1- Find a reduction formula and indicate the base integrals for the following integrals: integral[ tan^n x] dx
Answers
The base integrals are:
For n=1 : integral[tan(x)dx]= ln|cos(x)| + C
For n=2 : integral[tan^2(x)dx]= -tan(x) - ln|cos(x)| + C
For n=3 : integral[tan^3(x)dx]= - ln|cos(x)| - tan(x) - (tan(x))^3/3 + C
For n=4 : integral[tan^4(x)dx]= tan(x) + (2/3)tan^3(x) - ln|cos(x)| + C
Reduction formula is utilized for decreasing the power of a function by one to make it less complex. When the integrand is a power of a trigonometric function, the technique of reduction formula is used.
For finding the reduction formula and base integrals for the following integrals:
integral[ tan^n x] dx, we follow these steps:
We know that the integral of tan x is -ln|cos x| + C.
For finding the integral of tan^2 x, we differentiate the integral of tan x and multiply it by -1 as shown below:
integral[tan^2x]dx
=integral[tan^2x.tan^2x/cos^2x]dx
=integral[tan^2x.sec^2x-1/cos^2x]dx
Now, we can solve the integral of tan^2x.sec^2x by u-substitution.
u = tan x and du = sec^2xdx
integral[tan^2x.sec^2x-1/cos^2x]dx
=integral[u^2-1/u^2]du=(-u - 1/u)+C
=-tan x - sec x + C
To find the integral of tan^3x we will use the formula:
integral[tan^3x.dx]
=integral[tan^2x.tanx.dx]
=integral[tan^2x.(sec^2x-1)dx]
By substituting
u = tan x we have:
-integral[(u^2-1)du/u^2]
=-integral[1/u^2]du + integral[du]-integral[1/u^2]du+integral[du]
=(-1/u) - ln|cos x| + C
Finally, for the integral of tan^4 x, we get:
integral[tan^4x.dx]=integral[tan^3x.tanx.dx]
=integral[tan^3x.(sec^2x-1)dx]
By substituting u = tan x we have:
integral[(u^2-1)tan(u)du/u^2]
=integral[(u^2-1)du/u^2]-integral[(u^2-1)/u^2.du]
=(-1/u) - ln|cos x| + (1/3)tan^3x+C.
The base integrals are:
For n=1 : integral[tan(x)dx]= ln|cos(x)| + C
For n=2 : integral[tan^2(x)dx]= -tan(x) - ln|cos(x)| + C
For n=3 : integral[tan^3(x)dx]= - ln|cos(x)| - tan(x) - (tan(x))^3/3 + C
For n=4 : integral[tan^4(x)dx]= tan(x) + (2/3)tan^3(x) - ln|cos(x)| + C
To know more about trigonometric function visit:
https://brainly.com/question/25618616
#SPJ11
Related Questions
Which operation can you apply to the ratio 1 to 2 to get the ratio 3 to 6?

Answers
Answer:
x3
Step-by-step explanation:
Supongamos que un restaurante ofrece 5 entradas, 4 platos principales y 3 postres. ¿De
cuántas formas un cliente puede ordenar una comida?
Answers
Answer:
El cliente puede ordenar una comida en 60 formas distintas.
Step-by-step explanation:
El cliente escoge una entrada de las cinco opciones disponibles, luego un plato principal de cuatro opciones disponibles y un postre de tres opciones disponibles. Es costumbre consumir primero una entrada, después un plato principal y finalmente, un postre.
Estadísticamente hablando, se debe considerar un producto de tres combinaciones, puesto que el orden no importa a la hora de pedir, como sigue:
\(n = _{5}C_{1}\times _{4}C_{1}\times _{3}C_{1}\) (1)
Donde:
\(n\) - Total de combinaciones al ordenar una comida (entrada, plato principal, postre)
\(_{5}C_{1}\) - Combinaciones posibles para pedir una entrada.
\(_{4}C_{1}\) - Combinaciones posibles para pedir un plato principal.
\(_{3}C_{1}\) - Combinaciones posibles para pedir un postre.
