Find the product 0.025 x 7
A. 0.0175
B: 0.175
C. 1.75
D. 17.5
Answers
Answer:
b
Step-by-step explanation:
used a calucator
Related Questions
A plant has an initial height of 2 inches and grows at a constant rate of 2 inches each month. A second plant that also grows at a constant rate has an initial height of 1 inch and is 29 inches tall after 1 year. After how many months are the plants the same height?
Answers
Answer:
Answer:4.8 monthsStep-by-step explanation:First, let's write down the information that we are given.Plant A: Initial Height: 3 in.Constant Rate of Growth (CRG): 2in/month (2 inches per month)Plant B:Initial Height: 1 in.CRG: 29in/year (29 inches per year)We can see that Plant B grows 29 inches per year, so lets convert Plant B's 'CGR' to months.Plant B - Divide by 12 (12 months in a year)29/12 in/yearNow, Lets put these into equations:Plant A: y = 2x + 3Plant B: y = 29/12 x + 1Now, set these two equations together and solve for x.2x + 3 = 29/12 x + 12 = 5/12 x4.8So, after 4.8 months, the plants will be the same height.
hope it helps you
β is a whole number. β x β = 64.What is the value of β +β?
Answers
Answer:
β + β = 16
Step-by-step explanation:
β x β = 84 => β = 8
=> β + β = 8 + 8 = 16
Hope this helps!
The owner of Britten's Egg Farm wants to estimate the mean number of eggs laid per chicken. A sample of 18 chickens shows they laid an average of 20 eggs per month with a standard deviation of 5 eggs per month.
(a-1) What is the value of the population mean?
20
It is unknown.
5
(a-2) What is the best estimate of this value?
Best estimate
(c)
For a 95% confidence interval, what is the value of t? (Round your answer to 3 decimal places.)
Value of t
(d)
Determine the 95% confidence interval for the population mean. is (Round your answers to 2 decimal places.)
Confidence interval to
(e-1) Would it be reasonable to conclude that the population mean is 17 eggs?
No
Yes
(e-2) What about 18 eggs?
Yes
No
Answers
(a-1) The value of the population mean is unknown.
(a-2) The best estimate of the population mean is the sample mean, which is 20 eggs.
(c) The value of t for a 95% confidence interval with 17 degrees of freedom is approximately 2.110.
(d) the 95% confidence interval for the population mean is approximately (17.902, 22.098).
(e-1) It would not be reasonable to conclude that the population mean is 17 eggs.
(e-2) It would be reasonable to conclude that the population mean is 18 eggs.
(a-1) The given information provides the sample mean (20 eggs) and the sample standard deviation (5 eggs), but it does not directly provide the population mean.
(a-2) In the absence of other information, the sample mean is a reasonable estimate of the population mean.
(c) For a 95% confidence interval, the value of t can be determined using the t-distribution with n-1 degrees of freedom, where n is the sample size. In this case, the sample size is 18, so the degrees of freedom is 18 - 1 = 17.
Using a t-distribution table or a statistical software, the value of t for a 95% confidence interval with 17 degrees of freedom is approximately 2.110.
(d) To determine the 95% confidence interval for the population mean, we can use the formula: Confidence interval = sample mean ± (t * standard error), where the standard error is the sample standard deviation divided by the square root of the sample size.
In this case, the sample mean is 20, the standard deviation is 5, the sample size is 18, and the value of t is 2.110. Plugging in these values, the confidence interval is 20 ± (2.110 * (5 / √18)), which evaluates to approximately 20 ± 2.098.
(e-1) The 95% confidence interval calculated in part (d) does not include 17 eggs, indicating that it is unlikely for the population mean to be 17 eggs.
(e-2) The 95% confidence interval calculated in part (d) includes 18 eggs, suggesting that it is plausible for the population mean to be 18 eggs.
