

Answers
The graph of the equation is plotted and attached
The solution of the equation is at the point (-7, -8)
How to find solution of a graphTo find the solution of a graph, you need to identify the point or points where the graph intersects the axis or axes, depending on the number of dimensions of the graph.
The given equation is a linear equation hence the graph will be straight lines. The equations are
-2x y = 6
x - y = 1
Examining the graph the point of the intersection of the two graphs is seen to be at the point (-7, -8)
Therefore we say that the solution of the equation plotted is (-7, -8)
Learn more about graphs at:
https://brainly.com/question/25184007
#SPJ1

Related Questions
Re-write the quadratic function below in Standard Form
y=−7(x+1)^2+5
Answers
Answer:
y=-7x^2-14x-2
Step-by-step explanation:
Hope this helpz
Alex bought a total of 65 more raffle tickets than Juan. Together they bought 343
raffle tickets. How many raffle tickets did each download?
Answers
Answer:
Juan bought 139 tickets and Alex bought 204.
Step-by-step explanation:
Suppose Juan bought a total of \(x\) tickets. Then Alex bought 65 more, which is \(x+65\). The sum of both totals is \((x)+(x+65) = 2x + 65\), but we are also given that this is equal to 343. So \(2x+65 = 343\), and as such \(2x = 343-65=278\), so \(x = \frac{278}{2} = 139\). Therefore, Juan bought 139 tickets and Alex bought 65 more, which is 204.
Evaluate the following sums: 1 + 2 (n 1) + 3 (n 2) + ... + (k + 1) (n k) + ... + (n + 1) (n n). Break this sum into two sums, each of which is an identity in this section. (n 0) + 2 (n 1) + (n 2) + 2 (n 3) + ...
Answers
Binomial expression formula helps to determine the evaluate value of sums,
a) The sums of \(1 + 2 \binom{n}{1}+ 3 \binom{n}{2} + ...... + ( k+1) \binom{n}{k} + .... + (n+1) \binom{n}{n} \\ \) is equals to the 2ⁿ⁻¹ [ n + 2] .
b) The sums of \(\binom{n}{0} + 2\binom{n}{1}+ \binom{n}{2} + 2 \binom{n}{3}...... = n 2^{n -1} \\ \) is equals to the
3.2ⁿ⁻¹.
We have the expression for sums,
\(1 + 2 \binom{n}{1}+ 3 \binom{n}{2} + ...... + ( k+1) \binom{n}{k} + .... + (n+1) \binom{n}{n} \\ \)
a) In this part we have to break the above sum into two sums and then use identity.
So, the \(1 + 2 \binom{n}{1}+ 3 \binom{n}{2} + ...... + ( k+1) \binom{n}{k} + .... + (n+1) \binom{n}{n} = (1 + \binom{n}{1}+ \binom{n}{2} + ...... + \binom{n}{k} + .... + \binom{n}{n} + \1 + 2 \binom{n}{1}+ 3 \binom{n}{2} + ...... + ( k+1) \binom{n}{k} + .... + (n+1) \binom{n}{n} \\ \)
Now, using binomial expansion formula, first sum in above is defined as following,
\(1 + \binom{n}{1}+ \binom{n}{2} + ...... + \binom{n}{k} + .... + \binom{n}{n} = 2^{n }] \\ \)
Similarly the second sum in above formula is defined as the following,
\(1 \binom{n}{1}+ 2\binom{n}{1}+ 3\binom{n}{2} + ...... + (k +1) \binom{n}{k} + .... + ( n + n) \binom{n}{n} = n 2^{n -1} \\ \)
Therefore, the required value of specify sums = 2ⁿ + n2ⁿ⁻¹
= 2ⁿ⁻¹ [ n + 2]
b) Now, we have a sum is defined as
\(\binom{n}{0} + 2\binom{n}{1}+ \binom{n}{2} + 2 \binom{n}{3}...... = n 2^{n -1} \\ \)
\(= [\binom{n}{0} + \binom{n}{1}+ \binom{n}{2} + ...... + \binom{n}{k} + .... + \binom{n}{n}] + [1\binom{n}{1} + \binom{n}{3}+ \binom{n}{2} + ........ ] \\ \)
= 2ⁿ + 2ⁿ⁻¹
= 3.2ⁿ⁻¹
Hence, required value is 3.2ⁿ⁻¹.