Ahora, desarrollamos la operación:
\(n = \frac{5!}{(5-1)!}\times \frac{4!}{(4-1)!} \times \frac{3!}{(3-1)!}\)
\(n = 5\times 4\times 3\)
\(n = 60\)
El cliente puede ordenar una comida en 60 formas distintas.
Find the gradient vector field of f. f(x, y, z) = x cos 5y/z
Answers
So, the gradient vector field of f is (∇f) = (cos(5y/z), -5x sin(5y/z)/z, 5xy sin(5y/z)/z^2).
To find the gradient vector field of the function f(x, y, z) = x cos(5y/z), we need to calculate the partial derivatives with respect to each variable and combine them into a vector.
The gradient vector is defined as:
∇f = (∂f/∂x, ∂f/∂y, ∂f/∂z)
Taking the partial derivatives of f(x, y, z) with respect to each variable:
∂f/∂x = cos(5y/z)
∂f/∂y = -5x sin(5y/z)/z
∂f/∂z = 5xy sin(5y/z)/z^2
Putting these partial derivatives together, we have:
∇f = (cos(5y/z), -5x sin(5y/z)/z, 5xy sin(5y/z)/z^2)
To know more about gradient vector field,
https://brainly.com/question/30169142
#SPJ11
Each participant tastes snack A and snack B and them choses their favorite. Some participants have eaten snack A before and some have not. The results of the test are shown in the table. Using the data in a table, the company that makes snack A calculates probabilities related to a random selected person. Complete the conclusions based on the data on the table.
Given a person who has eaten snack A before, the customer will __.
Options:
Stay with snack A.
Change to snack B
Given a person who has not eaten snack A before, the customer will want to eat snack __.
Options: A or B
Table below:

Answers
The conditional probability values are 0.57 and 0.43
Missing information
Has Eaten before Have not Total
Snack A 144 108 252
Snack B 92 228 320
Total 236 336 572
Using the data in a table, the company that makes snack A calculates probabilities related to a random selected person.
Given a person who has eaten snack A before, the customer will want to eat snack A
Given a person who has not eaten snack A before, the customer will want to eat snack
How to determine the probabilities?
The required probabilities are conditional probabilities, and they are calculated using:
P(A | B) = P(A and B)/P(B)
Using the above formula, we have:
The probability that a customer eats snack A given that the customer has eaten snack A before, to be:
P = n(Have eaten snack A)/n(Snack A)
This gives
P = 144/252
Evaluate
P = 0.57
Also, we have:
The probability that a customer eats snack A given that the customer has not eaten snack A before, to be:
P = n(Have not eaten snack A)/n(Snack A)
This gives
P = 108/252
Evaluate
P = 0.43
Hence, the probabilities are 0.57 and 0.43
Learn more about probability at:
brainly.com/question/25870256
#SPJ1
help me for brainlist.

Answers
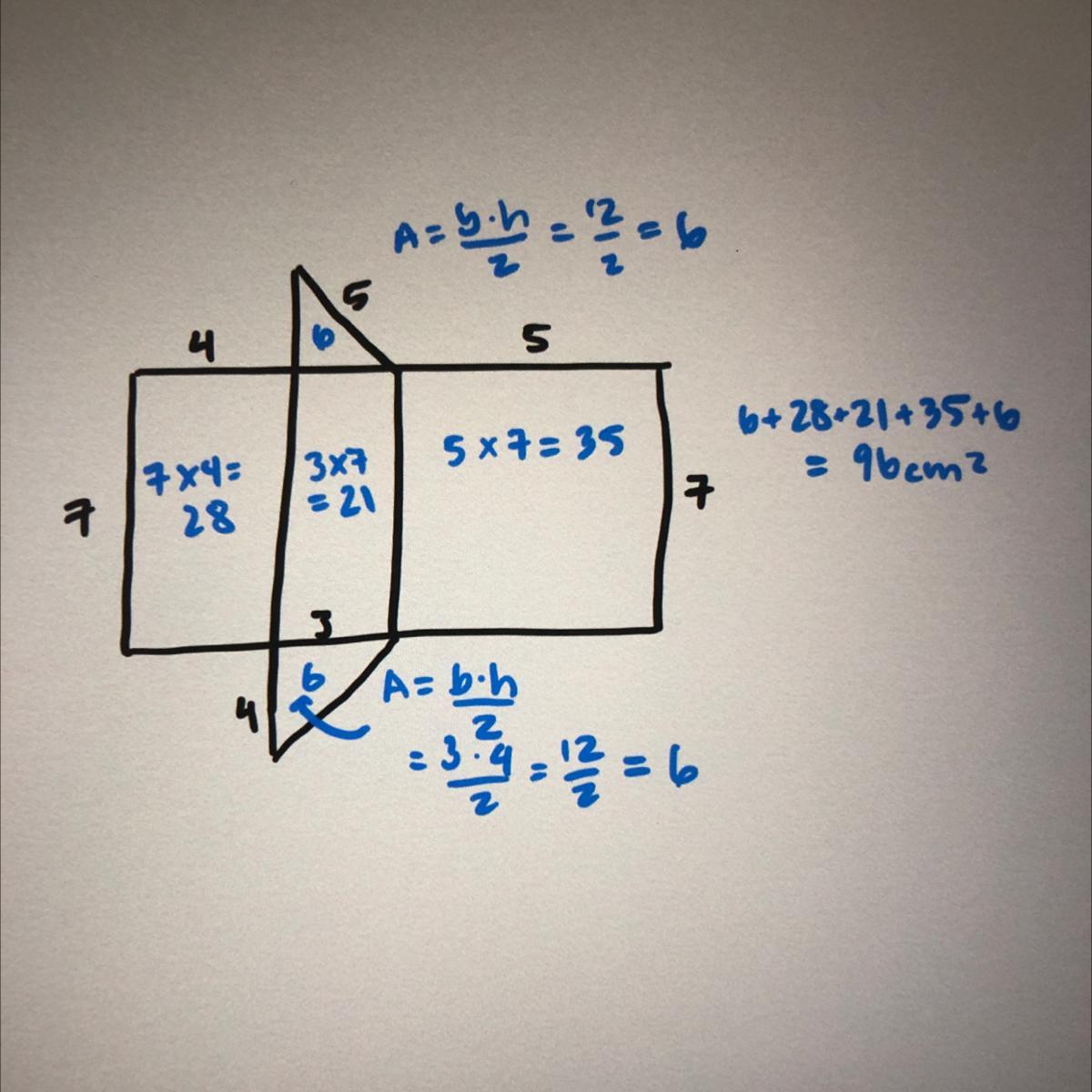
find the area of each rectangle and triangle
add them to get 96
according to rank size rule, what is the population of the 5th largest city within a region in which the largest city has 5,5 million people?
Answers
According to the Rank-Size Rule, the population of the 5th largest city in this region is estimated to be 1.1 million people.
The Rank-Size Rule states that the population of a city (n) in a region is proportional to the population of the largest city (P1) in that region, with a power of -1.
So, the population of the nth city in a region can be calculated using the formula:
Pn = P1 / n^1
So, for the 5th largest city in a region where the largest city has 5.5 million people, the population can be calculated as follows:
P5 = 5.5 million / 5^1 = 1.1 million
For more questions on Rank-Size Rule
https://brainly.com/question/3640384
#SPJ4
A kiddie pool holds miniature plastic ducks in different colors. Sophia randomly picks up a duck and then replaces it. She repeats this process 100 times. The table shows the results of her experiment.
Duck Color Times Picked
red 30
green 20
yellow 40
blue 10
What is the relative frequency of choosing a red duck? What color of duck is there likely to be the most of in the pool?
A.
The relative frequency is 0.3. It is likely that most ducks are blue.
B.
The relative frequency is 0.2. It is likely that most ducks are yellow.
C.
The relative frequency is 0.3. It is likely that most ducks are yellow.
D.
The relative frequency is 0.2. It is likely that most ducks are green.
Answers
Answer:
.3 and most ducks are yellow - so letter c.
