
Answers
Answer:
y=(19+7)(2x6+1)
y=2
Step-by-step explanation:
Related Questions
calculate the surface area and then the volume

Answers
Answer:
46
Step-by-step explanation:
length x width x height
7 x 5 x 3
Answer: surface area = 142
Volume = 105
* make sure to add labels (units^2, etc.)
Step-by-step explanation:
Area = length x height
Volume = length x width x height
while logistic regression and classification and regression trees (cart) have the same end goal, each model approaches the goal in a different way. discuss the differences in the two models. provide a specific example of a situation where employing a cart model would be preferable to a logistic regression model. explain what makes the cart model superior in your example.
Answers
Logistic regression models the probability of a binary outcome, while CART models segment data into categories. For example, CART is preferable when data has complex interactions, as it can partition data into multiple categories.
Logistic regression and classification and regression trees (CART) are two different machine learning models used for binary classification problems. Logistic regression models the probability of one class or the other based on a linear combination of input variables. This makes it useful for predicting a binary outcome, such as whether a customer will purchase a product or not. On the other hand, CART is a decision tree model that divides data into categories. It uses a tree-like structure to split the data into segments based on the input features. This makes it useful for dealing with data with complex interactions, as it can partition data into multiple categories. For example, a CART model would be preferable to a logistic regression model if there are multiple underlying factors that affect the binary outcome. In this case, a CART model could more accurately identify the categories that are associated with a particular outcome. Overall, CART models are superior for dealing with data with complex interactions, whereas logistic regression is better for simpler data.
Learn more about probability here
https://brainly.com/question/11234923
#SPJ4
what is 351 substrate by 69
Answers
Answer:
282
Step-by-step explanation:
351-69
Find the H.C.F. of 567 and 255 using Euclid’s division lemma.
Answers
Step-by-step explanation:
To find the Highest Common Factor (H.C.F.) of 567 and 255 using Euclid's division lemma, we can follow these steps:
Step 1: Apply Euclid's division lemma:
Divide the larger number, 567, by the smaller number, 255, and find the remainder.
567 ÷ 255 = 2 remainder 57
Step 2: Apply Euclid's division lemma again:
Now, divide the previous divisor, 255, by the remainder, 57, and find the new remainder.
255 ÷ 57 = 4 remainder 27
Step 3: Repeat the process:
Next, divide the previous divisor, 57, by the remainder, 27, and find the new remainder.
57 ÷ 27 = 2 remainder 3
Step 4: Continue until we obtain a remainder of 0:
Now, divide the previous divisor, 27, by the remainder, 3, and find the new remainder.
27 ÷ 3 = 9 remainder 0
Since we have obtained a remainder of 0, the process ends here.
Step 5: The H.C.F. is the last non-zero remainder:
The H.C.F. of 567 and 255 is the last non-zero remainder obtained in the previous step, which is 3.
Therefore, the H.C.F. of 567 and 255 is 3.
To make a mixture that tastes the same as the original recipe, how much pineapple juice should you mix with 1 cup of orange juice?
Answers
Recipes 1 and 2 have the same proportion of orange juice to pineapple juice, whereas recipe 3 has a different proportion.
The recipes that would taste the same are recipe 1 and 2. Recipe 3 would taste different.
Recipe 1: ratio of orange juice to pineapple juice = 4 : 6
2 : 3
Recipe 2: ratio of orange juice to pineapple juice = 6 : 9
2: 3
Recipe 3: ratio of orange juice to pineapple juice = 9 : 12
3 : 4
Thus, Recipes 1 and 2 have the same proportion of orange juice to pineapple juice, whereas recipe 3 has a different proportion.
Learn more about Ratio here:
https://brainly.com/question/32531170
#SPJ4
The Complete Question is:
Here are three different recipes for Orangy-Pineapple juice. Two of these mixtures taste the same and one tastes different.
Recipe 1: Mix 4 cups of orange juice with 6 cups of pineapple juice.
Recipe 2: Mix 6 cups of orange juice with 9 cups of pineapple juice
Recipe 3: Mix 9 cups of orange juice with 12 cups of pineapple juice
Which two recipes will taste the same, and which one will taste different? explain or show your reasoning.
i need help with this please hurry!!!