For more such questions on population mean
https://brainly.com/question/31101410
#SPJ8
Joey has 42 marbles. He has 7 times as many marbles as Sam has. How many marbles does Sam have? *
49
35
7
6
Answers
Answer:
sam has 6 marbles
Step-by-step explanation:
if Joey has 7 times as many as Sam then 42/7= 6
if m<2=(3x+2) and m<3=100, what is the value of x?
Answers
Answer:
34523
Step-by-step explanation:
345-23=po
If m∠2 =(3x+2)° and m∠3 = 100° and the angle is linear pairs the value of x will be 26°.
What is an angle?When two lines or rays converge at the same point, the measurement between them is called an "Angle."
It is given that,
m∠2 =(3x+2)°
m∠3 = 100
If the ∠2 and ∠3 are linear pairs the sum of the angles is 180°.
Only when a pair of neighboring angles add up to 180 degrees is the pair referred to be a linear angle. For instance, the sum of the neighboring linear angles of 40 degrees and 140 degrees will equal 180 degrees, making them known as linear angles.
∠2 + ∠3 = 180°
(3x+2) + 100 = 180°
(3x+2) = 180° - 100
(3x+2) = 80
3x = 80 -2
3x =78
x =26
Thus, if m∠2 =(3x+2)° and m∠3 = 100° and the angle is linear pairs the value of x will be 26°.
Learn more about the angle here:
brainly.com/question/7116550
#SPJ5

to 4 percent. If Calvin made monthly payments of $220 at the end of each month, how long would it take to pay off his credit card? a. If Calvin made monthly payments of $165 at the end of each month, how long would it take to pay off his credit card? months (Round up to the nearest unit.)
Answers
Rounding up to the nearest unit, it would take Calvin approximately 27 months to pay off his credit card with a monthly payment of $165.
To determine how long it would take Calvin to pay off his credit card, we need to consider the monthly payment amount and the interest rate. Let's calculate the time it would take for two different monthly payment amounts: $220 and $165.
a. Monthly payment of $220:
Let's assume the initial balance on Calvin's credit card is $3,000, and the annual interest rate is 4 percent. To calculate the monthly interest rate, we divide the annual interest rate by 12 (number of months in a year):
Monthly interest rate = 4% / 12 = 0.3333%
Now, we can calculate the time it would take to pay off the credit card using the monthly payment of $220 and the monthly interest rate. We'll use a formula for the number of months required to pay off a loan with fixed monthly payments:
n = -(log(1 - (r * P) / A) / log(1 + r))
Where:
n = number of months
r = monthly interest rate (as a decimal)
P = initial balance
A = monthly payment
Plugging in the values:
n = -(log(1 - (0.003333 * 3000) / 220) / log(1 + 0.003333))
Using a calculator, we can find:
n ≈ 15.34
Rounding up to the nearest unit, it would take Calvin approximately 16 months to pay off his credit card with a monthly payment of $220.
b. Monthly payment of $165:
We can repeat the same calculation using a monthly payment of $165:
n = -(log(1 - (0.003333 * 3000) / 165) / log(1 + 0.003333))
Using a calculator, we find:
n ≈ 26.39
Please note that these calculations assume that Calvin does not make any additional charges on his credit card during the repayment period. Additionally, the interest rate and the balance are assumed to remain constant. In practice, these factors may vary and could affect the actual time required to pay off the credit card balance.
Learn more about interest rate at: brainly.com/question/28236069
#SPJ11
Help me please! Felicity put down $800 on a used car. She took out a loan to pay off the balance of the cost of the car. Her monthly payment will be $175. After 9 months how much will she have paid for the car? *
Answers
Answer:
2375
Step-by-step explanation:
i belive is 2375. did this in my mind.
Answer:
$2375
Step-by-step explanation:
800+9(175)=800+1575
=2375
how do I find the angles of a triangle when given all the lengths and no angle?
Answers
Explain why predictive accuracy is not the same as goodness-of-fit. How do the strategies, such as
holdout, cross validation, and bootstrap sampling, support predictive performance evaluation?