Step-by-step explanation:
remember: the formula for relative frequency is f/n.
f = number of times data occurred for an observation (30 red ducks picked)
n - total frequencies (100 ducks picked in total)
30/100 = 0.3 is the relative frequency of choosing a red duck.
Next,
Yellow was picked 40 out of the 100 times, so its likely that most ducks are yellow.
Answer:
C. The relative frequency is 0.3. It is likely that most ducks are yellow.
Step-by-step explanation:
Relative frequency (or experimental probability) is calculated by dividing the recorded number of times an event happens by the total number of trials in the actual experiment.
\(\begin{aligned}\implies \sf Relative\:frequency\:(red\:duck) & = \dfrac{\textsf{Number of times a red duck was picked}}{\textsf{Total number of trials}}\\\\ & = \sf \dfrac{30}{100}\\\\ & = \sf 0.3\end{aligned}\)
The most likely color of duck in the pool is the color of duck with the highest frequency. Therefore, it is likely that most ducks are yellow.
The number of laps Katie ran was 2:3.If Louis ran 4 miles, how far did katie run?
Answers
Answer ran 2 3/4 miles in 1/3 of an hour
2 3/4 miles =11/4 miles in 1/3 of hour
11/4 miles divided by 1/3 hr
11/4 ÷ 1/3
11/4 * 3/1 =33/4 =8 1/4 miles in 1 hr
Seen previously.Four standard six-sided dice are to be rolled. What is the probability that the product of the numbers on the top faces will be prime
Answers
The probability that the product of the numbers on the top faces of four standard six-sided dice will be prime is approximately 0.09%.
To calculate this probability, a table can be created that outlines the 36 possible combinations of numbers on the top faces of four dice. From this table, the number of prime products can be determined. As there are only three primes (2, 3, and 5) in the 36 possible products, the probability of rolling a prime product is 3/36, which is approximately 0.09%. This means that the probability of rolling a prime product on four standard six-sided dice is very low, approximately 0.09%.
Learn more about Probability here:
https://brainly.com/question/13604758
#SPJ4
Which properly illustrated in the statement (-2)(+5) = (+5)(-2)?
Answers
Answer: 7
Step-by-step explanation:
it is trust me.
You want to compute a 90% confidence interval for the mean of a population with unknown population standard deviation. The sample size is 30. The value of t* you would use for this interval is Group of answer choices 1.645
Answers
Yes, the cost of t* you would use for a 90% self-belief interval with a pattern length of 30 is 1.645.
To compute a 90% self-belief c programming language for the mean of a population with an unknown population well-known deviation, you would use the t-distribution. The vital fee, denoted as t*, is primarily based on the preferred self-assurance stage and the degrees of freedom, that's the same as the sample size minus 1 (n - 1).
In this situation, the pattern size is 30, so the tiers of freedom are 30 - 1 = 29. To locate an appropriate fee of t* for a 90% confidence stage, you could talk to the t-distribution table or use a statistical software program.
For a 90% confidence level and 29 tiers of freedom, the price of t* is approximately 1.645. This approach that 90% of the t-distribution falls inside ±1.645 trendy deviations from the suggestion.
Using this cost of t*, you can compute the confidence c language by taking the sample suggested and including/subtracting the margin of mistakes, which is fabricated from t* and the same old errors of the mean.
Remember that the t* cost may additionally vary slightly depending on the level of precision required and the precise table or software used, however, 1.645 is a normally used approximation for a 90% self-assurance c program language period with a sample size of 30.
To know more about standard deviation,
https://brainly.com/question/30778896
#SPJ4
The correct question is:
"You want to compute a 90% confidence interval for the mean of a population with unknown population standard deviation. The sample size is 30. Is the value of t* you would use for this interval is Group of answer choices 1.645?"
please answer this!!

Answers
Answer:
You can not solve it because Side P does not exist
Step-by-step explanation:
Britany is bringing birthday cake and cookies to her office. She has already spent $10.00 on the cake. Cookies cost $0.70 each, and she does not wish to spend more than $34.50 for all desserts. If x represents the number of cookies she can buy, which of the following inequalities symbolizes this situation?
A.
$10.00x + $0.70 < $34.50
B.
$0.70x + $10.00 < $34.50
C.
