10.let's multiply
a)85×56
Answers
The product of 85 and 56 is given as follows:
85 x 56 = 4760.
How to obtain the product between two amounts?The product between two amounts is obtained as the multiplication between these two amounts.
The amounts for this problem are given as follows:
85 and 56.
We have two two-digit amounts, hence we use these following partial products:
85 x 6 = 510.85 x 5 = 425.The second partial product must be multiplied by the 2 - 1 = 1st power of 10, then we add the partial products to obtain the final product as follows:
510 + 4250 = 4760.
More can be learned about the product between two amounts at https://brainly.com/question/10873737
#SPJ1
Related Questions
The area of the entire figure below is 1 square unit.
What is the area of the stripped rectangle??

Answers
1/5 x 2 = 2/5
1/4 x 3 = 3/4
2/5 x 3/4 = 3/10
In a random sample of 200 school district residents, 94 stated they are in favor of starting the school day 15 minutes later each day. Calculate a 90% confidence interval for the true proportion of district residents who are in favor of starting the day later
Answers
The 90% confidence interval for the proportion of district residents in favor of starting the school day 15 minutes later is (0.392, 0.548). The true proportion is estimated to lie within this interval with 90% confidence.
To calculate the 90% confidence interval for the true proportion of district residents who are in favor of starting the school day 15 minutes later, we can use the following formula:
CI = p ± z*(√(p*(1-p)/n))
where:
CI: confidence interval
p: proportion of residents in favor of starting the day later
z: z- score based on the confidence level (90% in this case)
n: sample size
First, we need to calculate the sample proportion:
p = 94/200 = 0.47
Next, we need to find the z- score corresponding to the 90% confidence level. Since we want a two-tailed test, we need to find the z- score that cuts off 5% of the area in each tail of the standard normal distribution. Using a z-table, we find that the z- score is 1.645.
Substituting the values into the formula, we get:
CI = 0.47 ± 1.645*(√(0.47*(1-0.47)/200))
Simplifying this expression gives:
CI = 0.47 ± 0.078
Therefore, the 90% confidence interval for the true proportion of district residents who are in favor of starting the school day 15 minutes later is (0.392, 0.548). We can be 90% confident that the true proportion lies within this interval.
Learn more about the confidence interval here: brainly.com/question/24131141
#SPJ4
Interpreting Expressions
Breanna thought of a number, added 5 to it, and then multiplied her answer by 3. She got a final number of 21. What was her starting number?
Answers
2+5 = 7
7x3 = 21
Answer:
r u going to be a little late to the party but I
isaac's favorite cereal is running a promotion that says 111-in-444 boxes of the cereal contains a prize. suppose that isaac is going to buy 666 boxes of this cereal, and let xxx represent the number of prizes he wins in these boxes. assume that these boxes represent a random sample, and assume that prizes are independent between boxes. what is the probability that he wins exactly 222 prizes in the 666 boxes? you may round your answer to the nearest hundredth.
Answers
Using the binomial distribution, there is a 0.6328 = 63.28% probability that she wins at most 1 prize.
For each box, there are only two possible outcomes, either it has a prize, or it does not. The probability of a box having a prize is independent of any other box, hence, the binomial distribution is used to solve this question.
Binomial probability distribution
The parameters are:
x is the number of successes.
n is the number of trials.
p is the probability of a success on a single trial.
In this problem:
She buys 5 boxes, hence
1 in 4 boxes has a prize, hence
The probability is:
P ( X ≤ 1 ) =P ( X = 0 ) + P ( X = 1 )
Then ,
P ( X ≤ 1 ) = P ( X = 0 ) + P ( X = 1 )
= 0.2373 + 0.3955
= 0.6328
Thus 0.6328 = 63.28% probability that she wins at most 1 prize
To know more about binomial distribution you may go through the link which is mentioned below:
https://brainly.com/question/14565246
#SPJ1
A data set consists of 10 values: 9, 6, 2, 0, 2, 3, 5, 2, 1, 5. Determine the mean. Purchasing agent Angela Rodriguez reported the number of sales calls she received from suppliers on each of the past 14 days. Compute the variance for her daily calls during the 14-day period. Treat the data as a sample Number of calls and the number of days Calls (x) Number of days f(x) 4 1 5 3 6 4 7 4 8 2 The relative frequency table below shows the closing share price changes for the 100 most actively traded SP500 stocks. Use the grouped data table to approximate the mean for the data represented. SP500 price changes, interval midpoints and proportion of stocks Price Change Interval Midpoint Proportion of Stocks -1.00 to under -.60 -0.80 0.03 -.60 to under -.20 -0.40 0.03 -.20 to under .20 0.00 0.2 .20 to under .60 0.40 0.44 .60 to under 1.00 0.80 0.16 1.00 to under 1.40 1.20 0.06 1.40 to under 1.80 1.60 0.05 1.80 to under 2.20 2.00 0.03
Answers
The mean of the given data set is 3.5, the variance is 5.056, and the approximate mean using the grouped data table is 0.428.