Answers
Predictive accuracy and goodness-of-fit are not the same because they assess different aspects of a predictive model. Predictive accuracy focuses on how well a model predicts outcomes on new, unseen data, while goodness-of-fit measures how well a model fits the observed data used for training.
Strategies like holdout, cross-validation, and bootstrap sampling support predictive performance evaluation by providing methods to estimate how well a model will generalize to new data. Holdout involves splitting the data into training and testing sets, allowing the model to be evaluated on unseen data. Cross-validation further enhances this by performing multiple iterations of holdout with different train-test splits, providing more robust performance estimates. Bootstrap sampling generates multiple bootstrap samples from the original data, allowing for the calculation of confidence intervals and assessing model stability.
You can learn more about confidence intervals at
https://brainly.com/question/20309162
#SPJ11
"The North Valley Real Estate data reports information on homes on the market.
Let selling price be the dependent variable and size of the home the independent variable. Determine the regression equation. Estimate the selling price for a home with an area of 2,200 square feet. Determine the 95% confidence interval for all 2,200-square-foot homes and the 95% prediction interval for the selling price of a home with 2,200 square feet.
Let days-on-the-market be the dependent variable and price be the independent variable. Determine the regression equation. Estimate the days-on-the-market of a home that is priced at $300,000. Determine the 95% confidence interval of days-on-the-market for homes with a mean price of $300,000, and the 95% prediction interval of days-on-the-market for a home priced at $300,000.
Can you conclude that the independent variables "days on the market" and "selling price" are positively correlated? Are the size of the home and the selling price positively correlated? Use the .05 significance level. Report the p-value of the test. Summarize your results in a brief report."
Answers
The problem involves analyzing two regression models in the context of real estate data. The first model relates selling price to the size of the home, while the second model relates days-on-the-market to the price of the home.
In the first model, the regression equation is obtained by fitting a line to the data, with selling price as the dependent variable and the size of the home as the independent variable. The equation will provide the estimated relationship between these variables. Using this equation, the selling price for a home with an area of 2,200 square feet can be estimated.
For the 95% confidence interval for all 2,200-square-foot homes, the interval will provide a range within which the true mean selling price lies. Similarly, the 95% prediction interval for the selling price of a home with 2,200 square feet will provide a range within which an individual selling price is likely to fall.
In the second model, the regression equation relates days-on-the-market to the price of the home. By fitting a line to the data, we can determine the equation and estimate the days-on-the-market for a home priced at $300,000.
The 95% confidence interval for homes with a mean price of $300,000 provides a range within which the true mean days-on-the-market lies. The 95% prediction interval for a home priced at $300,000 gives a range within which an individual days-on-the-market value is likely to fall.
Learn more about confidence interval here:
https://brainly.com/question/32546207
#SPJ11
5e = e + 10 Please help with this
Answers
Five e minus one e equal to ten
Four e equal to ten
e equal to ten over four
e equal to 2.5
Can yall help me with this pls its due rn and im cryinggggg ill definetly give brainliesttt : (
JUST WITH NUMBER 2 PLS THE SECOND ATTACEMENT :(


Answers
Answer: 5 (4x + 7)
Step-by-step explanation:Wouldn't it be 5(4x+7). So I guess the sign it's looking for is an addition symbol.
The baxter boys can prepare newspapers for delivery on a rainy morning at a rate of 35 in 3 minutes. how long will it take them to the nearest minute to prepare 131 papers?
Answers
To determine how long it will take the Baxter boys to prepare 131 papers, we can use the concept of rate and proportion.
It will take approximately 11 minutes and 14 seconds (to the nearest minute) for the Baxter boys to prepare 131 papers. Given that the Baxter boys can prepare 35 papers in 3 minutes, we can set up a proportion to solve for the time it will take to prepare 131 papers.
First, let's set up the proportion using the information given about the rate of working:
35 papers / 3 minutes = 131 papers / x minutes
To solve for x, we can cross-multiply and then divide:
35 * x = 3 * 131
35x = 393
x = 393 / 35
x ≈ 11.229
Therefore, it will take approximately 11 minutes and 14 seconds (to the nearest minute) for the Baxter boys to prepare 131 papers.