Answers
So on solving the provided question, we can say that fraction we have are \(4\frac{2a}{3} + \frac{1a}{4} - \frac{1a}{a} (b - 7)\) = 14/6
what is fraction?Any number of equal portions, or fractions, can be used to represent a whole. Fractions in standard English indicate how many units of a certain size there are. 8, 3/4. A whole includes fractions. The ratio of the numerator to the denominator is how numbers are expressed in mathematics. Each of these is an integer in simple fractions. In the numerator or denominator of a complex fraction is a fraction. True fractions have numerators that are less than their denominators. A fraction is a sum that constitutes a portion of a total. By breaking the entire up into smaller bits, you can evaluate it. Half of a full number or item, for instance, is represented as 12.
here the fraction we have are
\(4\frac{2a}{3} + \frac{1a}{4} - \frac{1a}{a} (b - 7)\)
12/3 + 12/4 + 15/2
14/6
To know more about fraction visit:
https://brainly.com/question/10354322
#SPJ1
Bella has a credit score of 720. based on the graph, which description most likely explains her score? she pays her bills on time and has a higher amount of debt. she has a lot of debt with a history of making late payments. she pays her bills on time and has a lower amount of debt. she has a lot of money and tends to pay her bills on time.
Answers
Answer: The correct answer would be that she pays her bills on time and has a lower amount of debt because her credit score are 720 which is considered a good payment point.
Explanation: The correct answer would be that she pays her bills on time and has a lower amount of debt because her credit score is 720 which is considered a good payment point.
Explanation: Credit score is known as CIBIL. By this credit, score banks gauge the creditworthiness of a person. The data listed in our credit report CIBIL generate our credit score.
A person's credit history is submitted to CIBIL by banks and other financial institutions on a particular basis.
For example, if a person has a credit score of 600 then that person cannot be considered a good creditor. In this case, the bank doesn't lend him .
Please help due today
State if each triangle is acute, obtuse, or right

Answers
Answer:
Hi there :)
Step-by-step explanation:
From what I can see, 9. is a right triangle because of the right angle, 10. is an acute triangle, and 11. is another right triangle. Please let me know if you need further explanation.
Which equation matches the table?

Answers
An equation that matches the table include the following: y = x + 5.
How to determine an equation of this line?In Mathematics and Geometry, the point-slope form of a straight line can be calculated by using the following mathematical equation (formula):
y - y₁ = m(x - x₁)
Where:
m represent the slope.x and y represent the points.First of all, we would determine the slope of this line;
Slope (m) = (y₂ - y₁)/(x₂ - x₁)
Slope (m) = (6 - 5)/(1 - 0)
Slope (m) = 1/1
Slope (m) = 1.
At data point (0, 5) and a slope of 1/, a linear equation in slope-intercept form for this line can be calculated by using the point-slope form as follows:
y - y₁ = m(x - x₁)
y - 5 = 1(x - 0)
y - 5 = x
y = x + 5
Read more on point-slope here: brainly.com/question/24907633
#SPJ1
Here are a list of numbers.
51,38,48,36,39,40,39,47
a) Work out the range of the numbers in the list.
b) Work out the mediann of the numbers in the list

Answers
Step-by-step explanation:
easy by applying formula of range and median

Answer:
range: 15median: 39.5Step-by-step explanation:
The range of the data is the difference between the largest and smallest values. The median is the middle value, or the average of the two middle values.
a) RangeArranging the data from lowest to highest, we have ...
36, 38, 39, 39, 40, 47, 48, 51
The difference between the highest and lowest values is ...
range = 51 -36 = 15
The range of the data is 15.
b) MedianThe median of the data set is the middle value, or the average of the two middle values if the number of data values is even.
There are 8 members of the data set, so the median will be the average of the two middle values: 39 and 40.
median = (39 +40)/2 = 39.5
The median of the numbers on the list is 39.5.
A selection method is said to have utility when it 0 out of 1 points Which one of the following is the best example of a behavioral (or work sample) question? uestion 3 1 out of 1 points Artificial intelligence (AI) is sometimes used to analyze a candidate's psychological profile to whether it will fit Question 4 0 out of 1 points Laura applies for the position of ambulance medic. To give her a job simulation (behavioral interview) screening test, the interviewer
Answers
Question 4: Laura applies for the position of ambulance medic. To give her a job simulation (behavioral interview) screening test, the interviewer...
