the wrong places.
With the negative signs like this, we do have a perfect square binomial.
9x²-30x+25 = (3x-5)²
9x²+30x+25 = (3x+5)²
The given trinomial has the negative signs in the wrong place to be a perfect square trinomial.
Find the slope of the tangent line to the given polar curve at the point specified by the value of \( \theta \). \[ r=\cos (\theta / 3), \quad \theta=\pi \]
Answers
The derivative of \(r\) with respect to \(\theta\) can be found using the chain rule. Let's proceed with the differentiation:
\frac{dr}{d\theta} = \frac{d}{d\theta}\left(\cos\left(\frac{\theta}{3}\right)\right)
To differentiate \(\cos\left(\frac{\theta}{3}\right)\), we treat \(\frac{\theta}{3}\) as the inner function and differentiate it using the chain rule. The derivative of \(\cos(u)\) with respect to \(u\) is \(-\sin(u)\), and the derivative of \(\frac{\theta}{3}\) with respect to \(\theta\) is \(\frac{1}{3}\). Applying the chain rule, we have:
\frac{dr}{d\theta} = -\sin\left(\frac{\theta}{3}\right) \cdot \frac{1}{3}
Now, let's evaluate this derivative at \(\theta = \pi\):
\frac{dr}{d\theta} \bigg|_{\theta=\pi} = -\sin\left(\frac{\pi}{3}\right) \cdot \frac{1}{3}
The value of \(\sin\left(\frac{\pi}{3}\right)\) is \(\frac{\sqrt{3}}{2}\), so substituting this value, we have:
\frac{dr}{d\theta} \bigg|_{\theta=\pi} = -\frac{\sqrt{3}}{2} \cdot \frac{1}{3} = -\frac{\sqrt{3}}{6}
Therefore, the slope of the tangent line to the polar curve \(r = \cos(\theta / 3)\) at the point specified by \(\theta = \pi\) is \(-\frac{\sqrt{3}}{6}.
Learn more about Tangent Line here :
https://brainly.com/question/31179315
#SPJ11
QUESTION 16 Draw the network representation of the following network flow problem. What is the value of the objective funct MIN: \( \quad 5 X_{12}+3 X_{13}+2 X_{14}+3 X_{24}+2 X_{34} \) Subject to: \[
Answers
The network representation of the given network flow problem is a directed graph with nodes representing sources, sinks, and intermediate points, and edges representing flow paths. The objective function value cannot be determined without the rest of the constraints.
To draw the network representation of the given problem, we need additional information about the constraints, such as the capacities of the edges, the supply and demand of nodes, and any other constraints related to flow.
The network representation consists of nodes and edges. Nodes represent the sources, sinks, and intermediate points in the problem, while edges represent the flow paths between nodes.
Each edge is assigned a variable (e.g., X12, X13, etc.) that represents the flow or quantity of flow on that edge. The objective function, in this case, is to minimize the sum of the products of the flow variables and their respective coefficients.
However, without information about the capacities, supply and demand, and other constraints, it is not possible to determine the value of the objective function.
In conclusion, the network representation of the problem can be drawn, but the value of the objective function cannot be determined without the additional constraints and information.
Learn more about constraints here:
https://brainly.com/question/32387329
#SPJ11
Irma opened a servings account and deposited $1,000.00 as principal. the account earns 3% interest, compounded annually. what is the balance after 4 years?