The average of a set of values is referred to as the mean. To calculate the mean of a dataset, add up all of the values and divide by the number of values.
We can calculate the mean of the given data set as follows:
Mean = (9 + 6 + 2 + 0 + 2 + 3 + 5 + 2 + 1 + 5)/10
Mean = 3.5
Variance:Variance is a measure of how much a set of data varies. In other words, variance tells us how far each value in the dataset is from the mean. The variance formula is as follows:
σ² = (Σ(x - μ)²) / N
Where σ² is the variance, Σ is the sum, x is each value in the data set, μ is the mean of the data set, and N is the number of values in the data set.
Using the above formula, we can calculate the variance for the given data as follows:
First, we need to calculate the mean of the data set.x f(x)
xf(x)4 1 45 3 15 6 4 24 7 4 28 8 2 16
Total 14 128
Mean (μ) = 128 / 14 = 9.14
σ² = (Σ(x - μ)²) / N
σ² = [1(4 - 9.14)² + 3(5 - 9.14)² + 4(6 - 9.14)² + 4(7 - 9.14)² + 2(8 - 9.14)²] / 14
σ² = 5.056
Approximating the Mean:
We can use the midpoint of each interval as an approximate value for the entire interval. We can calculate the approximate mean as follows:
Mean = Σ(midpoint × proportion of stocks)
Mean = (-0.80 × 0.03) + (-0.40 × 0.03) + (0.00 × 0.2) + (0.40 × 0.44) + (0.80 × 0.16) + (1.20 × 0.06) + (1.60 × 0.05) + (2.00 × 0.03)
Mean = 0.428
Therefore, the mean of the given data set is 3.5, the variance is 5.056, and the approximate mean using the grouped data table is 0.428.
To know more about variance visit:
brainly.com/question/29253308
#SPJ11
What is the solution for x if

Answers
Answer: the answer is B which is x < -1
Step-by-step explanation: trust me bro and happy holidays :)
Answer:
\(\huge\boxed{B)\ x<-1}\)
Step-by-step explanation:
Solve this inequality the same way you would solve an equation: by isolating x.
Simply subtract 6 from both sides to get -4x > 4. Then merely divide both sides by -4 to get x < -1. (Notice that when dividing by a negative number, you must flip the sign of the inequality.)
Hope it helps :)
assuming the population trend continued in the same manner, what would be a reasonable estimation for what the population of the united states was in 2010?
Answers
By using previous years' population data and calculating the annual growth rate, we can estimate the population of the United States in 2010, assuming the population trend continued in the same manner.
To estimate the population of the United States in 2010, we can use the population growth trend from previous years. Here's a step-by-step explanation:
1. Collect population data: Find the population of the United States in previous years, preferably as close to 2010 as possible. For example, we can use the population data from 2000 and 2005.
2. Calculate the annual growth rate: Subtract the population in 2000 from the population in 2005, and divide the result by the population in 2000. Then, divide the result by the number of years between the two data points (5 years in this case) to get the average annual growth rate.
3. Apply the growth rate to the 2005 population: Multiply the population in 2005 by the annual growth rate, and then add the result to the 2005 population to get an estimate of the population in 2006. Repeat this process for each subsequent year until you reach 2010.
4. The estimated population in 2010: The result of step 3 for the year 2010 will be the reasonable estimation of the population in 2010, assuming the population trend continued in the same manner.
Learn more about population growth here:
brainly.com/question/18415071
#SPJ11
All of the following are measures of central tendency except the ________.
Select one:
A. None of the answers are correct
B. mode
C. range
D. mean
E. median
Answers
All of the following are measures of central tendency except the range.
The range is a measure of dispersion, representing the difference between the largest and smallest values in a dataset. It provides information about the spread or variability of the data but does not provide information about the central tendency.
On the other hand, measures of central tendency are statistical measures that aim to summarize the center or typical value of a dataset. They include the mode, median, and mean.
The mode represents the most frequently occurring value(s) in the dataset.
The median is the middle value when the data is arranged in ascending or descending order. It divides the dataset into two equal halves.
The mean is the arithmetic average of all the values in the dataset. It is calculated by summing all the values and dividing by the total number of values.