This question involves providing a job simulation or behavioral interview, which allows the interviewer to observe how the candidate performs in a simulated work situation. This type of question assesses the candidate's skills, abilities, and behavior in a real or simulated work scenario, providing a more accurate evaluation of their capabilities for the job.
Learn more about the behavioral interview here:
https://brainly.com/question/33363410
#SPJ11
what is the difference between slope and rate of change
Answers
The slope is the steepness of a line on a graph and represents the ratio of the vertical change to the horizontal change, the rate of change refers to the amount of change in one variable corresponding to a unit change in another variable.
The slope of a line is a measure of its steepness or incline. It is calculated by dividing the vertical change (change in y-values) by the horizontal change (change in x-values) between two points on the line. The slope indicates how much the dependent variable (y) changes with respect to a unit change in the independent variable (x). In other words, it represents the ratio of the rise (vertical change) to the run (horizontal change) on the graph.
On the other hand, the rate of change is a broader concept that applies to any relationship between two variables, not just linear relationships. It measures how one variable changes in response to a unit change in another variable. The rate of change can be positive, indicating an increase in one variable for every unit increase in the other variable, or negative, indicating a decrease. It can also vary across different intervals of the relationship, indicating that the relationship is not constant.
In summary, the slope specifically refers to the steepness of a line on a graph and is calculated as the ratio of the vertical change to the horizontal change. The rate of change, on the other hand, is a more general concept that describes how one variable changes in response to a unit change in another variable and can be applied to any type of relationship between variables.
Learn more about slope here:
https://brainly.com/question/2491620
#SPJ11
The following data are from a simple random sample. \[ 2,8,11,7,11 \] a. What is the point estimate of the population mean? b. What is the point estimate of the population standard deviation (to 1 dec
Answers
a. The point estimate of the population mean is 7.8.
b. The point estimate of the population standard deviation is 3.9 (to 1 decimal place).
In statistics, a point estimate is a single value that is used to estimate an unknown parameter of a population based on sample data. In this case, we are given a simple random sample with the following data points: 2, 8, 11, 7, and 11.
To find the point estimate of the population mean, we need to calculate the sample mean. The sample mean is obtained by summing up all the data points and dividing it by the number of observations. In this case, the sum of the data points is 2 + 8 + 11 + 7 + 11 = 39, and there are 5 observations.Therefore, the sample mean is 39/5 = 7.8. This means that, based on the given sample, we estimate the population mean to be 7.8.
To find the point estimate of the population standard deviation, we need to calculate the sample standard deviation. The sample standard deviation measures the variability or spread of the data points in the sample. It is calculated by taking the square root of the variance, which is the average of the squared deviations from the sample mean.First, we calculate the deviations from the sample mean for each data point: (-5.8), 0.2, 3.2, (-0.8), and 3.2. Squaring these deviations gives us: 33.64, 0.04, 10.24, 0.64, and 10.24.
Taking the average of these squared deviations gives us a variance of (33.64 + 0.04 + 10.24 + 0.64 + 10.24)/5 = 10.76. Finally, taking the square root of the variance, we find the sample standard deviation to be approximately 3.3 (rounded to 1 decimal place).
Therefore, the point estimate of the population standard deviation is 3.9 (to 1 decimal place).
Learn more about Standard deviation
brainly.com/question/13498201
#SPJ11
Recall the following 10 vector space axioms we learned for vector u, u and w in V: u+veV. u+v=v+u. . (u+v)+w=u+ (v+w). • V has a zero vector such that for all u in V, v+0=0. • For every u in V, there exists-u in V such that u +(-u) = 0. cu is V for scalar c. c(u+v)=cu+cu. (c+d)u-cu+du. (cd)u=c(du). 1.u u for scalar 1. Determine whether the set, together with the standard operations, is a vector space. If it is not, identify at least one of the ten vector space axioms that fails. (a) The set of all polynomials of degree exactly three, that is the set of all polynomials p(x) of the form, p(x) = ao + a₁ + a₂z² +3³,3 0 (b) The set of all first-degree polynomial functions ax, a 0, whose graphs pass through the origin.
Answers
The given set, together with the standard operations, is not a vector space.