$0.70x + $10.00 < $34.50
D.
$10.00x + $0.70 < $34.50
Answers
Considering the definition of an inequality, the correct answer is option C. the inequiality $0.70x + $10.00 < $34.50 symbolize this situation
Definition of inequalityAn inequality is the existing inequality between two algebraic expressions, connected through the signs:
greater than >.less than <.less than or equal to ≤.greater than or equal to ≥.The solution of an inequality is the set of numbers that make the inequality true.
Inequality in this caseIn this case, you know that:
Britany has already spent $10.00 on the cake. Cookies cost $0.70 each. She does not wish to spend more than $34.50 for all desserts.Being "x" the number of cookies Britany can buy, the inequality that expresses the previous relationship is
10 + 0.70x <34.50
Learn more about inequality:
brainly.com/question/4319715
#SPJ1
Please help on this thanks
Answers
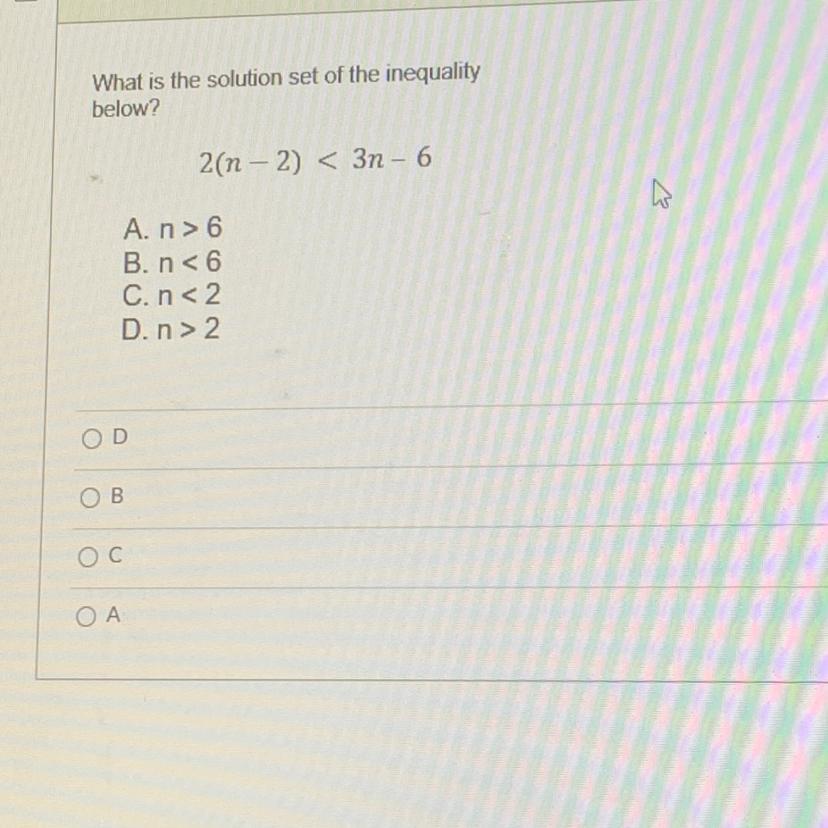
2n < 3n - 2
-n < - 2
n > 2
The answer would be D
\(2(n-2)<3n-6\)
↝ Multiply 2 inside (n-2) as we get 2n-4
\(2n-4<3n-6\)
↝ Inequality is almost the same as equation so you just do the same like equation.
\(2n-4-3n+6<0\\-n+2<0\\-n<-2\)
↝ Since it's Inequality. When the variable is negative, you have to make it positive.
\(n<\frac{-2}{-1}\\n<2\)
↝ BUT! n < 2 isn't the right answer.
↝ Because for Inequality. Taking out the negative/Move the negative variable to another side ( from -n to n and -2 to -2/-1 = 2).
↝ You have to swap the inequality symbol after taking the off the negative variable.
↝ For example, if it is -n < 2 then the answer will be n > -2
or -n < -3 then the answer will be n > 3
But if it is n>2-3 as we get n>-1, not n < -1 because the variable isn't negative at all.