For more information about binomial expansion, visit :
https://brainly.com/question/12249986
#SPJ4
Solve for u in terms of r, s, t, and v.
rs= –tvu
Answers
Answer:
u = -rs/tv
Step-by-step explanation:
We are given that:
rs = -tvu
Finding the value of u;
We simply divide either side by: -tv
∴ (rs) ÷ (-tv) = (-tvu) ÷ (-tv)
u = (rs) ÷ (-tv) = \(-\frac{rs}{tv}\)
Need help with the following Questions
How would you calculate the distance in miles between two people on the same line of latitude? First, sum to the total distance between the points in degrees, then multiply that sum by the statute miles per degree for the shared line of latitude. (Hint: Sometimes it is easier to visualize this by plotting it on a graph).
A. How many miles are between the following two locations: 60°N, 30°W & 60°N 50°E
B. How many miles are between the following two locations: 30°S, 60°W & 30°S 90°E
Answers
The distance between two locations on the same line of latitude can be calculated by summing the total distance between the points in degrees and multiplying it by the statute miles per degree for the shared line of latitude.
To calculate the distance in miles between two locations on the same line of latitude, we first need to find the total distance between the points in degrees. In the case of location A, which is 60°N, 30°W, and location B, which is 60°N, 50°E, the total distance between the two points is 80 degrees (50°E - 30°W).
Next, we need to multiply the sum of the degrees by the statute miles per degree for the shared line of latitude. Since the line of latitude is 60°N, we need to determine the statute miles per degree at that latitude.
The Earth's circumference at the equator is approximately 24,901 miles, and since a circle is divided into 360 degrees, the distance per degree at the equator is approximately 69.17 miles (24,901 miles / 360 degrees).
Multiplying the total distance in degrees (80 degrees) by the statute miles per degree (69.17 miles), we find that the distance between the two locations is approximately 5,533.6 miles.
Similarly, for location C, which is 30°S, 60°W, and location D, which is 30°S, 90°E, the total distance between the points is 150 degrees (90°E - 60°W). Since the line of latitude is 30°S, we use the same statute miles per degree value (69.17 miles).
Multiplying the total distance in degrees (150 degrees) by the statute miles per degree (69.17 miles), we find that the distance between the two locations is approximately 10,375.5 miles.
Therefore, the distance between locations A and B is approximately 5,533.6 miles, and the distance between locations C and D is approximately 10,375.5 miles, when calculated using the given method.
Learn more about circumference here:
https://brainly.com/question/28757341
#SPJ11
A researcher creates two random samples, each with a sample size of 12. He
does not find a statistically significant difference between the two groups.
Which of the following statements is correct? Select all that apply.
A. The sample size does not impact results of statistical
significance.
B. Since random samples were used, the conclusion is likely to be
true.
C. Since the sample size of each group is greater than 10, the
conclusion is likely to be true.
D. Since the sample size is small, the conclusion is likely to be
untrue.
SUBMIT
Answers
None of the given statements (A, B, C, or D) can be selected as correct based solely on the information provided.
From the given information, we have two random samples, each with a sample size of 12, and no statistically significant difference is found between the two groups. Based on this, we can evaluate the given statements:
A. The statement "The sample size does not impact results of statistical significance" is not correct.
The sample size does impact the results of statistical significance. Generally, larger sample sizes increase the power of the statistical test and improve the ability to detect significant differences.
B. The statement "Since random samples were used, the conclusion is likely to be true" is not necessarily correct.
While random sampling helps to reduce bias and increase generalizability, it does not guarantee the truth of the conclusion.
Other factors such as sample representativeness, research design, and analysis methods also contribute to the validity of the conclusion.
C. The statement "Since the sample size of each group is greater than 10, the conclusion is likely to be true" is not entirely accurate.
While having sample sizes greater than 10 is often considered a guideline for certain statistical tests, it is not the sole determining factor for the validity of the conclusion.
D. The statement "Since the sample size is small, the conclusion is likely to be untrue" is not necessarily correct.
The small sample size itself does not automatically invalidate the conclusion.
It depends on the specific research question, effect size, variability, and statistical power of the test.