Given that we need to determine whether the set, together with the standard operations, is a vector space or not. If it is not, we have to identify at least one of the ten vector space axioms that fails. (a) The set of all polynomials of degree exactly three, that is the set of all polynomials p(x) of the form,\(p(x) = ao + a₁ + a₂z^2 +3^3\)
,3 0Given set is a vector space.The given set is a vector space because it satisfies all the ten vector space axioms. Hence, the given set, together with the standard operations, is a vector space. (b) The set of all first-degree polynomial functions ax, a 0, whose graphs pass through the originGiven set is not a vector space.The given set is not a vector space because it does not satisfy the fourth vector space axiom, i.e., V has a zero vector such that for all u in V, v+0=0.
Therefore, the given set, together with the standard operations, is not a vector space.
Learn more about vector space here:
https://brainly.com/question/30531953
#SPJ11
How do you graph a logarithmic curve?
Answers
Logarithmic Functions
In mathematics, the logarithmic function is an inverse function to exponentiation
Domain and range of logarithmic functions
We know that is defined only when >0. So the domain is the set of all positive real numbers. We can see that can be either a positive or negative real number (or) it can be zero as well. Thus, can take the value of any real number.
Note:
The domain of function = is >0 (or) (0,∞).
The range of any log function is the set of all real numbers ().
Logarithmic graph
We know that exponentials and functions are inversely proportional to each other, and so their graphs are symmetric concerning the line =. Also, note that =0 when =0 as =(1)=0 for any . Thus, all such functions have an -intercept of (1,0). A logarithmic function doesn’t have a -intercept as 0 is not defined.
Properties of logarithmic graph
>0 and ≠1.
The logarithmic graph increases when >1 and decreases when 0<<1.
The domain is obtained by setting the argument of the function greater than 0.
The range is the set of all real numbers.
Graphing logarithmic functions
Before plotting the log function, just have an idea of whether you get an increasing curve or decreasing curve as the answer. If the >1 then the curve is increasing, and if 0<<1, then the curve is decreasing.
Here are the steps for graphing logarithmic functions:
Find the domain and range.
Find the vertical asymptote by setting the argument equal to 0. Note that a function doesn’t have any horizontal asymptote.
Substitute some value that makes the argument equal to 1 and use the property (1)=0. This gives us the -intercept.
Substitute some value that makes the argument equal to the base and use the property ()=1 This would give us a point on the graph.
Connect the two points (from the last two steps) and extend the curve on both sides relative to the vertical asymptote.
To learn more about the logarithmic graphs, refer to the link:brainly.com/question/28145606
#SPJ4
Solve for x. 91=29^x
Round to the nearest hundredths.
Answers
The solution to the equation 91 = 29^x is approximately x ≈ 1.08.
To solve for x in equation 91 = 29^x, we need to isolate the variable x. Here's the step-by-step process:
Add 150 to both sides of the equation to get rid of the constant term:
91 + 150 = 29^x + 150
Simplify the equation:
241 = 29^x + 150
Subtract 150 from both sides:
241 - 150 = 29^x
Simplify further:
91 = 29^x
Now, we can solve for x by taking the logarithm of both sides of the equation with base 29. Using the logarithm property log_b(a^c) = c * log_b(a), we have:
log_29(91) = x
Using a calculator or logarithm table, we can find that log_29(91) ≈ 1.08.
Therefore, the solution to the equation 91 = 29^x is approximately x ≈ 1.08.
To learn more about equation
https://brainly.com/question/29174899
#SPJ8
Quick Fix Inc. repairs bikes. The company’s revenue is modeled by the function R(h)=220h-160 for the every h hours spent repairing bikes. The company’s overhead cost is modeled by the function C(h)=20h^2-400.
After how many hours does the company break even?
Answers
Answer:
7
Step-by-step explanation:
3+4
Please I NEED HELP AS SOON AS POSSIBLE! Two students were given the same problem of 2x - 4 = 6 to solve . Student A got an answer of x = 5 and Student B got an answer of x = 7 7. Which student is correct and what mistake did the other student make when solving for x? Explain your answer and refer to the work (below) that each student showed for their solution .