Learn more about proportion here:
https://brainly.com/question/870035
#SPJ11
(7x100)+(4x1/100)+(8x1/1000)
Answers
Answer:
7 x 100 = 700. 4 x 100 = 400. 8 x 1000 = 8000. Add them all together and you have = 8500.
Step-by-step explanation:
Hope this is correct and helpful
HAVE A GOOD DAY!

is 6.34 a rational number
Answers
Answer: Yes
Step-by-step explanation: can be written as 6 17/50
Answer: yes because its a terminating number
Procter and Gamble (PG) paid an annual dividend of $2.95 in 2018. You expect PG to increase its dividends by 7.4% per year for the next five years (through 2023), and thereafter by 2.6% per year. If the appropriate equity cost of capital for Procter and Gamble is 8.6% per year, use the dividend-discount model to estimate its value per share at the end of 2018.
Answers
The dividend in 2018 was $2.95, and it is expected to grow at a rate of 7.4% for the next five years and 2.6% thereafter. With an equity cost of capital of 8.6%, the value per share at the end of 2018 can be calculated.
To calculate the value per share at the end of 2018, we need to discount the expected future dividends using the dividend-discount model. The model assumes that the value of a stock is equal to the present value of all its expected future dividends.
First, we need to calculate the dividends for each year from 2019 to 2023. We start with the dividend in 2018, which was $2.95. We then increase it by 7.4% each year for the next five years:
Dividend in 2019 = $2.95 * (1 + 7.4%) = $3.17
Dividend in 2020 = $3.17 * (1 + 7.4%) = $3.40
Dividend in 2021 = $3.40 * (1 + 7.4%) = $3.65
Dividend in 2022 = $3.65 * (1 + 7.4%) = $3.92
Dividend in 2023 = $3.92 * (1 + 7.4%) = $4.22
After 2023, the dividend is expected to grow at a rate of 2.6% per year. To find the value per share at the end of 2018, we discount the future dividends to their present value using the equity cost of capital of 8.6%.
The present value of the dividends can be calculated as follows:
PV = (D1 / (1 + r)) + (D2 / (1 + r)^2) + ... + (Dn / (1 + r)^n)
where PV is the present value, D1 to Dn are the dividends for each year, r is the equity cost of capital, and n is the number of years.
In this case, n = 5 because we are discounting the dividends for the next five years. Let's calculate the present value:
PV = ($3.17 / (1 + 8.6%)) + ($3.40 / (1 + 8.6%)^2) + ($3.65 / (1 + 8.6%)^3) + ($3.92 / (1 + 8.6%)^4) + ($4.22 / (1 + 8.6%)^5)
PV = $3.17 / 1.086 + $3.40 / 1.086^2 + $3.65 / 1.086^3 + $3.92 / 1.086^4 + $4.22 / 1.086^5
PV ≈ $2.91 + $3.07 + $3.24 + $3.41 + $3.59
PV ≈ $16.22
Therefore, the estimated value per share of Procter and Gamble at the end of 2018 using the dividend-discount model is approximately $16.22.
Learn more about cost here: brainly.com/question/14566816
#SPJ11
The dividend in 2018 was $2.95, and it is expected to grow at a rate of 7.4% for the next five years and 2.6% thereafter. With an equity cost of capital of 8.6%, the value per share at the end of 2018 can be calculated.
To calculate the value per share at the end of 2018, we need to discount the expected future dividends using the dividend-discount model.
The model assumes that the value of a stock is equal to the present value of all its expected future dividends. First, we need to calculate the dividends for each year from 2019 to 2023. We start with the dividend in 2018, which was $2.95. We then increase it by 7.4% each year for the next five years:
Dividend in 2019 = $2.95 * (1 + 7.4%) = $3.17
Dividend in 2020 = $3.17 * (1 + 7.4%) = $3.40
Dividend in 2021 = $3.40 * (1 + 7.4%) = $3.65
Dividend in 2022 = $3.65 * (1 + 7.4%) = $3.92
Dividend in 2023 = $3.92 * (1 + 7.4%) = $4.22
After 2023, the dividend is expected to grow at a rate of 2.6% per year. To find the value per share at the end of 2018, we discount the future dividends to their present value using the equity cost of capital of 8.6%.