For similar question on statements.
https://brainly.com/question/26240841
#SPJ8
Explain why the following form linearly dependent sets of vec- tors. (Solve this problem by inspection.) (a) uj = (-1, 2, 4) and u2 = (5, –10, –20) in R3 (b) u = (3, -1), u2 = (4, 5), uz = (-4, 7) in R2 (c) pı = 3 – 2x + x2 and p2 = 6 – 4x + 2x2 in P2 _3 4 3 -4 (d) A = and B= | in M22
Answers
(a) This can be seen by multiplying u1 by -5 and comparing it to u2: -5u1 = (5, -10, -20), which is equal to u2. (b) This can be seen by adding u1 and u2 together and comparing it to u3: u1 + u2 = (7, 4) and u3 = (-4, 7), which are equal. (c) This can be seen by multiplying p1 by 2 and comparing it to p2: 2p1 = 6 - 4x + 2x², which is equal to p2. (d) A and B are not scalar multiples of each other and are linearly independent.
(a) The two vectors u1 and u2 are linearly dependent because u2 is equal to -5 times u1. This can be seen by multiplying u1 by -5 and comparing it to u2: -5u1 = (5, -10, -20), which is equal to u2.
(b) The three vectors u1, u2, and u3 are linearly dependent because u3 is equal to the sum of u1 and u2. This can be seen by adding u1 and u2 together and comparing it to u3: u1 + u2 = (7, 4) and u3 = (-4, 7), which are equal.
(c) The two polynomials p1 and p2 are linearly dependent because p2 is equal to twice p1. This can be seen by multiplying p1 by 2 and comparing it to p2: 2p1 = 6 - 4x + 2x², which is equal to p2.
(d) The two matrices A and B are linearly independent because they have different determinants. The determinant of A is -15 and the determinant of B is 16, which are not equal. Therefore, A and B are not scalar multiples of each other and are linearly independent.
Learn more about vectors here:
https://brainly.com/question/14480157
#SPJ11
C^2 = 27
Pls help me I’m doing my missing math work :,)
Answers
c=sqrt(27)
c=5.196
Find the selling price.
Cost to store: $50
Markup: 10%
Answers
Based on the information given the selling price is $55.
Selling price
Using this formula
Selling price=Cost price+(Cost price×Markup percentage)
Where:
Selling price=$50
Markup percentage=10%
Let plug in the formula
Selling price=$50+($50×10%)
Selling price=$50+$5
Selling price=$55
Inconclusion the selling price is $55.
Learn more about selling price here:brainly.com/question/1153322
hope this helps
7x means?? help im unable to solve
Answers
Answer:
7x, or seven times in multiplication
Step-by-step explanation:
Hope it helps
50 is what percent of 1000
Answers
Answer:500
explanchion: 1000/50=500
Help Each letter of the alphabet is assigned a numerical value according to its position in the alphabet. The function defined by f(x)4x 5 was used to encode the following message 47 31 23 79 15 43 27 -1 71 -1 67 67 31 83 15 11 Find the inverse function and determine the message. The inverse function is (Use integers or fractions for any numbers in the expression.)
Answers
The inverse function can be found by solving for x in terms of y in the equation y = 4x + 5. Once we have the inverse function, we can apply it to each numerical value in the encoded message to get the corresponding letter of the alphabet.
The given encoding function is f(x) = 4x + 5. To find the inverse function, we need to solve for x in terms of y. We start by writing the equation as y = 4x + 5 and then isolate x by subtracting 5 from both sides and dividing by 4. This gives us x = (y - 5) / 4.
Now we can use this inverse function to decode the message. We start by applying the inverse function to each numerical value in the encoded message to get the corresponding letter of the alphabet. For example, the first numerical value in the message is 47, so we apply the inverse function to get x = (47 - 5) / 4 = 11.5. Since x must be an integer to correspond to a letter of the alphabet, we round down to get x = 11, which corresponds to the letter K.
We repeat this process for each numerical value in the message, and we get the following sequence of letters: K A W T O H L _ G _ C C A S O L. The underscores correspond to numerical values that do not correspond to any letter of the alphabet.
Therefore, the decoded message is "KAWTOHL_GC_CASOL".