Answers
Answer:
Student A is correct and student B made the mistake
Step-by-step explanation:
Student B divided 2 on both sides before subtracting four, when they should've done it the other way around: add four on both sides and then divide by 2 to solve for x
determine the number of solutions of the system y=-x-13x^2+2y=4
Answers
we can replace y on the second equation to find x
\(\begin{gathered} 3x^2+2(x-1)=4 \\ 3x^2+2x-2=4 \\ 3x^2+2x-6=0 \end{gathered}\)to find X we need to use this formula to factor
\(x=\frac{-b\pm\sqrt[]{b^2-4ac}}{2a}\)where a=3, b=2 and c=-6
so, replace
\(\begin{gathered} x=\frac{-(2)\pm\sqrt[]{(2)^2-4(3)(-6)}}{2(3)} \\ \\ x=\frac{-2\pm\sqrt[]{4+72}}{6} \\ \\ x=\frac{-2\pm\sqrt[]{76}}{6} \\ \\ x=\frac{-1\pm\sqrt[]{19}}{3} \end{gathered}\)we have 2 solutions for x
\(undefined\)Estimate the number of square yards of carpeting needed to cover a floor 10'3" by 15'9.
Answers
Answer:
17.9375 square yards
Step-by-step explanation:
Let us have a common unit
What we have here is the case of inches and ft
10 ft 3 inches
1 ft = 12 inches
so 3 inches is 3/12 = 0.25 ft
= 10+0.25 = 10.25 ft
15 ft 9 in
= 15 + 9/12 = 0.75 + 15 = 15.75 ft
So let us convert to yards ;
Mathematically, 3 ft = 1 yard
so 10.25 ft = 10.25/3 = 3.4167 yards
15.75 ft = 15.75/3 =5.25 yards
So the square yards would be the product of this two;
which is;
(10.25/3) * (15.75/3) = 17.9375 square yards
Please help me I really need it this is due ASAP I will give you 16 points

Answers
No, the coordinates can not be the solution to find the answer. I know this because to find a slope-intercept equation you would need to have 2 coordinates. You would need 2 coordinates to first find the slope of the equation (m) in the equation y=mx+b.
9=1/4(12)+6 which is true
amanda and jamie are standing 25 feet apart and spot a bird in the sky between them. the angle of elevation from amanda to the bird is 55 degrees, and from jamie to the bird is 63 degrees, how far away is the bird quizzizz
Answers
The bird is 25.23 feet away from Amanda and Jamie.
Given that:
Point A is Amanda's Position.
Point B is Jamie's position.
and Point C is Bird's position.
Thus,
C is the standing of Amanda and Jamie.
So, A = 55°
B = 63°
and C = 25 feet.
Since, the sum of the angle measure of a Triangle.
Therefore,
A +B +C = 180°
⇒ 55° + 63° +C = 180°
⇒ 118° + C = 180°
⇒ C = 62°
Now,
By the Law of Sines:
\(\frac{Sin\beta }{b} = \frac{Sin\alpha }{c}\)
⇒ C sin β = b sinα
⇒ b = c sinβ/ sinα
⇒ b = 25.23
Learn more about Feet:
https://brainly.com/question/18155565
#SPJ4
In a company, 80% of the workers are men. If 780 people work for the company who aren't men, how many workers are there in all? Use pencil and paper. Show two different ways that you can solve this problem.
There are [enter your response here] workers in all.
Answers
Answer:
3900
Step-by-step explanation:
20%=1/5
780 is 20%
780x5 equals total since 20% 80% is 3120
3. If the distance between P(-2, 3a - 4) and Q(-2, 5a - 2) is 12 units, find the possible values of a.
Answers
Answer:
a=5
Step-by-step explanation:
2a+2=12
2a=10
a=5
show all your work?
and please help me out ASAP!!

Answers
Question 12
A tree is standing next to a 40 foot high building. The tree has an 18 foot shadow, while the building has a 16 foot shadow. How tall is the tree rounded to the nearest foot?
А
42 feet
B
36 feet
c
45 feet
D
7 feet
2021 Illuminate Education Inc
Answers
Answer:
A
Step-by-step explanation:
Your peers always get to the playground first and take all of the balls. It takes you longer to put on your clothes, so you always miss the first part of recess. Sometimes they tease you when you finally arrive. Who and how can you ask for help with this problem?
Answers
Answer:
Talk to a teacher
Step-by-step explanation:
9686584 !jdnd
the answers options.