The present value of the dividends can be calculated as follows:
PV = (D1 / (1 + r)) + (D2 / (1 + r)^2) + ... + (Dn / (1 + r)^n) where PV is the present value, D1 to Dn are the dividends for each year, r is the equity cost of capital, and n is the number of years.
In this case, n = 5 because we are discounting the dividends for the next five years. Let's calculate the present value: PV = ($3.17 / (1 + 8.6%)) + ($3.40 / (1 + 8.6%)^2) + ($3.65 / (1 + 8.6%)^3) + ($3.92 / (1 + 8.6%)^4) + ($4.22 / (1 + 8.6%)^5)
PV = $3.17 / 1.086 + $3.40 / 1.086^2 + $3.65 / 1.086^3 + $3.92 / 1.086^4 + $4.22 / 1.086^5
PV ≈ $2.91 + $3.07 + $3.24 + $3.41 + $3.59
PV ≈ $16.22
Therefore, the estimated value per share of Procter and Gamble at the end of 2018 using the dividend-discount model is approximately $16.22.
Learn more about cost here: brainly.com/question/14566816
#SPJ11
Factor using the GCF. 30x + 18
1 point
O 30x + 18 Prime (cannot be factored)
O 2(15x+9)
O 3(10x+6)
6(5x + 3)
Answers
Explanation: factor out the 6 as it goes both in 30 and 18. 30 divided by 5 is 6 and 18 divided by 6 is 3. The 5 and the 3 are what goes in parentheses so the answer will be 6 because it is GCF (5x+3).
Hope that helps! Have a good day :)
NEED HELP ASAP due by 8:00 today
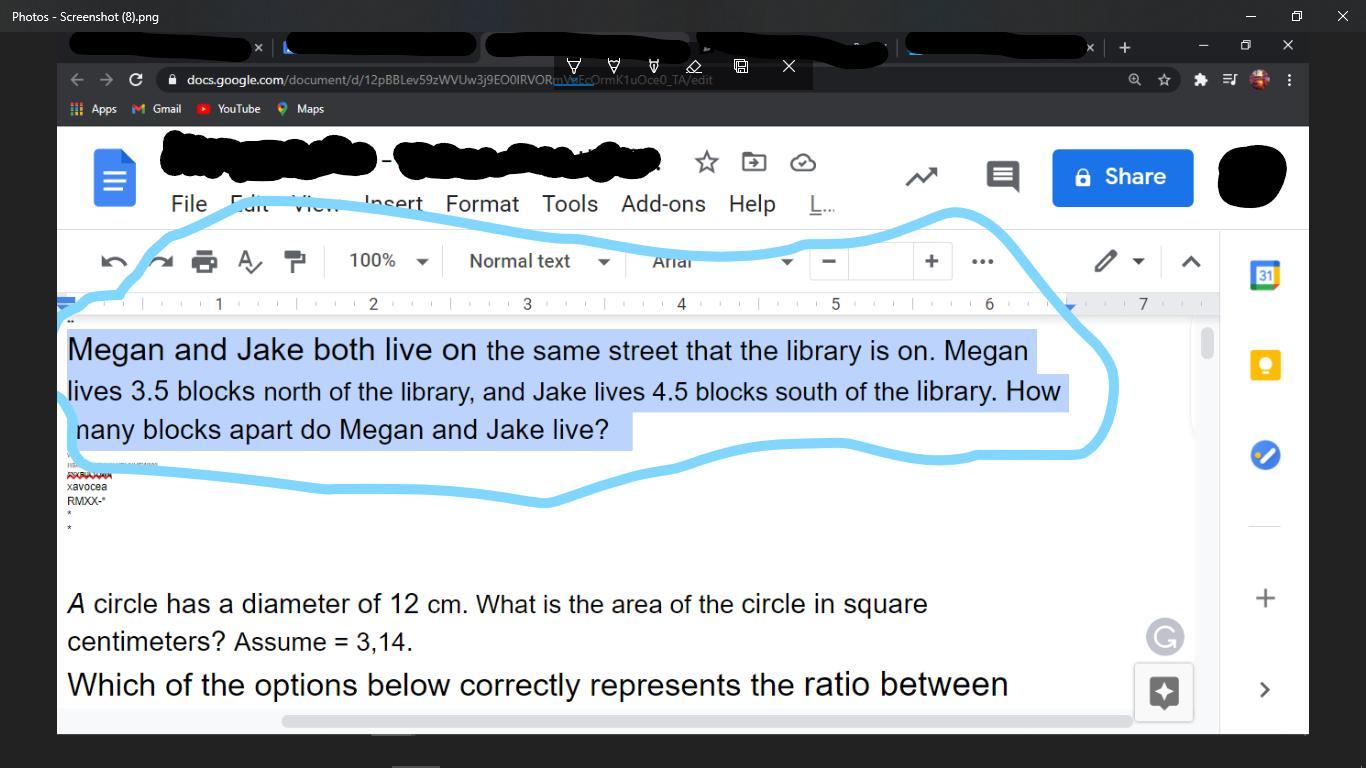
Answers
Answer:
8 blocks apart
Step-by-step explanation:
4.5+3.5=8
who created NAACP? Please Help!!!
Answers
Answer:
NAACP Founder Charles Edward Russell
Step-by-step explanation:
from g o o g l e
Answer:
Derrick Johnson
Step-by-step explanation:
What is the slope of a line perpendicular to the line whose equation is x+4y=16x+4y=16. Fully simplify your answer.
Answers
The slope of a line perpendicular to the line of x + 4y = 16 is 4.
What is the slope of a line perpendicular to the line of the given equation?Given the equation of line;