Learn more about Function:
brainly.com/question/30721594
#SPJ11
A recent survey of 2500 college students revealed that during any weekend afternoon, 1480 receive a text message, 920 receive an e-mail and 547 receive both a text message and an e-mail. Suppose a college student is selected at random, what is the probability that he/she neither receives a text message nor an email during any weekend afternoon?
Answers
The probability that he/she neither receives a text message nor an email during any weekend afternoon be 0.3000.
What is meant by probability?The area of mathematics known as probability deals with numerical descriptions of how likely it is for an event to happen or for a claim to be true. A number between 0 and 1 is the probability of an event, where, broadly speaking, 0 denotes the event's impossibility and 1 denotes its certainty.
Using the method for the union of two sets, we can calculate the number of students who receive either a text message or an email (or both) based on the above data:
Number of students who receive either a text message or an e-mail = Number of students who receive a text message + Number of students who receive an e-mail - Number of students who receive both
= 1364 + 857 - 470
= 1751
The proportion of students who don't receive either a text message or an email divided by the total sample of students is the probability that a student will not receive either:
P(neither T nor E) = (2500 - 1751) / 2500
= 749 / 2500
= 0.2996
Rounding to four decimal places:
P(neither T nor E) = 0.2996 ≈ 0.3000
To learn more about probability refer to:
https://brainly.com/question/13604758
#SPJ1
30. Trisha wants to create the perpendicular bisector of a line segments
AB. She places her compass of point A and opens it with the width more
than 1/2 the length of the line segment AB. She makes arcs above and
below the line segment. What could be Trisha's next step to create the
perpendicular bisector of line segment AB?
A
>connect the two arcs using a straightedge
B>connect each arc with point B using a straightedge
C>place the compass on the approximate midpoint and draw intercepting arcs
D>place the compass on point B and complete the same steps that she did for point A
Answers
The answer is D:
Place the compass on point B and complete the same steps that she did for point A
The process is that you draw arcs above and below the line from both ends, but it's crucial that the compass' radius is the same from both ends of the line. Then you draw the line that connects the two intersection points to form your perpendicular bisector.
If the diameter is 12 miles. What is the circles circumference?
Answers
C≈37.7mi
I hope it's helpful
T/F: an example of a weight used in the calculation of a weighted index is quantity consumed in a base period.
Answers
False. The quantity consumed in a base period is not an example of a weight used in the calculation of a weighted index.
In the calculation of a weighted index, a weight is a factor used to assign relative importance or significance to different components or categories included in the index. These weights reflect the contribution of each component to the overall index value. The purpose of assigning weights is to ensure that the index accurately reflects the relative importance of the components or categories being measured.
An example of a weight used in a weighted index could be market value, where the weight is determined based on the market capitalization of each component. This means that components with higher market values will have a greater weight in the index calculation, reflecting their larger impact on the overall index value.
On the other hand, the quantity consumed in a base period is not typically used as a weight in a weighted index. Instead, it is often used as a reference point or benchmark for comparison. For example, in a price index, the quantity consumed in a base period is used as a constant quantity against which the current prices are compared to measure price changes.
Therefore, the statement that the quantity consumed in a base period is an example of a weight used in the calculation of a weighted index is false.
To learn more about weight, click here:
brainly.com/question/19053239
#SPJ1
PLS HELP ME WITH THIS!!!


Answers
option C is the correct answer. sin β = 15 / 17
How to work itGiven data
Right angled triangle has sides
opposite = 15
adjacent = 8
Hypotenuse = 17
sin β = opposite / hypotenuse
substituting the values gives
sin β = 15 / 17
Read more on SOH CAH TOA here: https://brainly.com/question/20020671
#SPJ1
Find the length of GH.