Basically, we swap the inequality symbol when it's negative variable.
↝ Therefore, it's not n < 2 but it is n > 2
So the right choice is n > 2 also known as the ( D ) answer.
popular magazine tests cars and trucks for mileage on the road and around the city. the magazine reports that 50% of the cars tested had mileages below 24.7 mpg on the road, and the other 50% of the cars tested had mileages above 24.7 mpg. which statistic does this 24.7 represent? question 9 options: the interquartile range (iqr) of the gas mileages for the cars tested. the mode of the gas mileages for the cars tested. the median of the gas mileages for the cars tested. the mean of the gas mileages for the cars tested.
Answers
The statistic that the value 24.7 represents in this context is the median of the gas mileages for the cars tested.
Popular magazine that tests cars and trucks for mileage on the road and around the city. They report that 50% of the cars tested had mileages below 24.7 mpg on the road, and the other 50% had mileages above 24.7 mpg. The 24.7 mpg statistic represents the median of the gas mileages for the cars tested. This is because the median is the middle value when the data is arranged in ascending order, and in this case, it separates the lower 50% from the upper 50% of the mileages.
The median is the value that separates the data set into two halves. In this case, the magazine reports that 50% of the cars tested had mileages below 24.7 mpg on the road and the other 50% of the cars tested had mileages above 24.7 mpg. This means that 24.7 mpg is the exact middle value of the distribution of the gas mileages for the cars tested.
Learn more about "median ":
https://brainly.com/question/26177250
#SPJ11
What is halfway between 4/9 and 1/7
Please hurry!
Answers
Answer:
55/126
Step-by-step explanation:
(3/7)x(9/9)=27/63
(4/9)x(7/7)=28/63
(27/63)x(2/2)=54/126
(28/63)x(2/2)=56/126
1. Which of the following is not a linear equation in one variable?
a) 33
b) 33(x+y)
c) 33x
d) 33y
Answers
\( \huge \boxed{\mathbb{QUESTION} \downarrow}\)
Which of the following is not a linear equation in one variable?
a) 33
b) 33(x+y)
c) 33x
d) 33y
\( \large \boxed{\mathfrak{Answer \: with \: Explanation} \downarrow}\)
Option b) 33 (x + y) is not a linear equation in 1 variable.Here, we can see that there are 2 variables used ⇨ x & y. Hence, even though it's a linear equation, it's not in 1 variable. All the other options are in 1 variable or don't have a variable at all.classify the following random variables as Discrete or Continuous
1Shoe size
2foot length
3Students in a class
4distance travelled to school
5children per family
6the height of a horse
7the number of TV sets in a home
8time to complete a task
9the outdoor temperature at noon
10the speed of a car on route 3
Answers
1 discrete
2 continuous
3 discrete
4 continuous
5 discrete
6 continuous
7 discrete
8 continuous
9 continuous
10 continuous
2. The diameter of Earth is approximately 8,000 miles. What would the diameter of Earth be in your scale model?
Answers
The diameter of the moon is approximately 2,000 miles.
Explanation:
First, because we are solving for the approximate diameter of the moon, let's call the variable representing the diameter of the moon m.
Using the midpoint method, what is the price elasticity of supply between point B and point C? a. 1.44 b. 1.29 c. 0.96 d. 0.78
Answers
Answer:
The price elasticity of demand, when using the midpoint formula, would be B.1.29.
How to find the price elasticity of demand ?
Price elasticity of demand = ((Q2 - Q1) / ((Q2 + Q1) / 2)) / ((P2 - P1) / ((P2 + P1) / 2))
where:
Q1 = initial quantity demanded = 20 units
Q2 = final quantity demanded = 15 units
P1 = initial price = $8
P2 = final price = $10
Substituting the values:
Price elasticity of demand = ((15 - 20) / ((15 + 20) / 2)) / (($10 - $8) / (($10 + $8) / 2))
= (-5 / 17.5) / (2 / 9)
= (-0.2857) / (0.2222)
= -1.2857
= 1. 29
Query: for each project, retrieve its name if it has an employee working more than 15 hours on it Write your solution on paper and make sure of the foring - Your writing must be clear and easy to read
Answers
To retrieve the names of projects with an employee working more than 15 hours, you can use the following SQL query:
SELECT project.name FROM project
JOIN assignment ON project.id = assignment.project_id
JOIN employee ON assignment.employee_id = employee.id
WHERE assignment.hours > 15;
The query uses the SELECT statement to retrieve the name column from the project table. It performs joins with the assignment and employee tables using the appropriate foreign keys (project.id, assignment.project_id, assignment.employee_id, and employee.id). The JOIN keyword is used to combine the tables based on their relationships.