Therefore, option C, range, is not a measure of central tendency as it focuses on the spread or dispersion of the data rather than summarizing the central or typical value.
Learn more about central tendency from
https://brainly.com/question/1288901
#SPJ11
Select the desi answer for the question
1. Complete the following equation using <, >, or=
120%_1
O B. =
OC.
Mark is review (Will be highlighted on the review page)
Answers
Answer:
>
Step-by-step explanation:
You know that 100% = 1, so ...
120% > 1
the student decides to eliminate the unknown m2 . which two of the equations can be used to eliminate m2 ?
Answers
The equations that can be used to eliminate m₂ are 1. m₂ = 3m₁ and 4. m₂g - T=m₂a₂
How to determine the equations that can be used to eliminate m₂?From the question, we have the following parameters that can be used in our computation:
1. m₂ = 3m₁
2. --m₁g cosθ + T= m₁a₁
3. a₁ = a₂
4. m₂g - T=m₂a₂
To eliminate m₂, the equation to use must have a term or factor that has m₂
using the above as a guide, we have the following:
1. m₂ = 3m₁ and 4. m₂g - T=m₂a₂
Hence, the equations are 1. m₂ = 3m₁ and 4. m₂g - T=m₂a₂
Read more about equations at
https://brainly.com/question/148035
#SPJ4
Question
A physics student solving a physics problem has obtained the following four equations that describe the physics of a system of masses connected:
1. m2 = 3m1
2. --mig cosθ + T= miai
3. a1 = a2
4. m2g-T=m2a2
The student decides to eliminate the unknown m2. Which two of the equations can be used to eliminate m2?
what is the sum 0 of -1
Answers
Answer:
If you mean 0 + (-1) then it's -1
on average a customer waits 10 minutes in a queue and customers arrive at the rate of two per minute. how many customers are waiting in the queue on average
Answers
The average number of customers waiting in the queue is 20
In this question, we have been given that the customers arrive at the rate of two per minute.
On average a customer waits 10 minutes in a queue.
We need to find the number of customers waiting in the queue on average.
Assume that the average number of customers waiting in the queue is N.
We have the average Rate of Arrival = 2 customers per minute
So, by the formula for average waiting time under the Single-Server Queue Model,
10 = N/2
N = 10 * 2
N = 20
The average number of customers waiting according to the single-server queue model given the above conditions is 20
Learn more about the average here:
https://brainly.com/question/2906096
#SPJ4
What is the perimeter of the triangle

Answers
The answer is D. 2a²+ab+a.
What is perimeter of a triangle?
The perimeter of a triangle is the sum of the lengths of its sides.
The perimeter of the triangle with sides a²-ab, a-2a², and a²+2ab is:
Perimeter = (a² - ab) + (a - 2a²) + (a + 2ab)
Simplifying and combining like terms, we get:
Perimeter = 2a² - ab + a + 2ab
Perimeter = 2a² + a + ab
Perimeter = a(2a + 1 + b)
Therefore, the perimeter of the triangle is a(2a + 1 + b). The answer is D. 2a²+ab+a.
To know more about perimeter of a triangle visit,
https://brainly.com/question/24382052
#SPJ1
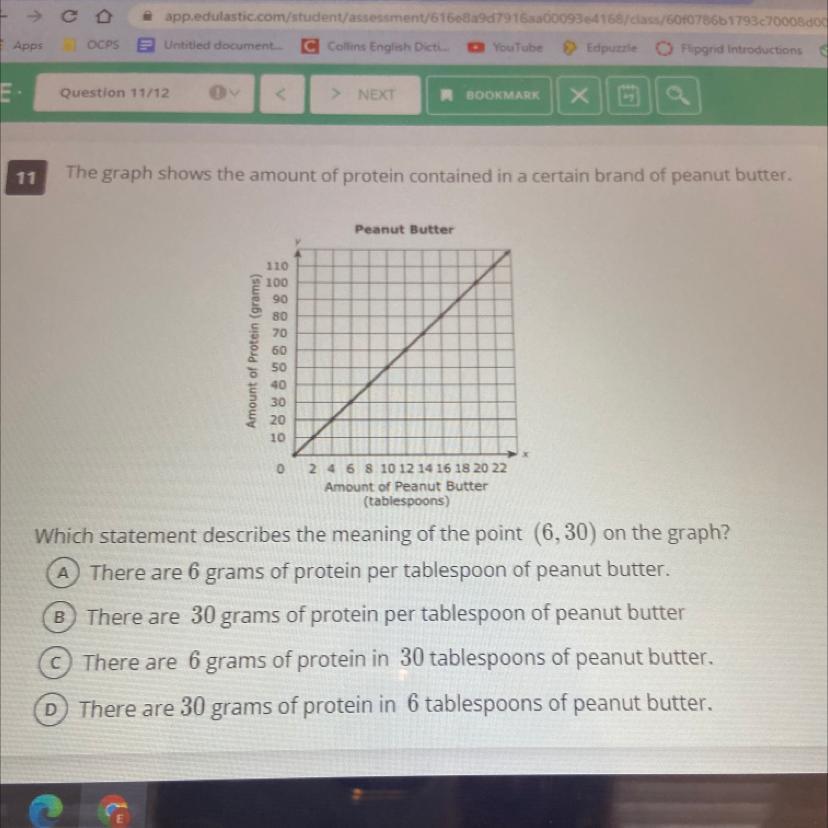
Which statement describes the meaning of the point (6,30) on the graph ?