A. About 4.5 units
B. 20 units
C. 6 units
D. About 2 4 units
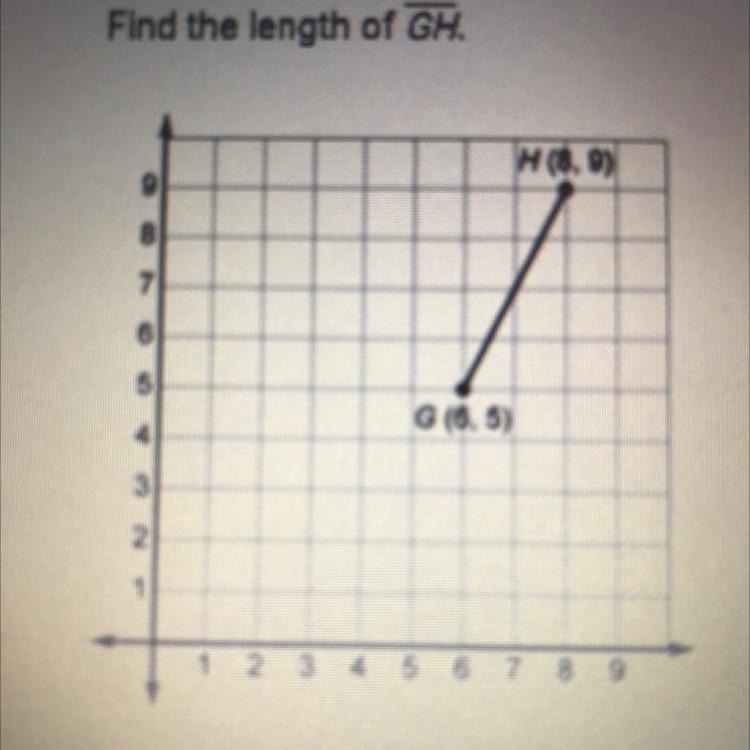
Answers
Answer:
C. 6 units
Step-by-step explanation: Graph the line using the slope and y-intercept, or two points.
Slope:
0
Answer:
Its A: 4.5 units
Step-by-step explanation:
at 2:40 p.m. a plane at an altitude of 30,000 feetbegins its descent. at 2:48 p.m., the plane is at25,000 feet. find the rate in change in thealtitude of the plane during this time.
Answers
The rate of change in altitude of the plane during the time is 625 ft/min.
Rate of changeGiven the Parameters:
Altitude at 2.40 pm = 30000 feets
Altitude at 2.48 pm = 25000 feets
Rate of change = change in altitude/change in time
change in time = 2.48 - 2.40 = 8 minutes
change in altitude = 30000 - 25000 = 5000 feets
Rate of change = 5000/8 = 625 feets per minute
Therefore, the rate of change in altitude of the plane is 625 ft/min.
Learn more on rate of change:https://brainly.com/question/25184007
#SPJ4
please i’m not good at math i need help i’m doing summer school online and i need help

Answers
Answer:
135
____________
2*25/5=10
100*5=500
15*5=75
75*5=375
10+500-375=135
Hope this helps :3
HELP PLEASEEEEEEEE I GIVE BRAINLIEST

Answers
Answer:
Option (3)
Step-by-step explanation:
If the triangle FGH is dilated by a scale factor 'k', then the sides of the image triangle F'G'H' will get dilated by 'k' times but the angles will measure the same.
In simpler words, both the triangles will be similar
Therefore, sin(F) and sin(F') will measure the same.
Option (3) will be the correct option.
pls help
10. Simplify 4 ×5 – 32 × 2 ÷ 6
11. Simplify −2(−9 + 3)
15. Solve -a/13 =18
18. Solve 7 = 5x 3(x – 2) 5
19. Solve 11w 2(3w - 1) = 15 w
21. If U = {natural numbers less than
20} and N = {factors of 18}, what is
N'
22. Solve and graph 17 – 2a ≤ 29
23. Solve and graph 12c + 6 > 9c – 15
Answers
1. The expression can be simplified as follows: 4 × 5 – 32 × 2 ÷ 6 = 20 – 16 ÷ 6 = 20 – 2 = 18.
2. The expression can be simplified as follows: -2(-9 + 3) = -2(-6) = 12.
3. To solve this equation, we need to isolate the variable a. We can do this by dividing both sides of the equation by -13: -a/13 = 18. Dividing both sides of the equation by -13 gives us a = -18 * 13 = -234.
4. To solve this equation, we need to isolate the variable x. We can do this by moving all terms involving x to one side of the equation and all constants to the other side. This gives us: 7 = 5x + 3(x – 2). We can then distribute the 3 to get 7 = 5x + 3x – 6. Combining like terms, we get 7 = 8x – 6, which we can solve by adding 6 to both sides to get 13 = 8x. Dividing both sides of the equation by 8 gives us x = 13/8.