1. -2
2. -1/2
3. 1/2
4. 2
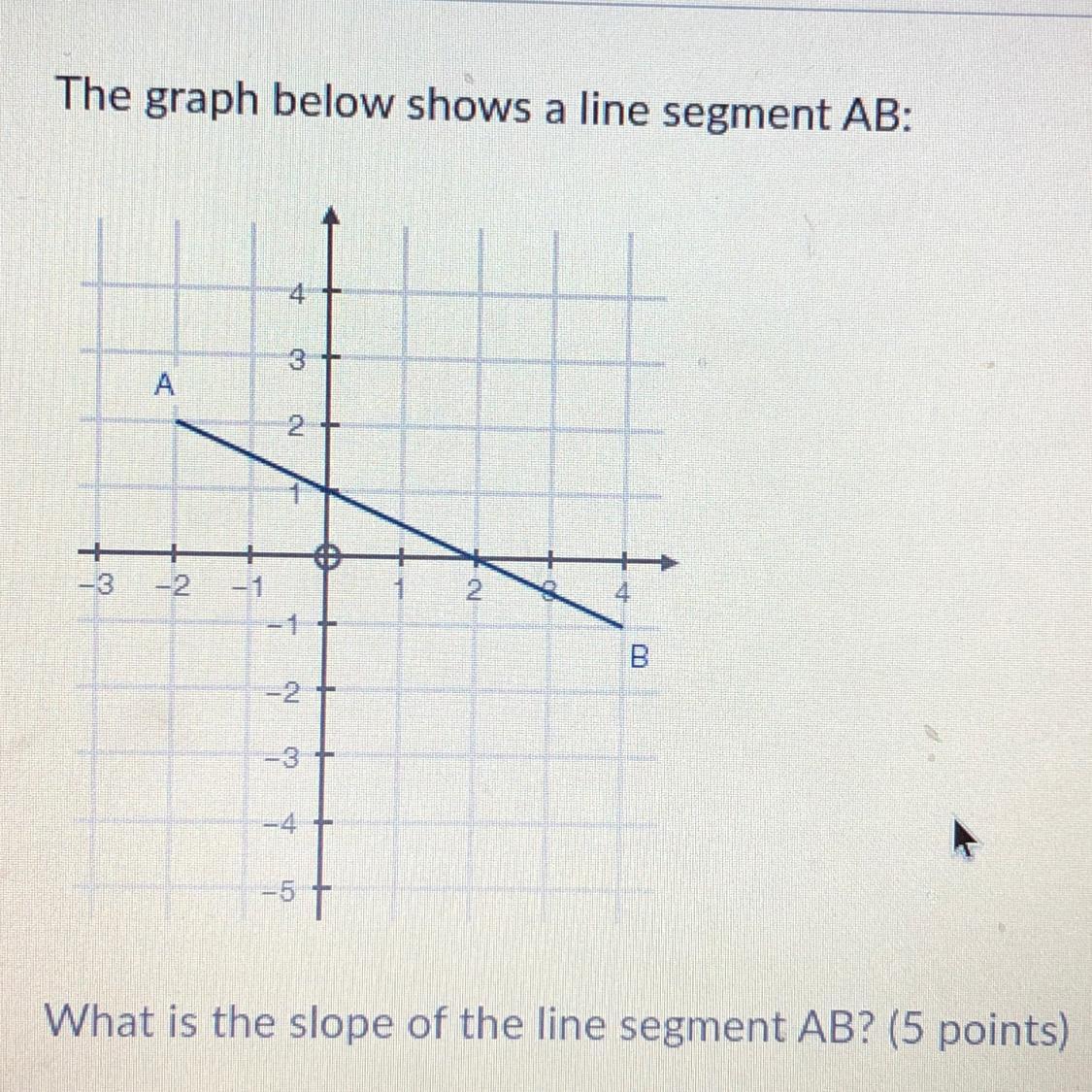
Answers
Answer:
2. -1/2
Step-by-step explanation:
it goes down 1 over 2
What would be the opportunity cost of spending $90,000 on advertising but only producing 12,000 units? Potential sales (before advertising) of 12,000 units, Price of $16, Fixed costs of $48,000, Variable costs $8, Advertising $90,000 Assume advertising multiplier is (30,000+ advertising)/30,000
$76,800
$576,000
$192,000
−$191,936
$768,000
Answers
The opportunity cost of spending $90,000 on advertising but only producing 12,000 units can be calculated by comparing the benefits of the advertising investment to the potential alternative uses of that money.