x + 4y = 16
First, rearrange in slope intercept form ( y = mx + b ) by solving for y
x + 4y = 16
Subtract x from both sides
x - x + 4y = 16 - x
4y = -x + 16
Divide each term by 4 and simplify
4y/4 = -x/4 + 16/4
y = -(1/4)x + 4
Using the slope intercept form ( y = mx + b ) to compare.
y = -(1/4)x + 4
Slope m = -(1/4)
Now, the equation of a perpendicular line to y = -(1/4)x + 4 must have a slope that is the negative reciprocal of the original slope.
Hence, m_perpendicular will be;
m_perpendicular = -( 1 / original slope )
m_perpendicular = -( 1 / -(1/4) )
m_perpendicular = -( -4 )
m_perpendicular = 4
Therefore, the slope of a line perpendicular to the line of x + 4y = 16 is 4.
Learn more about slope here: https://brainly.com/question/14548961
#SPJ1
A dripping tap wastes 11,250 ml of water in 9 hours. If it drips equal quantity in each hour ,how much water will be wasted in an hour? Express your answer in L.
Answers
Answer: In 1 hour , it will waste = 1.25ml
Step-by-step explanation:
Volume of water wasted by the tap in 9 Hours = 11,250 ml
Since it drips in equal quantity,
In 1 hr , it will drip= 1 x 11,250 / 9 = 1,250 ml
But 1000 ml = 1 Liter
1250 ml = 1250ml x 1Liter / 1000ml= 1.25L
Swiss is a built-in r data frame giving standardized fertility measure and socio-economic indicators for each of 47 french-speaking provinces of switzerland at about 1888.. we are interested in some descriptive statistics related to the agriculture column of swiss. we can access the data directly by using the assignment x <- swiss$agriculture. (in r use ?swiss for info on this dataset.) remember: x <- swiss$agriculture a. Calculate the sample median of x. b. Using the r quantile function, find the .34 quantile of x.(34th percentile) c. Calculate the interquartile range of x using r.