5. To solve this equation, we need to isolate the variable w. We can do this by moving all terms involving w to one side of the equation and all constants to the other side. This gives us: 11w + 2(3w - 1) = 15 w. We can then distribute the 2 to get 11w + 6w - 2 = 15w. Combining like terms, we get 17w - 2 = 15w, which we can solve by adding 2 to both sides to get 17w = 15w + 2. Subtracting 15w from both sides gives us 2w = 2, which we can solve by dividing both sides by 2 to get w = 1.
6. N' is the complement of the set N. This means that N' contains all elements that are not in the set N. Since the set N contains all factors of 18, N' will contain all natural numbers less than 20 that are not factors of 18. Some elements of N' are 1, 2, 4, 5, 7, 8, 11, 13, 14, 16, and 17.
7. The solution to the inequality 17 - 2a ≤ 29 is all values of a that satisfy the inequality. To find these values, we can first subtract 17 from both sides of the inequality to get -2a ≤ 12. Dividing both sides of the inequality by -2 gives us a ≥ -6. This means that the solution is the set of all values of a that are greater than or equal to -6. This solution can be represented on a number line
8.To solve the inequality 17 – 2a ≤ 29, we first need to isolate the variable on one side of the inequality. To do this, we need to subtract 17 from both sides, which gives us -2a ≤ 12. Dividing both sides by -2, we get a ≥ -6. To graph this inequality, we can use a number line. We would draw a solid line at -6 and shade the region to the right of the line, since a is greater than or equal to -6.
9. To solve the inequality 12c + 6 > 9c – 15, we first need to isolate the variable on one side of the inequality. To do this, we need to subtract 9c from both sides, which gives us 3c + 6 > -15. Next, we need to add 15 to both sides, which gives us 3c + 21 > 0. Finally, we can divide both sides by 3 to get c > -7. To graph this inequality, we can use a number line. We would draw a solid line at -7 and shade the region to the right of the line, since c is greater than -7.
What’s the equation?

Answers
PLEASE PLEASE PLEASE HELO ILL GIVE BRAINEST

Answers
Answer:
1. g = 4
2. g = 19
3. g = 39
4. g = 59
Step-by-step explanation:
Answer:
4,19,39,59
Step-by-step explanation:
it’s actually pretty simple.
for the first one you take 1 and plug it into n which looks like:
g=5(1)-1
then find yourself answer:
5(1)= 5
5-1=4
answer is 4
then you plug your four into n:
5(4)-1= 19
answer is 19
then you plug your 8 into n:
5(8)-1=39
answer is 39
then you plug your 12 into n
5(12)-1= 59
answer 59
I HOPE I HELPED!!!!!!!!
using a calculator,find the value of each mathematical statement.
PLSSS HELP

Answers
The exponents are solved below\
What are exponents?
Exponentiation is a mathematical process denoted by the symbol bn that involves two integers, the base b and the exponent or power n, and is spoken as "b (raised) to the (power of) n." Exponentiation corresponds to repeated multiplication of the base when n is a positive integer: bn is the product of multiplying n bases. Typically, the exponent is displayed as a superscript to the right of the base. In such scenario, bn is referred to as "b raised to the nth power," "b (raised) to the power of n," "the nth power of b," "b to the nth power," or, more succinctly, "b to nth." In other words, when a base raised to one exponent is multiplied by the same base raised to another exponent, the exponents accumulate.
The exponents are solved as follows
(10⁻²)⁹ = 10⁻¹⁸ = 1/10¹⁸
10⁻³ - 10⁻⁸ = 1/10³ - 1/10⁸ = (10⁵ - 10⁸)/10⁸ = 9.9999x10⁻⁴
To know more about exponents, click on the link
https://brainly.com/question/11761858
#SPJ9
Which situation is best modeled by the equation 9+=16

Answers
Answer:
4th option.
Step-by-step explanation:
You pay $9 and $__ for a total of $16.
$9 + $__ = $16.
9+__=16
Christy bought movie tickets for herself and 5 of her friends and the total cost was $75.60. If each ticket was the same price with tax, how much did each ticket cost?