The WHERE clause specifies the condition assignment.hours > 15 to filter the assignments where an employee has worked more than 15 hours. Only the projects meeting this condition will be included in the result.
By executing this query, you will retrieve the names of projects that have at least one employee working more than 15 hours on them.
To learn more about foreign keys
brainly.com/question/31766433
#SPJ11
Consider the following hypothesis test: H0: p ? .75 Ha: p < .75 A sample of 300 items was selected. Compute the p-value and state your conclusion for each of the following sample results. Use ? = .05. Round your answers to four decimal places.
a. p = .68 p-value? Conclusion: p-value H0?
b. p = .72 p-value? Conclusion: p-value H0 ?
c. p = .70 p-value? Conclusion: p-value H0 ?
d. p = .77 p-value? Conclusion: p-value H0?
Answers
For each given sample result, the p-value and conclusion are as follows:
a. p-value = 0.0067, Conclusion: Reject H0, b. p-value = 0.0830, Conclusion: Fail to reject H0, c. p-value = 0.0322, Conclusion: Reject H0
d. p-value = 0.6221, Conclusion: Fail to reject H0
The p-value is a measure of the evidence against the null hypothesis (H0). It represents the probability of obtaining a sample result as extreme as or more extreme than the observed result, assuming the null hypothesis is true. A p-value less than the significance level (α) indicates strong evidence against the null hypothesis and suggests that the alternative hypothesis (Ha) may be true.
a. For p = .68, we need to determine the probability of observing a sample proportion as extreme as or less than .68, assuming the null hypothesis is true. By conducting the appropriate statistical test (e.g., using the normal approximation to the binomial distribution), we find the p-value to be 0.0067. Since the p-value is less than α = .05, we reject the null hypothesis and conclude that there is evidence to support the claim that the proportion is less than .75.
b. For p = .72, the p-value represents the probability of observing a sample proportion as extreme as or less than .72. Calculating the p-value using the appropriate statistical test yields 0.0830. Since the p-value is greater than α = .05, we fail to reject the null hypothesis. Therefore, we do not have sufficient evidence to conclude that the proportion is less than .75.
c. With p = .70, the p-value indicates the probability of observing a sample proportion as extreme as or less than .70. The calculated p-value is 0.0322. As the p-value is less than α = .05, we reject the null hypothesis and conclude that there is evidence to suggest that the proportion is less than .75.
d. For p = .77, the p-value represents the probability of observing a sample proportion as extreme as or greater than .77. After performing the necessary calculations, we find the p-value to be 0.6221. Since the p-value is much greater than α = .05, we fail to reject the null hypothesis. Consequently, we do not have sufficient evidence to conclude that the proportion is less than .75.
Learn more about statistical here: https://brainly.com/question/29000275
#SPJ11
g(x) = x² - 4x²+x+6
Answers
The simplified expression of g(x) = x² - 4x² + x + 6 is g(x) = -3x² + x + 6
How to evaluate the expressionFrom the question, we have the following parameters that can be used in our computation:
g(x) = x² - 4x²+x+6
Rewrite properly
So, we have the following representation
g(x) = x² - 4x² + x + 6
Evaluate the like terms
g(x) = -3x² + x + 6
The above expression cannot be further simplified
Hence, the solution is g(x) = -3x² + x + 6
Read more about expressions at
https://brainly.com/question/15775046
#SPJ1
hi can you please help me, please

Answers
1. Remote interior angles of ∠RPQ are: ∠PRQ and ∠RQP.
2. ∠RPS
3. ∠RPS, ∠QPV, and ∠QRU.