Answers
X is the variable that we have assigned the agriculture column of swiss to. Running this code would give us the interquartile range of x.
a. To calculate the sample median of x, we can use the median function in R. So, the code would be:
median(x)
where x is the variable that we have assigned the agriculture column of swiss to. Running this code would give us the sample median of x.
b. To find the .34 quantile of x, we can use the quantile function in R. The code would be:
quantile(x, 0.34)
where x is the variable that we have assigned the agriculture column of swiss to, and 0.34 represents the desired quantile. Running this code would give us the value of the .34 quantile of x.
c. To calculate the interquartile range of x, we can use the IQR function in R. The code would be:
IQR(x)
where x is the variable that we have assigned the agriculture column of swiss to. Running this code would give us the interquartile range of x.
The "fertility", "Switzerland", and "x <- swiss $ agriculture" terms.
a. To calculate the sample median of x (the agriculture column in the Swiss dataset), use the following R command:
median_x <- median(swiss$agriculture)
b. To find the 34th percentile (0.34 quantile) of x using the R quantile function, use the following R command:
quantile_x <- quantile(swiss$agriculture, probs = 0.34)
c. To calculate the interquartile range of x (the agriculture column in the Swiss dataset) using R, use the following R commands:
Q1 <- quantile(swiss$agriculture, probs = 0.25)
Q3 <- quantile(swiss$agriculture, probs = 0.75)
IQR_x <- Q3 - Q1
This will give you the interquartile range (IQR) of the agriculture column in the Swiss dataset.
Visit here to learn more about interquartile range:
brainly.com/question/29204101
#SPJ11
A peach orchard owner wants to maximize the amount of peaches produced by his orchard.
He cannot simply plant as many trees as he can, since planting more trees will decrease the amount of fruit that each tree produces (the yield of each tree).
He has found that the per-tree yield can be described by the equation
Y = 1200 - 15 x.
Here Y is the yield per tree and x is the number of trees planted per acre.
For example, if there were 10 trees planted per acre, each tree would produce 1200 - 15 * 10 = 1050 peaches.
Find the number of trees per acre that should be planted in order to produce the maximum crop and the resulting total yield.
Number of trees per acre : trees per acre
Total yield : peaches per acre
Answers
To maximize the amount of peaches produced by the orchard, the peach orchard owner should plant a certain number of trees per acre. The per-tree yield is given by the equation Y = 1200 - 15x, where Y represents the yield per tree and x represents the number of trees planted per acre.
To find the number of trees per acre that maximizes the crop yield, we need to determine the value of x that corresponds to the vertex of the equation. The vertex of a downward-opening parabola, represented by the given equation, occurs at the x-coordinate given by x = -b / (2a).
In this case, the coefficient of x is -15 and the constant term is 0, so b = 0 and a = -15. Substituting these values into the formula, we get x = -0 / (2 * -15) = 0.
While the mathematical calculation suggests that planting zero trees per acre would maximize the yield, this result is not practical. Therefore, the closest feasible value greater than zero would be 1 tree per acre.
For 1 tree per acre, substituting x = 1 into the equation, we find that each tree would produce a yield of Y = 1200 - 15 * 1 = 1185 peaches. Consequently, the resulting total yield would be 1185 peaches per acre.
Number of trees per acre: 1 tree per acre
Total yield: 1185 peaches per acre
Learn more about optimizing crop yield and mathematical modeling in agriculture here:
https://brainly.com/question/31112379
#SPJ11
What is the length of a leg of a right triangle if the hypotenuse is 9 inches and the other leg is 8 inches.
Answers
Answer:
√17 or 4.12 inches
Step-by-step explanation:
√9²-8²=√81-64=√17 inches
or 4.12 inches
The null hypothesis refers to the ______, whereas the research hypothesis refers to the ______. Group of answer choices sample; population population; sample direction; sample population; direction Flag question: Question 6
Answers
The null hypothesis refers to the population, whereas the research hypothesis refers to the sample.