Answers
Total cost = $75.60
Then
75.60/6 = 12.60
What is 30,000 expressed in scientific notation?
A) 3 x 104
B) 3 x 10002
C) 3 x 103
D) 1 x 103
Answers
Answer:
B
Step-by-step explanation:
Hope this helps : )
the order of a moving-average (ma) process can best be determined by the multiple choice partial autocorrelation function. box-pierce chi-square statistic. autocorrelation function. all of the options are correct. durbin-watson statistic.
Answers
The order (p) of an autoregressive (AR) process can be determined by Durbin-Watson Statistic, Box-Pierce Chi-square Statistic, Autocorrelation Function (ACF), and Partial Autocorrelation Function (PACF) coefficients., option E is correct.
The Durbin-Watson statistic is used to test for the presence of autocorrelation in the residuals of a time series model.
It can provide an indication of the order of the AR process if it shows significant autocorrelation at certain lags.
The Box-Pierce test is a statistical test used to assess the goodness-of-fit of a time series model.
It examines the residuals for autocorrelation at different lags and can help determine the appropriate order of the AR process.
Autocorrelation Function (ACF): The ACF is a plot of the correlation between a time series and its lagged values. By analyzing the ACF plot, one can observe the significant autocorrelation at certain lags, which can suggest the order of the AR process.
The PACF measures the direct relationship between a time series and its lagged values after removing the effects of intermediate lags.
Significant coefficients in the PACF plot at certain lags can indicate the appropriate order of the AR process.
By considering all of these methods together and analyzing their results, one can make a more informed decision about the order (p) of an autoregressive (AR) process.
To learn more on Autoregressive process click:
https://brainly.com/question/32519628
#SPJ4
The order (p) of a autogressiove(AR) process best be determined by the :
A. Durbin-Watson Statistic
B. Box Piece Chi-square statistic
C. Autocorrelation function
D. Partial autocorrelation fuction coeficcents to be significant at lagged p
E. all of the above
A certain type of light bulb has a normally distributed life length with a mean life length of 975 hours. The standard deviation of life length was estimated to be s=45 hours from a sample of 25 bulbs. (Type B problem)
Find the 95% confidence interval for the population mean life length and interpret its meaning.
If the 95% confidence interval was calculated using a population standard deviation instead, which one would be wider and why?
Answers
a. The 95% confidence interval for the population mean life length is (956.712, 993.288).
b. We are 95% confident that the true population mean life length of the light bulbs falls within the interval (956.712, 993.288) hours.
c. The 95% confidence interval was calculated using a population standard deviation insteadwould be wider. This is because using the population standard deviation assumes that we have more precise knowledge of the population, leading to less uncertainty in our estimate.
a. To find the 95% confidence interval for the population mean life length, we can use the formula:
Confidence Interval = sample mean ± (critical value) * (standard deviation / sqrt(sample size))
In this case, the mean life length is 975 hours, the standard deviation is 45 hours, and the sample size is 25. The critical value can be obtained from the t-distribution table for a 95% confidence level with (sample size - 1) degrees of freedom.
To calculate the critical value, we need to determine the degrees of freedom, which is (sample size - 1) = (25 - 1) = 24. From the t-distribution table, with 24 degrees of freedom and a 95% confidence level, the critical value is approximately 2.064.
Plugging these values into the formula, we get:
Confidence Interval = 975 ± (2.064) * (45 / sqrt(25))
= 975 ± 18.288
So, the 95% confidence interval for the population mean life length is (956.712, 993.288).
b. Interpretation: We are 95% confident that the true population mean life length of the light bulbs falls within the interval (956.712, 993.288) hours. This means that if we were to take multiple random samples and calculate their confidence intervals, approximately 95% of those intervals would contain the true population mean.
c. If the 95% confidence interval was calculated using the population standard deviation instead of the sample standard deviation, the interval would be wider.
This is because using the population standard deviation assumes that we have more precise knowledge of the population, leading to less uncertainty in our estimate. In contrast, using the sample standard deviation incorporates some degree of uncertainty due to the variability observed in the sample, resulting in a narrower interval.
Learn more about confidence interval at https://brainly.com/question/31307248
#SPJ11