4. ∠RPS = ∠QPV [vertical angles]
5. ∠RPS + ∠RPQ = 180° [linear pair]
What are Remote Interior Angles of an Exterior Angle in a Triangle?The remote interior angles to an exterior angle in a triangle are angles that lie directly opposite the exterior angle of the triangle and do not share a vertex or corner of a triangle with the exterior angle.
1. Remote interior angles of ∠RPQ are: ∠PRQ and ∠RQP.
2. ∠RPS is an exterior angle that has ∠PRQ and ∠RQP as its remote interior angles.
3. Exterior angles of the triangle are: ∠RPS, ∠QPV, and ∠QRU.
4. ∠RPS = ∠QPV [vertical angles]
5. ∠RPS + ∠RPQ = 180° [linear pair]
Learn more about remote interior angles on:
https://brainly.com/question/2638190
#SPJ1
We say a definite integral is improper if? 1. one ____ is infinite, or if 2. the ____ is infinite.
Answers
A definite integral is an integral of a function over a closed interval. An improper integral is a definite integral that has at least one of its limits of integration set at infinity or an interval of integration that is infinite.
This can happen when the domain of the function is infinite or when one of the limits of integration is infinite. In this case, the integral can either diverge (no finite answer) or it may converge to a finite value. In either case, it is an improper integral.
A definite integral is an integral of a function over a closed interval, taking the form of the definite integral: ∫ a b f(x)dx. This means that the function is integrated from the lower limit of “a” to the upper limit “b”. An improper integral is a definite integral where either one of the limits of integration is set at infinity or the interval of integration is infinite. This can happen when the domain of the function is infinite, meaning that the function exists and is defined for all real numbers, or when one of the limits of integration is infinite. In this case, the integral can either diverge (no finite answer) or it may converge to a finite value. In either case, it is an improper integral, and it must be treated differently than a regular definite integral.
learn more about function here
https://brainly.com/question/12431044
#SPJ4
what is the value of r if 3r =243
Answers
Answer:
Making r the subject
r=243/3 = 81.
3r = 243
r = 243/3
r= 81
hope it helps you ♡♡
Can somebody help me with this question, my brain has evaporated.

Answers
Answer:
9.42m
Step-by-step explanation:
You have to find the circumference using C=2πR. We know that the radius =4 meters so then we can insert it into the formula to get the circumference which equals 8π. Then we divide 24m² by 8πm and get 9.42m.
what is the correlation

Answers
Answer: moderate, C, B
Step-by-step explanation:
A) A shows a moderate negative correlation. It is moderate because the scattered points are sort of close to the line so it has moderate/medium correlation. It is also negative because it has a negative slope
B) C shows the strongest correlation because the points around the line are tight and close.
C) B should not have been drawn. The correlation is very weak. You do know where the line should be because the points are all over the place.
help me please please today

Answers
a) Function f(x) = 2^x is an exponential growth function because a = 2 is greater than 0 and b = 2 is greater than 1. The graph of the function starts at (0,1) and increases rapidly as x increases.
b) Function f(x) = (1/2)^x is an exponential decay function because a = 1/2 is greater than 0 and b = 1/2 is between 0 and 1. The graph of the function starts at (0,1) and decreases rapidly as x increases.
What are the key features of both graphs?Key features of both graphs:
x-intercept: There is no x-intercept for either function.y-intercept: The y-intercept for both functions is (0,1).Domain: The domain of both functions is all real numbers.Range: The range of f(x) = 2^x is all positive real numbers, while the range of f(x) = (1/2)^x is all positive numbers between 0 and 1.Asymptote: The x-axis is a horizontal asymptote for both functions.Growth/decay factor: The growth/decay factor for f(x) = 2^x is 2, while the growth/decay factor for f(x) = (1/2)^x is 1/2.Learn more about exponential growth function at:
https://brainly.com/question/11487261
#SPJ1

if i need 3 cups of flour for 2 cups of penuts how much flour do i need for 5 cups of penuts
Answers
4 - 3
5 - 4
so it would be 6 - 5