Answers
Find a formula for the exponential function passing through thepoints (-1, 2/5 ) and (3,250)
Answers
The exponential function between (-1, 2/5) and (3, 250) is as follows:
\(f(x) = 2 * 5^x\)
By combining the fourth roots from both sides, we arrive at:
b = 5
When we use the expression we discovered for a and this value of b, we get:
a = (2/5) * 5 = 2
As a result, the exponential function between (-1, 2/5) and (3, 250) is as follows:
\(f(x) = 2 * 5^x\)
what are functions?A relation between a collection of inputs and outputs is known as a function. A function is, to put it simply, a relationship between inputs in which each input is connected to precisely one output. Each function has a range, codomain, and domain. The usual way to refer to a function is as f(x), where x is the input. A function is typically represented as y = f. (x).
In mathematics, a function is a unique arrangement of the inputs (also referred to as the domain) and their outputs (sometimes referred to as the codomain), where each input has exactly one output and the output can be linked to its input.
from the question:
This is the shape of the exponential function:
f(x) = a *\(b^x\)
where a represents the starting point and b represents the exponential function's base.
We must solve the system of equations to determine the values of a and b that meet the requirements:
a * \(b^(-1)\) = 2/5 (equation 1)
a *\(b^3\)= 250 (equation 2)
We can solve for an in equation 1 by multiplying both sides by b:
a = (2/5) * b
Substituting this expression into equation 2, we get:
(2/5) * b *\(b^3\) = 250
Simplifying, we get:
\(b^4 = 3125\)
By combining the fourth roots from both sides, we arrive at:
b = 5
When we use the expression we discovered for a and this value of b, we get:
a = (2/5) * 5 = 2
As a result, the exponential function between (-1, 2/5) and (3, 250) is as follows:
\(f(x) = 2 * 5^x\)
to know more about functions visit:
https://brainly.com/question/12431044
#SPJ1
A robot’s height is 3 meters 40 centimeters. How tall is the robot in millimeters?
Answers
Answer:
3400
Step-by-step explanation:
if you add it all up in cm, which is 340cm then divide by 10 you get 3400.
You can infer causality from a correlational result, but only when the r value is greater than____a. 0 b. 0.5 c. 1
Answers
You can infer causality from a correlational result, but only when the r value is greater than b. 0.5
A correlation coefficient, generally denoted by the symbol "r," is a metric that evaluates the degree and direction of a linear relationship between two variables. r has a value between -1 and 1, with -1 indicating a strong negative correlation, +1 indicating a high positive correlation, and 0 indicating no connection.
A correlation value of 0.5 or above is regarded moderate or strong, and it might indicate that a causal link exists between the two variables. It is crucial to remember, however, that correlation does not imply causation, and that other factors such as confounding variables, spurious correlations, or reverse causality may be contributing to the apparent association.
For more such questions on correlation , click on:
https://brainly.com/question/27842223
#SPJ4
What is the answer to this math problem; 12 5/6x-14x+ 1/6x
Answers
Answer: wyd are you mad at me
Answer: Who are
Step-by-step explanation:
how are the triangles congruent ?
AAS , AA , ASA , SAS , or Not enough information

Answers
I have the answer. The answer is AAS
Enter an inequality that represents the graph in the box.
Graph of a linear inequality on a coordinate plane. The horizontal x-axis ranges from negative 8 to 8 in increments of 2. The vertical y-axis ranges from negative 8 to 8 in increments of 2. A dashed line passes through begin ordered pair 0 comma 6 end ordered pair and begin ordered pair 2 comma 0 end ordered pair. The region above the dashed line is shaded.
Answers
Answer:
i think it is 80 i might be wrong
Step-by-step explanation:
Answer:
y > -3x + 6
Step-by-step explanation:
The answer for sure is y > -3x +6
if the area under the standard normal curve to the left of z=1.72 is 0.0427, then what is the area under the standard normal curve to the right of z=1.72?