First, let's calculate the total cost of producing 12,000 units. Fixed costs amount to $48,000, and variable costs are $8 per unit, resulting in a total cost of $48,000 + ($8 × 12,000) = $144,000.
Next, we need to calculate the potential sales revenue without advertising. With a price of $16 per unit, the potential sales revenue would be $16 × 12,000 = $192,000.
Now, let's calculate the potential sales revenue after advertising. The advertising multiplier is given as (30,000 + advertising) / 30,000. In this case, the multiplier would be (30,000 + 90,000) / 30,000 = 4.
Therefore, the potential sales revenue after advertising would be $192,000 × 4 = $768,000.
The opportunity cost is the difference between the potential sales revenue after advertising ($768,000) and the potential sales revenue without advertising ($192,000), which is $768,000 - $192,000 = $576,000.
To know more about calculated , visit ;
https://brainly.in/question/2221194
#SPJ11
a high school offers math placement exams for incoming freshmen to place students into the appropriate math class during their freshman year. three different middle schools were sampled and the following pass/fail results were found. run a test for independence at the 0.10 level of significance. school a school b school c pass 40 33 50 fail 59 45 67 after running an independence test, can it be concluded that pass/fail rates are dependent on school? question 14 options: yes, it can be concluded that pass/fail rates are dependent on school because the p-value
Answers
The correct answer to the given question is "Yes, it can be concluded that pass/fail rates are dependent on school because the p-value is less than the level of significance".
The test for independence is used to determine whether or not two categorical variables are dependent or independent.
Here, the chi-square test of independence will be used to determine whether or not the pass/fail rates are dependent on the school.
The following are the steps to perform a chi-square test of independence:
1. State null and alternative hypotheses. The null hypothesis is that there is no significant relationship between the pass/fail rate and the school, whereas the alternative hypothesis is that there is a significant relationship between the pass/fail rate and the school. H0: The pass/fail rate is independent of the school. Ha: The pass/fail rate is dependent on the school.
2. Decide the level of significance (alpha) and the degrees of freedom (df). The level of significance is given as 0.10. The degrees of freedom are calculated using the formula: df = (r - 1) (c - 1) where r = number of rows and c = number of columns. Here, r = 2 and c = 3. Therefore, df = (2 - 1) (3 - 1) = 2.
3. Compute the expected frequencies. The expected frequency for each cell is calculated using the formula: (row total x column total)/grand total. The total for each row and column, as well as the grand total, are given in the table below:
School A School B School C Total Pass 40 33 50 123 Fail 59 45 67 171 Total 99 78 117 294The expected frequency for the top-left cell (pass and school A) is (123 x 99)/294 = 41.4
4. Similarly, the expected frequency for the top-right cell (pass and school B) is (123 x 78)/294 = 32.56, and so on.
The chi-square statistic is calculated using the formula:
χ2 = Σ[(O - E)2/E],
where O = observed frequency and E = expected frequency.
The value of χ2 is calculated as follows:
χ2 = [(40 - 41.44)2/41.44] + [(33 - 32.56)2/32.56] + [(50 - 49.00)2/49.00] + [(59 - 57.56)2/57.56] + [(45 - 45.44)2/45.44] + [(67 - 68.00)2/68.00]
χ2 = 0.054 + 0.036 + 0.020 + 0.029 + 0.013 + 0.007
χ2 = 0.1595.5.
Determine the critical value and p-value.
The critical value of χ2 for df = 2 and alpha = 0.10 is 4.605. The p-value is the probability of getting a chi-square statistic as large as or larger than the calculated value (0.159) if the null hypothesis is true.
This probability is obtained from a chi-square distribution table with df = 2. The p-value is less than the level of significance, and the chi-square statistic is less than the critical value.
Make a decision. Since the chi-square statistic (0.159) is less than the critical value (4.605) and the p-value is less than the level of significance (0.10), we reject the null hypothesis.
Therefore, it can be concluded that the pass/fail rates are dependent on school.
To know more about hypothesis refer to-
brainly.com/question/29519577#
#SPJ11