Answers
Step 1: Problem
Compound interest
Step 2: Concept
\(\begin{gathered} A=P(1+r)^t \\ A\text{ = amount or balance or future value} \\ P\text{ = principal} \\ r\text{ = rate} \\ t\text{ = time} \end{gathered}\)Step 3: Method
A = ?
r = 3% = 3/100 = 0.03
t = 4 years
P = $ 1,000
\(\begin{gathered} A=P(1+r)^t \\ A=1000(1+0.03)^4 \\ A\text{ = 1000 }\times1.03^4 \\ A\text{ = 1000 X 1.1255} \\ A\text{ = \$1125.5} \end{gathered}\)Hellohello, if you able to help me then please do. (:

Answers
Answer:
Step-by-step explanation:
it will always be true as long as it is adittion the r is the unknown number just add 15 plus what equals 25
Task 3
please pa answer na po ngayun (个_个)
Directions: Find the quotient.
1) 75.36 ÷ 0.24 =
2) 1.536 ÷ 0.3 =
3) 6.705 ÷ 0.45 = =
4) 1.875 ÷ 0.05 =
5) 6.048 ÷ 0.8 =
Task 4
Directions: Find the quotient.
1) 1.6 5.136 2) 2.8 7.364
4) 4.8 83.52
3) 3.6 65.52
5) 5.6 3.136
Answers
Answer:
eue8whiwhwihdhd123456789101122334
Let X, Y, and Z be points on a circle. Let line XY and the tangent to the circle at Z intersect at W. If WX = 4, WZ = 8, and WY is perpendicular to WZ, then find YZ.
Please no random answers...

Answers
Check the picture below.

The length of YZ is 8√5.
What is a circle?A circle is a two-dimensional figure with a radius and circumference of 2πr.
The area of a circle is given as πr².
We have,
Line XY and the tangent to the circle at Z intersect at W.
WX = 4, WZ = 8, and WY is perpendicular to WZ.
Now,
From the tangent and secant segment length theorem, we get,
WZ² = WY x WX
8² = WY x 4
WY = 64/4
WY = 16
Now,
From the Pythagorean theorem, we get,
YZ² = WY² + WZ²
YZ² = 16² + 8²
YZ² = 256 + 64
YZ² = 320
YZ = √(320)
YZ = √(64 x 5)
Yz = 8√5
Thus,
YZ is 8√5.
Learn more about circle here:
https://brainly.com/question/11833983
#SPJ2
Let A=(−3,3,−1),B=(0,7,0),C=(3,4,0), and D=(0,0,−1). Find the area of the paralleiogram determined by theso four poivis, the acea of the tilangle ABC, and the area of the triangle ABD
Area of paralleiogram ABCD :
Area of triangle ABC
Area of trangle ABD=
Answers
Area of parallelogram ABCD: 22.85 (approximately)
Area of triangle ABC: 1.802 (approximately)
Area of triangle ABD: 11.42 (approximately)
To find the area of the parallelogram determined by the points A, B, C, and D, we can use the cross product of two vectors formed by the points.
Let's consider vectors AB and AD.
Vector AB = B - A = (0 - (-3), 7 - 3, 0 - (-1)) = (3, 4, 1)
Vector AD = D - A = (0 - (-3), 0 - 3, -1 - (-1)) = (3, -3, 0)
Next, we take the cross product of these two vectors to find a vector perpendicular to the parallelogram's plane.
Cross product = AB × AD = (4 * 0 - (-3) * (-3), 1 * 0 - 3 * 0, 3 * (-3) - 4 * 3)
= (9, 0, -21)
The magnitude of the cross product vector represents the area of the parallelogram.
Area of parallelogram ABCD = |AB × AD| = √(9^2 + 0^2 + (-21)^2) = √(81 + 0 + 441) = √522 = 22.85 (approximately)
To find the area of triangle ABC, we can use half the magnitude of the cross product of vectors AB and AC.
Vector AC = C - A = (3 - (-3), 4 - 3, 0 - (-1)) = (6, 1, 1)
Cross product = AB × AC = (4 * 1 - 1 * 1, 1 * 6 - 6 * 1, 6 * 1 - 1 * 4)
= (3, 0, 2)
Area of triangle ABC = 1/2 |AB × AC| = 1/2 √(3^2 + 0^2 + 2^2) = 1/2 √(9 + 4) = 1/2 √13 = 1.802 (approximately)
To find the area of triangle ABD, we can use half the magnitude of the cross product of vectors AB and AD.
Area of triangle ABD = 1/2 |AB × AD| = 1/2 √(9^2 + 0^2 + (-21)^2) = 1/2 √(81 + 0 + 441) = 1/2 √522 = 11.42 (approximately)
Area of parallelogram ABCD: 22.85 (approximately)
Area of triangle ABC: 1.802 (approximately)
Area of triangle ABD: 11.42 (approximately)
Learn more about Cross product here:
https://brainly.com/question/29097076
#SPJ11
When θ = 28° , which equation can be ued to find the ditance from point A to point B?
Answers
Equation which is used to find the distance between the given points A and B for the given θ = 28° is equal to AB = x cos28°.
Diagram is attached.
As given in the question,
Diagram is attached.
Given angle θ = 28°
Hypotenuse = x
Two points A and B is on the base
Base - length = AB
In the given triangle,
Equation represents the distance between two points is:
cosθ = base / hypotenuse
⇒ cos 28° = AB / x
⇒ AB = x cos 28°
Therefore, the equation used to represent the distance between two point A and B is equal to AB = x cos28°.
Learn more about distance here
brainly.com/question/15172156
#SPJ4