A. 0.9573 B. 0.4573 c. 0.7642 D. 0.04217
Answers
The total area under the standard normal curve to the right of z=1.72 is equal to 0.9573. Therefore. the correct option is option A. 0.9573.
To find the area under the standard normal curve to the right of z=1.72, you need to subtract the area to the left of z=1.72 from the total area under the curve.
The total area under the standard normal curve is equal to 1. Given that the area to the left of z=1.72 is 0.0427, follow these steps:
Subtract the area to the left of z=1.72 from the total area:
1 - 0.0427 = 0.9573
The area under the standard normal curve to the right of z=1.72 is 0.9573, which corresponds to option A.
Know more about area under the curve here:
https://brainly.com/question/30465469
#SPJ11
Determine the next three numbers in this arithmetic sequence: 8, 13, 18, 23
Answers
Answer:
28, 33, 38
Step-by-step explanation:
You can see from the first 4 numbers that it is increasing by 5, so the next 3 numbers would be:
28, 33, 38
How do you find eigenvalues and eigenvectors of a matrix?
Answers
Identifying Eigenvalues and Eigenvectors, A should be a n x n matrix. By resolving the det(λI−A)=0 problem, first determine the eigenvalues of A. Find the fundamental solutions to (λI−A)X=0 to determine the fundamental eigenvectors X≠0 for each.
In linear algebra, a nonzero vector is said to have an eigenvector, or characteristic vector, when a linear transformation is applied to it; this characteristic vector only changes by a scalar amount. The scaling factor for the eigenvector is known as the associated eigenvalue, frequently represented by the symbol. Linear transformations are made intelligible by the usage of eigenvectors. Eigenvectors can be thought of as a non-directional stretching or compressing of an X-Y line chart. In mathematics, eigenvalues are regarded as the factor by which a transformation is stretched, whereas eigenvectors are the real non-zero eigenvalues that point in the direction stretched by the transformation. The direction of the transformation is negative if the eigenvalue is negative.
To know more about Eigenvectors here
https://brainly.com/question/15423383
#SPJ4
Which statements are true? Check all that apply
Answers
What is the scale of the y-axis in this coordinate graph?
A. 1 tick mark represents 1 unit
B. 1 tick mark represents 8 units
C. 1 tick mark represents 12 units
D. 1 tick mark represents 16 units
Answers
Answer:
Obviously B
Step-by-step explanation:
you are dealt one card from a standard 52-card deck. playing cards find the probability of being dealt a three and an ace. the probability of being dealt a three and an ace is . (type an integer or a fraction.)
Answers
The probability of getting an ace and a three is (4/52) × (3/51) = 12/2652 which simplifies to 1/221.
There are 4 aces and 4 threes in a deck of 52 standard cards.
The probability of getting an ace on your first draw is 4/52.
Once you have the ace, there are 51 cards left in the deck, 3 of which are threes.
Therefore, the probability of drawing a three is 3/51.
Learn more about Probability
brainly.com/question/30881224
#SPJ11
solve 9x - y = 45 for y
Answers
Answer:
y=9x-45
Step-by-step explanation:
9x-y=45
-y=45-9x
y=9x-45
The scale on a map is 5 cm: 8 km.
If the distance between two cities is 68 km, how far apart in cm are the two cities on the map?
cm
Answers
Because for every 8km there 5cm
$74 dollars for 6 hours. what is hourly payrate of dollars per hour
Answers
Answer:
$12.33
Step-by-step explanation:
74/6 = 12.33
Answer:
12.3
Step-by-step explanation:
I hope this is right!
solve the equation 4x^3 + 32x^2 + 42x - 16 = 0, given that one root is equal to the sum of the other two roots
Answers
The solutions to the equation are x = -1, x = -8, and x = 1/2.
How to calculate the valueThe equation 4x³ + 32x² + 42x - 16 = 0 can be divided throuh by 2 as follows:
2x³ + 16x² + 21x - 8 = 0
We can test each of these possible roots by substituting them into the equation and seeing if we get 0. When we substitute -1, we get 0, so -1 is a root of the equation. We can then factor out (x + 1) from the equation to get:
(x + 1)(2x² + 15x - 8) = 0
We can then factor the quadratic 2x² + 15x - 8 by grouping to get:
(x + 8)(2x - 1) = 0
This gives us two more roots, x = -8 and x = 1/2.
Therefore, the solutions to the equation are x = -1, x = -8, and x = 1/2.
Learn more about equations on
https://brainly.com/question/2972832
#SPJ1