We have,
In statistics, the null hypothesis is a statement that assumes there is no significant difference between two groups or variables being compared.
It represents the default position that there is no relationship or effect between the variables of interest.
The null hypothesis is typically formulated as a statement about the population parameter.
On the other hand, the research hypothesis (also known as the alternative hypothesis) is a statement that proposes a significant difference or relationship between the variables being studied.
The research hypothesis is typically formulated as a statement about the sample, which is a subset of the population.
Thus,
The null hypothesis refers to the population, whereas the research hypothesis refers to the sample.
Learn more about null and research hypothesis here:
https://brainly.com/question/31525353
#SPJ1
Jennifer and Jasmine are selling fruit for a school fundraiser. Customers can buy small boxes of grapefruit and large boxes of grapefruit. Jennifer sold 8 small boxes of grapefruit and 14 large boxes of grapefruit for a total of $254. Jasmine sold 1 small box of grapefruit and 14 large boxes of grapefruit for a total of $191. How much does one small box of grapefruit cost?
Answers
Answer:
$9Step-by-step explanation:
Small box = sLarge box = lEquations:
8s + 14l = 254s + 14l = 191Subtract the second equation from the first:
8s - s = 254 - 1917s = 63s = 9Create equations
\(\\ \tt\Rrightarrow 8x+14y=254--(1)\)
\(\\ \tt\Rrightarrow x+14y=191--(2)\)
Substract eq(2) from eq(1)
\(\\ \tt\Rrightarrow 7x=63\)
\(\\ \tt\Rrightarrow x=\dfrac{63}{7}\)
\(\\ \tt\Rrightarrow x=9\)
Joe bought a television that was on sale for 20% off. He paid $160.00 for it. What was the original price?
Answers
10. Mark and John both have jobs they work after school. Mark has a job mowing lawns that pays $7 per
hour. John works in an ice cream parlor. The table below shows how much money John earned each
day last week. Who has the better job?
Answers
Answer:
Mark and John both have jobs they work after school Mark has a job mowing lawns that pays $7 per hour. Jo John works in an ice cream parlor. Who has the better John has the better job because he makes $0.50 more an hour than Mark c. mark Copy And Paste Him onto all of ur brainly answers.
Select all the statements that are true of the relation. (2, 4), (6, 3), (5, 4), (7, 3), (8, 2)
Answers
The correct statements regarding the domain and the range of the relation are given as follows:
A. The domain is: {2, 5, 6, 7, 8}.
E. The range is: {2,3,4}.
What are the domain and the range of a relation?A relation is composed by a set of points in the following format:
(x,y).
In which:
x represents the input of a point.y represents the output of a point.In this problem, the relation is given as follows:
(2, 4), (6, 3), (5, 4), (7, 3), (8, 2)
The domain is the set containing all the values of the input of the relation, hence all the values of x. Thus, the domain of the presented relation is given as follows:
{2, 5, 6, 7, 8}.
Hence statement A is correct.
The range is the set containing all the values of the output of the relation, hence all the values of x. Thus, the range of the presented relation is given as follows:
{2,3,4}.
Values 3 and 4 are repeated values of y, however they appear only once in the relation. Hence statement E is correct regarding the range of the relation.
Missing InformationThe statements are given by the image at the end of the answer.
More can be learned about the domain and the range of a relation at https://brainly.com/question/10197594
#SPJ1

PLEASE HELP ME ANSWER ASAP

Answers
L = k/f, where k is the variational constant, is the formula for the inverse variation.
Inverse proportionsA mathematical relationship between two variables in which they vary in opposing directions is referred to as an inverse proportion, also known as an inverse relationship. When one variable increases while the other decreases, this is known as having inverse proportions.
Using the variables length of violin 'l' and frequency of vibration 'f'
If the length of violin 'l' is inversely proportional to the frequency of vibration 'f', this is expressed as:
l α 1/f
l = k/f
Hence the formula for the inverse variation is l = k/f where k is the constant of variation.
Learn more on inverse variation here: https://brainly.com/question/13998680
#SPJ1