when should you calculate and use a ""weighted average"" for pooled variance in an inferential t-test?
Answers
The best first step in calculating an inferential statistic for the given scenario would be to calculate the mean for older siblings.
To compare the motivation to succeed between older and younger siblings, the first step is to compute descriptive statistics for each group separately. In this case, we are interested in determining if older siblings have greater motivation.
Calculating the mean for older siblings will provide an initial understanding of the central tendency of their motivation scores. By taking the average of their responses on the 1-7 scale, we can obtain a measure of their typical motivation level.
Further statistical analysis, such as hypothesis testing or calculating effect sizes, can be performed using the mean values of both older and younger siblings. However, the initial step is to calculate the mean for older siblings to establish a baseline understanding of their motivation level.
In the given scenario, the best first step in calculating an inferential statistic is to calculate the mean for older siblings. This provides a starting point to compare their motivation to succeed with that of their younger siblings.
To know more about statistic, visit;
https://brainly.com/question/30574113
#SPJ11
complete question- When should you calculate and use a "weighted average" for pooled variance in an inferential t-test? When sample sizes are equal. When sample sizes are unequal: When data is invalid. When data is unreliable: Question 17 1 pts A researcher wants to know if older siblings have greater motivation to succeed than their younger siblings. The researcher asks a group of 50 sibling pairs how motivated they are to succeed on a scale of 1-7. As discussed in lecture, what would be the best first step in calculating an inferential statistic? Calculate the standard deviation for older siblings. Calculate the mean for younger siblings. Calculate the mean for older siblings. Subtract the motivation of younger sibling from the other (older sibling).
(01.06 MC)
Ray IL bisects angle HIJ. If mzHIL = (6x - 7)° and mzJIL = (5x + 4)°, what is mzJIL?
118°
59°
44°
11°
Answers
Option C, 59° is correct answer, The angle JIL is equal to 59 degree.
What is angle?
Two rays that have a common terminal and are referred to as the angle's sides and vertices, respectively, make up an angle in Euclidean geometry. Two rays can form angles in the plane where they are positioned. Angles are also produced when two planes intersect. These are what are known as dihedral angles. Another characteristic of intersecting curves is the angle generated by the rays that are perpendicular to the two crossing curves at the point of junction.
Given information in the question,
∠HIL = (6x-7)°
∠JIL = (5x+4)°
The ray IL bisects the ∠HIJ
Since, IL bisects angle HIJ then, angle HIL = angle JIL
So,
6x - 7 = 5x + 4
x = 11
Putting the value of x in given value of JIL to get the angle JIL
∠JIL = (6x-7)°
∠JIL = (6(11)-7)°
∠JIL = 59°
Therefore angle JIL is equal to 59 degrees.
To know more about angle, go to link
https://brainly.com/question/25716982
#SPJ13